 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed neural posterior estimation for simulators with discrete and continuous parameters
May 13, 2026Neural Posterior Estimation (NPE) enables rapid parameter inference for complex simulators with intractable likelihoods. NPE trains an inference network to estimate a probability density over parameters given data, typically assumed to be \emph{continuous}. However, many scientific models involve parameter spaces that are \emph{mixed}, that is, they contain both discrete and continuous dimensions. We address this limitation by extending NPE to mixed parameter spaces through an inference network that jointly handles discrete and continuous parameters. The inference network factorizes the joint posterior into discrete and continuous components, combining an autoregressive classifier for the discrete parameters with a generative model for the continuous parameters, trained jointly under a single simulation-based objective. In addition, we propose a diagnostic tool to assess the calibration of the mixed posterior approximation. Across tractable toy examples and real-world scientific simulators, our joint inference approach yields accurate and calibrated posteriors. The inference framework is available in the \texttt{sbi} Python package.
Effortless, Simulation-Efficient Bayesian Inference using Tabular Foundation Models
Apr 24, 2025Simulation-based inference (SBI) offers a flexible and general approach to performing Bayesian inference: In SBI, a neural network is trained on synthetic data simulated from a model and used to rapidly infer posterior distributions for observed data. A key goal for SBI is to achieve accurate inference with as few simulations as possible, especially for expensive simulators. In this work, we address this challenge by repurposing recent probabilistic foundation models for tabular data: We show how tabular foundation models -- specifically TabPFN -- can be used as pre-trained autoregressive conditional density estimators for SBI. We propose Neural Posterior Estimation with Prior-data Fitted Networks (NPE-PF) and show that it is competitive with current SBI approaches in terms of accuracy for both benchmark tasks and two complex scientific inverse problems. Crucially, it often substantially outperforms them in terms of simulation efficiency, sometimes requiring orders of magnitude fewer simulations. NPE-PF eliminates the need for inference network selection, training, and hyperparameter tuning. We also show that it exhibits superior robustness to model misspecification and can be scaled to simulation budgets that exceed the context size limit of TabPFN. NPE-PF provides a new direction for SBI, where training-free, general-purpose inference models offer efficient, easy-to-use, and flexible solutions for a wide range of stochastic inverse problems.
End-to-end Risk Prediction of Atrial Fibrillation from the 12-Lead ECG by Deep Neural Networks
Sep 28, 2023



Background: Atrial fibrillation (AF) is one of the most common cardiac arrhythmias that affects millions of people each year worldwide and it is closely linked to increased risk of cardiovascular diseases such as stroke and heart failure. Machine learning methods have shown promising results in evaluating the risk of developing atrial fibrillation from the electrocardiogram. We aim to develop and evaluate one such algorithm on a large CODE dataset collected in Brazil. Results: The deep neural network model identified patients without indication of AF in the presented ECG but who will develop AF in the future with an AUC score of 0.845. From our survival model, we obtain that patients in the high-risk group (i.e. with the probability of a future AF case being greater than 0.7) are 50% more likely to develop AF within 40 weeks, while patients belonging to the minimal-risk group (i.e. with the probability of a future AF case being less than or equal to 0.1) have more than 85% chance of remaining AF free up until after seven years. Conclusion: We developed and validated a model for AF risk prediction. If applied in clinical practice, the model possesses the potential of providing valuable and useful information in decision-making and patient management processes.
* 16 pages with 7 figures
Invertible Kernel PCA with Random Fourier Features
Mar 09, 2023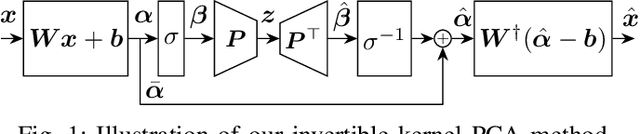
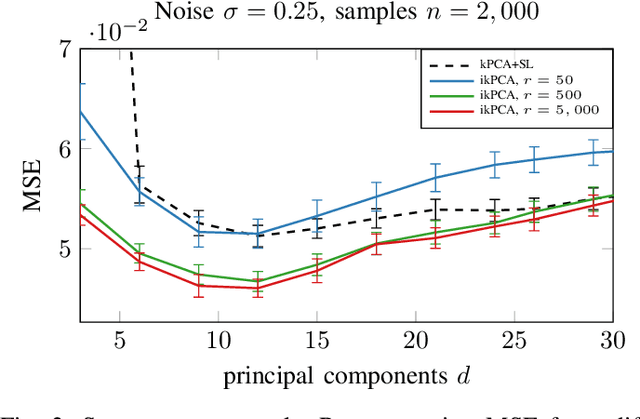
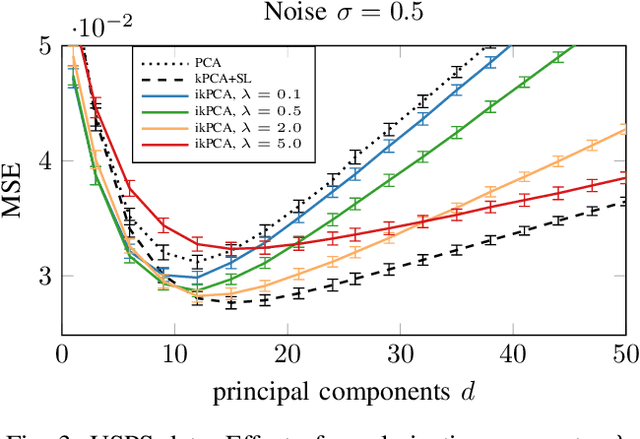
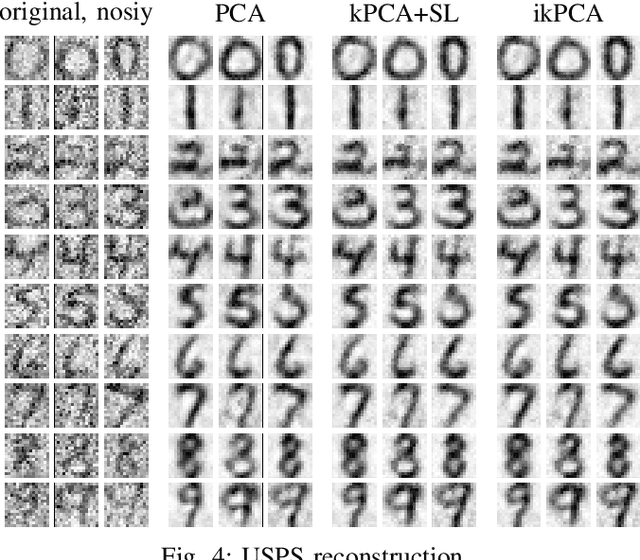
Kernel principal component analysis (kPCA) is a widely studied method to construct a low-dimensional data representation after a nonlinear transformation. The prevailing method to reconstruct the original input signal from kPCA -- an important task for denoising -- requires us to solve a supervised learning problem. In this paper, we present an alternative method where the reconstruction follows naturally from the compression step. We first approximate the kernel with random Fourier features. Then, we exploit the fact that the nonlinear transformation is invertible in a certain subdomain. Hence, the name \emph{invertible kernel PCA (ikPCA)}. We experiment with different data modalities and show that ikPCA performs similarly to kPCA with supervised reconstruction on denoising tasks, making it a strong alternative.
Deep networks for system identification: a Survey
Jan 30, 2023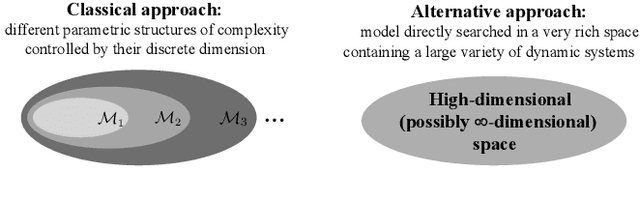
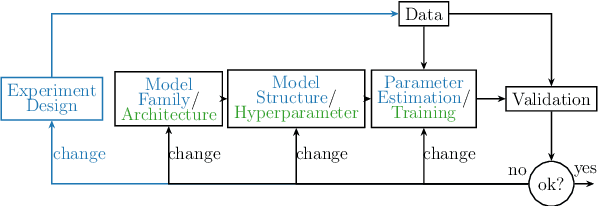
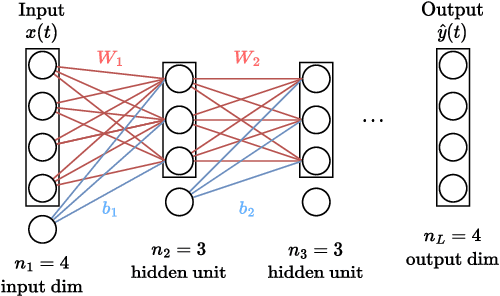
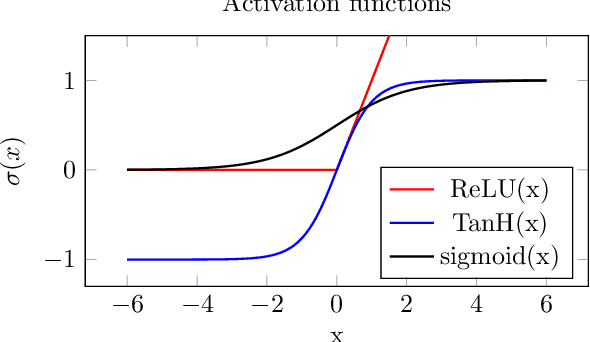
Deep learning is a topic of considerable current interest. The availability of massive data collections and powerful software resources has led to an impressive amount of results in many application areas that reveal essential but hidden properties of the observations. System identification learns mathematical descriptions of dynamic systems from input-output data and can thus benefit from the advances of deep neural networks to enrich the possible range of models to choose from. For this reason, we provide a survey of deep learning from a system identification perspective. We cover a wide spectrum of topics to enable researchers to understand the methods, providing rigorous practical and theoretical insights into the benefits and challenges of using them. The main aim of the identified model is to predict new data from previous observations. This can be achieved with different deep learning based modelling techniques and we discuss architectures commonly adopted in the literature, like feedforward, convolutional, and recurrent networks. Their parameters have to be estimated from past data trying to optimize the prediction performance. For this purpose, we discuss a specific set of first-order optimization tools that is emerged as efficient. The survey then draws connections to the well-studied area of kernel-based methods. They control the data fit by regularization terms that penalize models not in line with prior assumptions. We illustrate how to cast them in deep architectures to obtain deep kernel-based methods. The success of deep learning also resulted in surprising empirical observations, like the counter-intuitive behaviour of models with many parameters. We discuss the role of overparameterized models, including their connection to kernels, as well as implicit regularization mechanisms which affect generalization, specifically the interesting phenomena of benign overfitting ...
ECG-Based Electrolyte Prediction: Evaluating Regression and Probabilistic Methods
Dec 21, 2022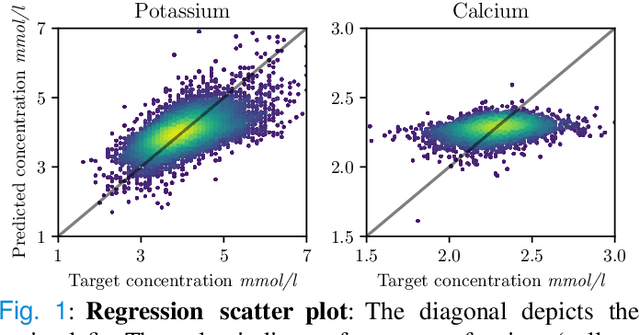
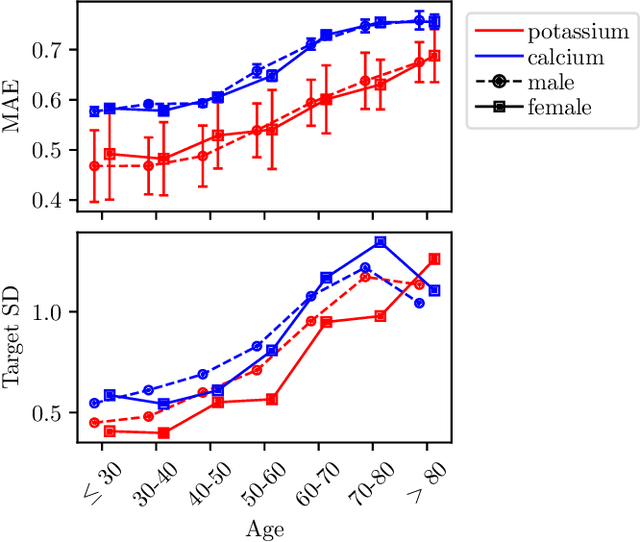
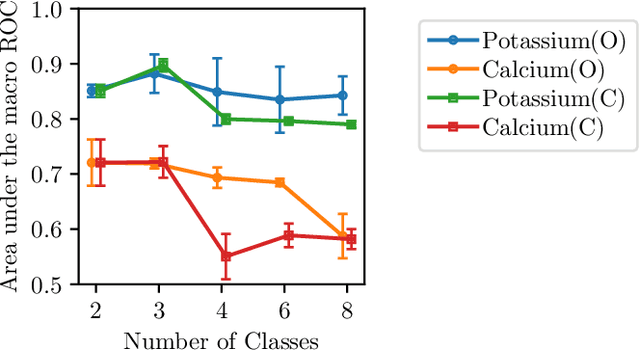
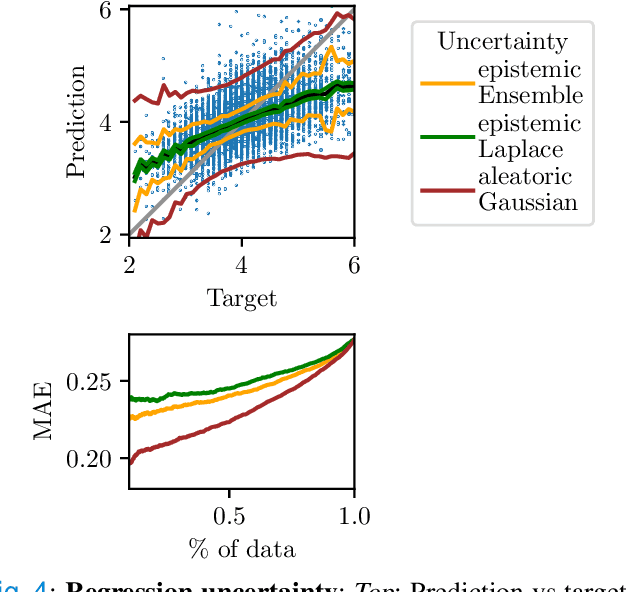
Objective: Imbalances of the electrolyte concentration levels in the body can lead to catastrophic consequences, but accurate and accessible measurements could improve patient outcomes. While blood tests provide accurate measurements, they are invasive and the laboratory analysis can be slow or inaccessible. In contrast, an electrocardiogram (ECG) is a widely adopted tool which is quick and simple to acquire. However, the problem of estimating continuous electrolyte concentrations directly from ECGs is not well-studied. We therefore investigate if regression methods can be used for accurate ECG-based prediction of electrolyte concentrations. Methods: We explore the use of deep neural networks (DNNs) for this task. We analyze the regression performance across four electrolytes, utilizing a novel dataset containing over 290000 ECGs. For improved understanding, we also study the full spectrum from continuous predictions to binary classification of extreme concentration levels. To enhance clinical usefulness, we finally extend to a probabilistic regression approach and evaluate different uncertainty estimates. Results: We find that the performance varies significantly between different electrolytes, which is clinically justified in the interplay of electrolytes and their manifestation in the ECG. We also compare the regression accuracy with that of traditional machine learning models, demonstrating superior performance of DNNs. Conclusion: Discretization can lead to good classification performance, but does not help solve the original problem of predicting continuous concentration levels. While probabilistic regression demonstrates potential practical usefulness, the uncertainty estimates are not particularly well-calibrated. Significance: Our study is a first step towards accurate and reliable ECG-based prediction of electrolyte concentration levels.
Deep State Space Models for Nonlinear System Identification
Mar 31, 2020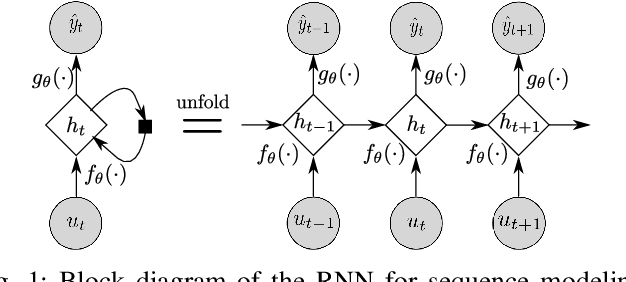
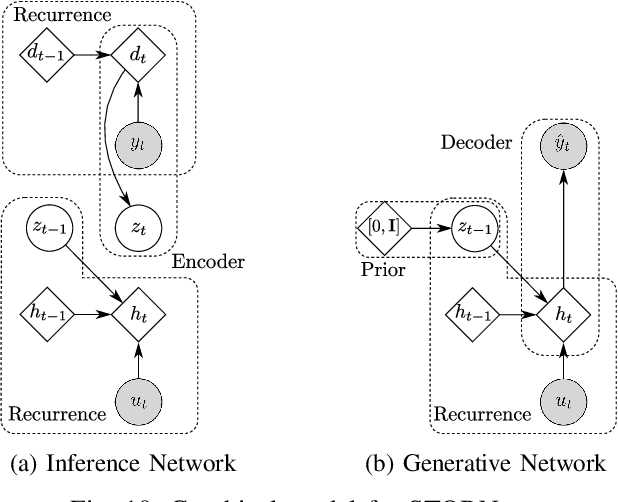
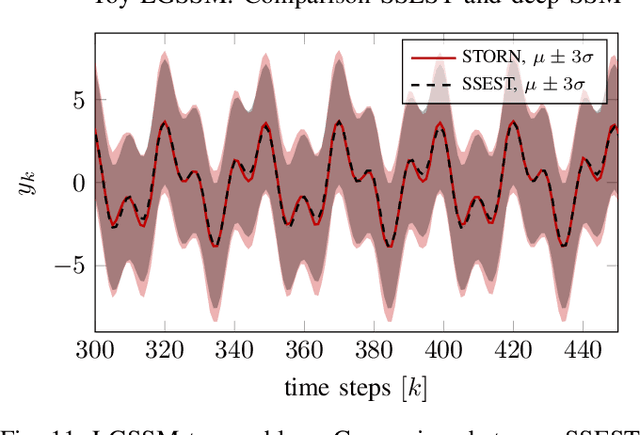
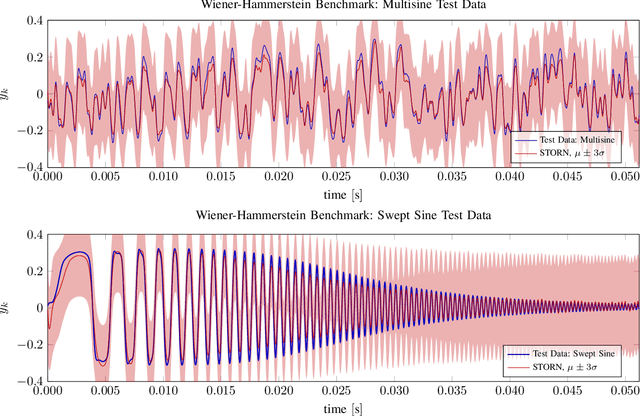
An actively evolving model class for generative temporal models developed in the deep learning community are deep state space models (SSMs) which have a close connection to classic SSMs. In this work six new deep SSMs are implemented and evaluated for the identification of established nonlinear dynamic system benchmarks. The models and their parameter learning algorithms are elaborated rigorously. The usage of deep SSMs as a black-box identification model can describe a wide range of dynamics due to the flexibility of deep neural networks. Additionally, the uncertainty of the system is modelled and therefore one obtains a much richer representation and a whole class of systems to describe the underlying dynamics.