 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAS: A Decision-Theoretic Approach to Evaluating Large Language Model Confidence
Apr 03, 2026Large language models (LLMs) often produce confident but incorrect answers in settings where abstention would be safer. Standard evaluation protocols, however, require a response and do not account for how confidence should guide decisions under different risk preferences. To address this gap, we introduce the Behavioral Alignment Score (BAS), a decision-theoretic metric for evaluating how well LLM confidence supports abstention-aware decision making. BAS is derived from an explicit answer-or-abstain utility model and aggregates realized utility across a continuum of risk thresholds, yielding a measure of decision-level reliability that depends on both the magnitude and ordering of confidence. We show theoretically that truthful confidence estimates uniquely maximize expected BAS utility, linking calibration to decision-optimal behavior. BAS is related to proper scoring rules such as log loss, but differs structurally: log loss penalizes underconfidence and overconfidence symmetrically, whereas BAS imposes an asymmetric penalty that strongly prioritizes avoiding overconfident errors. Using BAS alongside widely used metrics such as ECE and AURC, we then construct a benchmark of self-reported confidence reliability across multiple LLMs and tasks. Our results reveal substantial variation in decision-useful confidence, and while larger and more accurate models tend to achieve higher BAS, even frontier models remain prone to severe overconfidence. Importantly, models with similar ECE or AURC can exhibit very different BAS due to highly overconfident errors, highlighting limitations of standard metrics. We further show that simple interventions, such as top-$k$ confidence elicitation and post-hoc calibration, can meaningfully improve confidence reliability. Overall, our work provides both a principled metric and a comprehensive benchmark for evaluating LLM confidence reliability.
Entropy Alone is Insufficient for Safe Selective Prediction in LLMs
Mar 22, 2026Selective prediction systems can mitigate harms resulting from language model hallucinations by abstaining from answering in high-risk cases. Uncertainty quantification techniques are often employed to identify such cases, but are rarely evaluated in the context of the wider selective prediction policy and its ability to operate at low target error rates. We identify a model-dependent failure mode of entropy-based uncertainty methods that leads to unreliable abstention behaviour, and address it by combining entropy scores with a correctness probe signal. We find that across three QA benchmarks (TriviaQA, BioASQ, MedicalQA) and four model families, the combined score generally improves both the risk--coverage trade-off and calibration performance relative to entropy-only baselines. Our results highlight the importance of deployment-facing evaluation of uncertainty methods, using metrics that directly reflect whether a system can be trusted to operate at a stated risk level.
SignalMC-MED: A Multimodal Benchmark for Evaluating Biosignal Foundation Models on Single-Lead ECG and PPG
Mar 10, 2026Recent biosignal foundation models (FMs) have demonstrated promising performance across diverse clinical prediction tasks, yet systematic evaluation on long-duration multimodal data remains limited. We introduce SignalMC-MED, a benchmark for evaluating biosignal FMs on synchronized single-lead electrocardiogram (ECG) and photoplethysmogram (PPG) data. Derived from the MC-MED dataset, SignalMC-MED comprises 22,256 visits with 10-minute overlapping ECG and PPG signals, and includes 20 clinically relevant tasks spanning prediction of demographics, emergency department disposition, laboratory value regression, and detection of prior ICD-10 diagnoses. Using this benchmark, we perform a systematic evaluation of representative time-series and biosignal FMs across ECG-only, PPG-only, and ECG + PPG settings. We find that domain-specific biosignal FMs consistently outperform general time-series models, and that multimodal ECG + PPG fusion yields robust improvements over unimodal inputs. Moreover, using the full 10-minute signal consistently outperforms shorter segments, and larger model variants do not reliably outperform smaller ones. Hand-crafted ECG domain features provide a strong baseline and offer complementary value when combined with learned FM representations. Together, these results establish SignalMC-MED as a standardized benchmark and provide practical guidance for evaluating and deploying biosignal FMs.
Scanner-Induced Domain Shifts Undermine the Robustness of Pathology Foundation Models
Jan 07, 2026Pathology foundation models (PFMs) have become central to computational pathology, aiming to offer general encoders for feature extraction from whole-slide images (WSIs). Despite strong benchmark performance, PFM robustness to real-world technical domain shifts, such as variability from whole-slide scanner devices, remains poorly understood. We systematically evaluated the robustness of 14 PFMs to scanner-induced variability, including state-of-the-art models, earlier self-supervised models, and a baseline trained on natural images. Using a multiscanner dataset of 384 breast cancer WSIs scanned on five devices, we isolated scanner effects independently from biological and laboratory confounders. Robustness is assessed via complementary unsupervised embedding analyses and a set of clinicopathological supervised prediction tasks. Our results demonstrate that current PFMs are not invariant to scanner-induced domain shifts. Most models encode pronounced scanner-specific variability in their embedding spaces. While AUC often remains stable, this masks a critical failure mode: scanner variability systematically alters the embedding space and impacts calibration of downstream model predictions, resulting in scanner-dependent bias that can impact reliability in clinical use cases. We further show that robustness is not a simple function of training data scale, model size, or model recency. None of the models provided reliable robustness against scanner-induced variability. While the models trained on the most diverse data, here represented by vision-language models, appear to have an advantage with respect to robustness, they underperformed on downstream supervised tasks. We conclude that development and evaluation of PFMs requires moving beyond accuracy-centric benchmarks toward explicit evaluation and optimisation of embedding stability and calibration under realistic acquisition variability.
Forward-only Diffusion Probabilistic Models
May 22, 2025This work presents a forward-only diffusion (FoD) approach for generative modelling. In contrast to traditional diffusion models that rely on a coupled forward-backward diffusion scheme, FoD directly learns data generation through a single forward diffusion process, yielding a simple yet efficient generative framework. The core of FoD is a state-dependent linear stochastic differential equation that involves a mean-reverting term in both the drift and diffusion functions. This mean-reversion property guarantees the convergence to clean data, naturally simulating a stochastic interpolation between source and target distributions. More importantly, FoD is analytically tractable and is trained using a simple stochastic flow matching objective, enabling a few-step non-Markov chain sampling during inference. The proposed FoD model, despite its simplicity, achieves competitive performance on various image-conditioned (e.g., image restoration) and unconditional generation tasks, demonstrating its effectiveness in generative modelling. Our code is available at https://github.com/Algolzw/FoD.
Evaluating Computational Pathology Foundation Models for Prostate Cancer Grading under Distribution Shifts
Oct 09, 2024



Foundation models have recently become a popular research direction within computational pathology. They are intended to be general-purpose feature extractors, promising to achieve good performance on a range of downstream tasks. Real-world pathology image data does however exhibit considerable variability. Foundation models should be robust to these variations and other distribution shifts which might be encountered in practice. We evaluate two computational pathology foundation models: UNI (trained on more than 100,000 whole-slide images) and CONCH (trained on more than 1.1 million image-caption pairs), by utilizing them as feature extractors within prostate cancer grading models. We find that while UNI and CONCH perform well relative to baselines, the absolute performance can still be far from satisfactory in certain settings. The fact that foundation models have been trained on large and varied datasets does not guarantee that downstream models always will be robust to common distribution shifts.
Evaluating Deep Regression Models for WSI-Based Gene-Expression Prediction
Oct 01, 2024Prediction of mRNA gene-expression profiles directly from routine whole-slide images (WSIs) using deep learning models could potentially offer cost-effective and widely accessible molecular phenotyping. While such WSI-based gene-expression prediction models have recently emerged within computational pathology, the high-dimensional nature of the corresponding regression problem offers numerous design choices which remain to be analyzed in detail. This study provides recommendations on how deep regression models should be trained for WSI-based gene-expression prediction. For example, we conclude that training a single model to simultaneously regress all 20530 genes is a computationally efficient yet very strong baseline.
Taming Diffusion Models for Image Restoration: A Review
Sep 16, 2024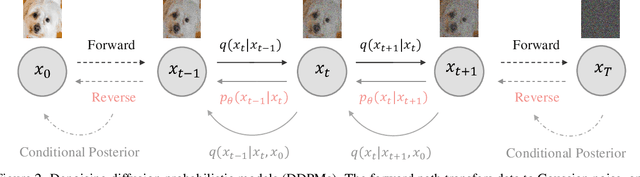
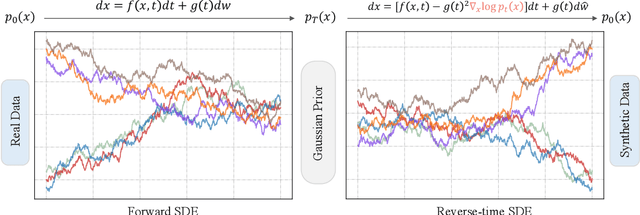
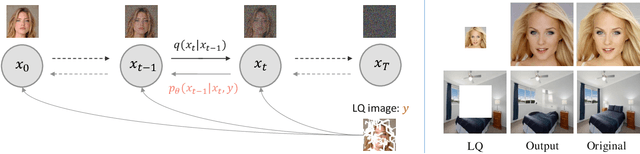
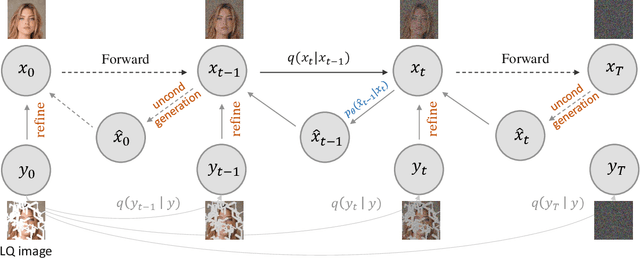
Diffusion models have achieved remarkable progress in generative modelling, particularly in enhancing image quality to conform to human preferences. Recently, these models have also been applied to low-level computer vision for photo-realistic image restoration (IR) in tasks such as image denoising, deblurring, dehazing, etc. In this review paper, we introduce key constructions in diffusion models and survey contemporary techniques that make use of diffusion models in solving general IR tasks. Furthermore, we point out the main challenges and limitations of existing diffusion-based IR frameworks and provide potential directions for future work.
Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models
Apr 15, 2024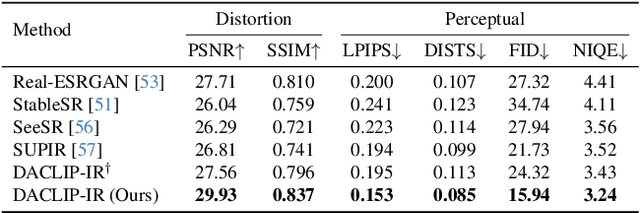

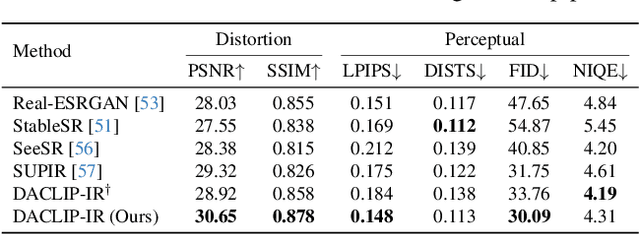

Though diffusion models have been successfully applied to various image restoration (IR) tasks, their performance is sensitive to the choice of training datasets. Typically, diffusion models trained in specific datasets fail to recover images that have out-of-distribution degradations. To address this problem, this work leverages a capable vision-language model and a synthetic degradation pipeline to learn image restoration in the wild (wild IR). More specifically, all low-quality images are simulated with a synthetic degradation pipeline that contains multiple common degradations such as blur, resize, noise, and JPEG compression. Then we introduce robust training for a degradation-aware CLIP model to extract enriched image content features to assist high-quality image restoration. Our base diffusion model is the image restoration SDE (IR-SDE). Built upon it, we further present a posterior sampling strategy for fast noise-free image generation. We evaluate our model on both synthetic and real-world degradation datasets. Moreover, experiments on the unified image restoration task illustrate that the proposed posterior sampling improves image generation quality for various degradations.
Controlling Vision-Language Models for Universal Image Restoration
Oct 02, 2023



Vision-language models such as CLIP have shown great impact on diverse downstream tasks for zero-shot or label-free predictions. However, when it comes to low-level vision such as image restoration their performance deteriorates dramatically due to corrupted inputs. In this paper, we present a degradation-aware vision-language model (DA-CLIP) to better transfer pretrained vision-language models to low-level vision tasks as a universal framework for image restoration. More specifically, DA-CLIP trains an additional controller that adapts the fixed CLIP image encoder to predict high-quality feature embeddings. By integrating the embedding into an image restoration network via cross-attention, we are able to pilot the model to learn a high-fidelity image reconstruction. The controller itself will also output a degradation feature that matches the real corruptions of the input, yielding a natural classifier for different degradation types. In addition, we construct a mixed degradation dataset with synthetic captions for DA-CLIP training. Our approach advances state-of-the-art performance on both degradation-specific and unified image restoration tasks, showing a promising direction of prompting image restoration with large-scale pretrained vision-language models. Our code is available at https://github.com/Algolzw/daclip-uir.