 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnytime-Valid Conformal Risk Control
Feb 04, 2026Prediction sets provide a means of quantifying the uncertainty in predictive tasks. Using held out calibration data, conformal prediction and risk control can produce prediction sets that exhibit statistically valid error control in a computationally efficient manner. However, in the standard formulations, the error is only controlled on average over many possible calibration datasets of fixed size. In this paper, we extend the control to remain valid with high probability over a cumulatively growing calibration dataset at any time point. We derive such guarantees using quantile-based arguments and illustrate the applicability of the proposed framework to settings involving distribution shift. We further establish a matching lower bound and show that our guarantees are asymptotically tight. Finally, we demonstrate the practical performance of our methods through both simulations and real-world numerical examples.
CODE-II: A large-scale dataset for artificial intelligence in ECG analysis
Nov 19, 2025Data-driven methods for electrocardiogram (ECG) interpretation are rapidly progressing. Large datasets have enabled advances in artificial intelligence (AI) based ECG analysis, yet limitations in annotation quality, size, and scope remain major challenges. Here we present CODE-II, a large-scale real-world dataset of 2,735,269 12-lead ECGs from 2,093,807 adult patients collected by the Telehealth Network of Minas Gerais (TNMG), Brazil. Each exam was annotated using standardized diagnostic criteria and reviewed by cardiologists. A defining feature of CODE-II is a set of 66 clinically meaningful diagnostic classes, developed with cardiologist input and routinely used in telehealth practice. We additionally provide an open available subset: CODE-II-open, a public subset of 15,000 patients, and the CODE-II-test, a non-overlapping set of 8,475 exams reviewed by multiple cardiologists for blinded evaluation. A neural network pre-trained on CODE-II achieved superior transfer performance on external benchmarks (PTB-XL and CPSC 2018) and outperformed alternatives trained on larger datasets.
Detection of Chagas Disease from the ECG: The George B. Moody PhysioNet Challenge 2025
Oct 02, 2025Objective: Chagas disease is a parasitic infection that is endemic to South America, Central America, and, more recently, the U.S., primarily transmitted by insects. Chronic Chagas disease can cause cardiovascular diseases and digestive problems. Serological testing capacities for Chagas disease are limited, but Chagas cardiomyopathy often manifests in ECGs, providing an opportunity to prioritize patients for testing and treatment. Approach: The George B. Moody PhysioNet Challenge 2025 invites teams to develop algorithmic approaches for identifying Chagas disease from electrocardiograms (ECGs). Main results: This Challenge provides multiple innovations. First, we leveraged several datasets with labels from patient reports and serological testing, provided a large dataset with weak labels and smaller datasets with strong labels. Second, we augmented the data to support model robustness and generalizability to unseen data sources. Third, we applied an evaluation metric that captured the local serological testing capacity for Chagas disease to frame the machine learning problem as a triage task. Significance: Over 630 participants from 111 teams submitted over 1300 entries during the Challenge, representing diverse approaches from academia and industry worldwide.
Explaining deep learning for ECG using time-localized clusters
Sep 18, 2025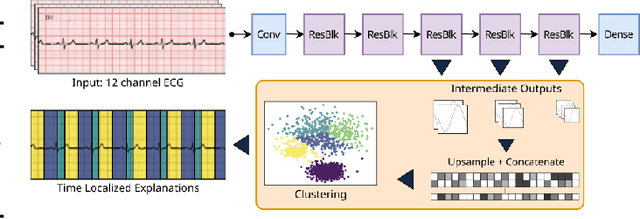
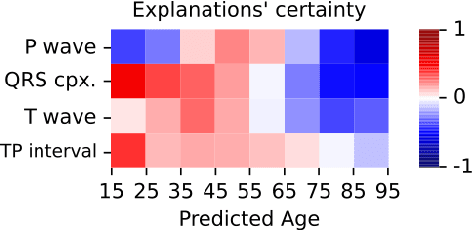
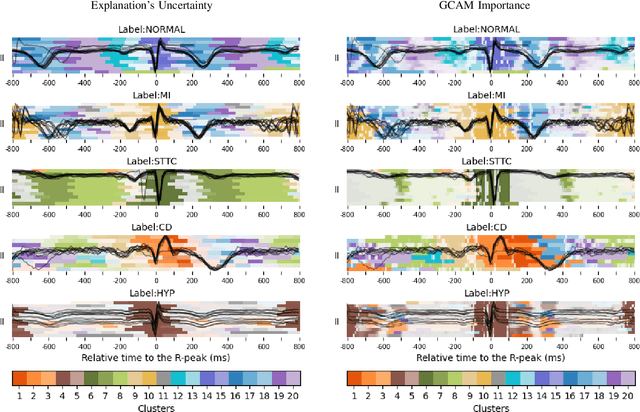
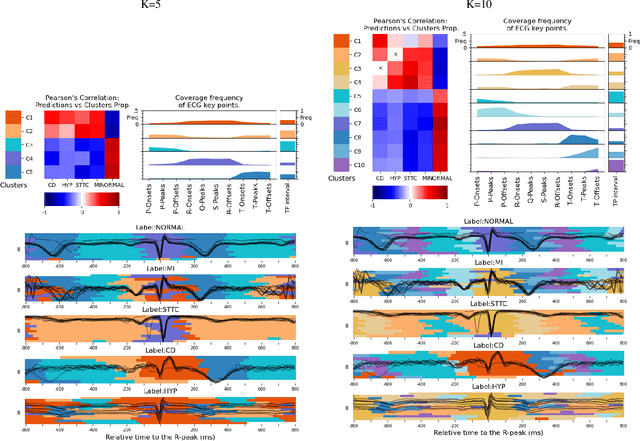
Deep learning has significantly advanced electrocardiogram (ECG) analysis, enabling automatic annotation, disease screening, and prognosis beyond traditional clinical capabilities. However, understanding these models remains a challenge, limiting interpretation and gaining knowledge from these developments. In this work, we propose a novel interpretability method for convolutional neural networks applied to ECG analysis. Our approach extracts time-localized clusters from the model's internal representations, segmenting the ECG according to the learned characteristics while quantifying the uncertainty of these representations. This allows us to visualize how different waveform regions contribute to the model's predictions and assess the certainty of its decisions. By providing a structured and interpretable view of deep learning models for ECG, our method enhances trust in AI-driven diagnostics and facilitates the discovery of clinically relevant electrophysiological patterns.
On the Interaction of Compressibility and Adversarial Robustness
Jul 23, 2025Modern neural networks are expected to simultaneously satisfy a host of desirable properties: accurate fitting to training data, generalization to unseen inputs, parameter and computational efficiency, and robustness to adversarial perturbations. While compressibility and robustness have each been studied extensively, a unified understanding of their interaction still remains elusive. In this work, we develop a principled framework to analyze how different forms of compressibility - such as neuron-level sparsity and spectral compressibility - affect adversarial robustness. We show that these forms of compression can induce a small number of highly sensitive directions in the representation space, which adversaries can exploit to construct effective perturbations. Our analysis yields a simple yet instructive robustness bound, revealing how neuron and spectral compressibility impact $L_\infty$ and $L_2$ robustness via their effects on the learned representations. Crucially, the vulnerabilities we identify arise irrespective of how compression is achieved - whether via regularization, architectural bias, or implicit learning dynamics. Through empirical evaluations across synthetic and realistic tasks, we confirm our theoretical predictions, and further demonstrate that these vulnerabilities persist under adversarial training and transfer learning, and contribute to the emergence of universal adversarial perturbations. Our findings show a fundamental tension between structured compressibility and robustness, and suggest new pathways for designing models that are both efficient and secure.
Human-Aligned Image Models Improve Visual Decoding from the Brain
Feb 05, 2025Decoding visual images from brain activity has significant potential for advancing brain-computer interaction and enhancing the understanding of human perception. Recent approaches align the representation spaces of images and brain activity to enable visual decoding. In this paper, we introduce the use of human-aligned image encoders to map brain signals to images. We hypothesize that these models more effectively capture perceptual attributes associated with the rapid visual stimuli presentations commonly used in visual brain data recording experiments. Our empirical results support this hypothesis, demonstrating that this simple modification improves image retrieval accuracy by up to 21% compared to state-of-the-art methods. Comprehensive experiments confirm consistent performance improvements across diverse EEG architectures, image encoders, alignment methods, participants, and brain imaging modalities.
Can Transformers Smell Like Humans?
Nov 05, 2024
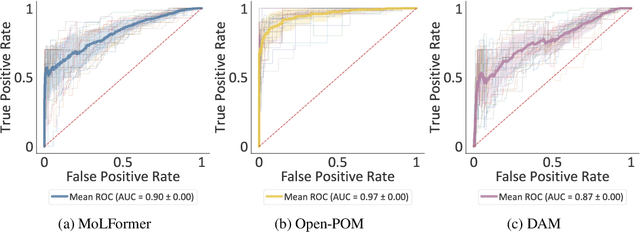
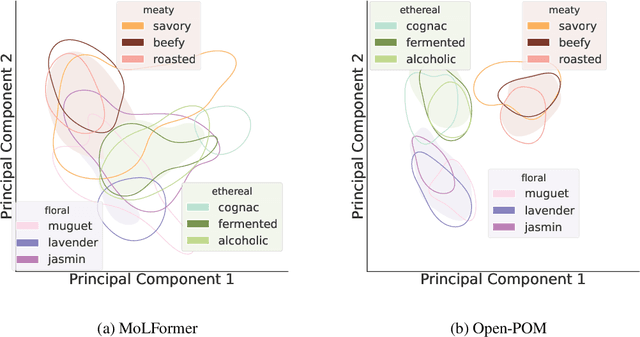
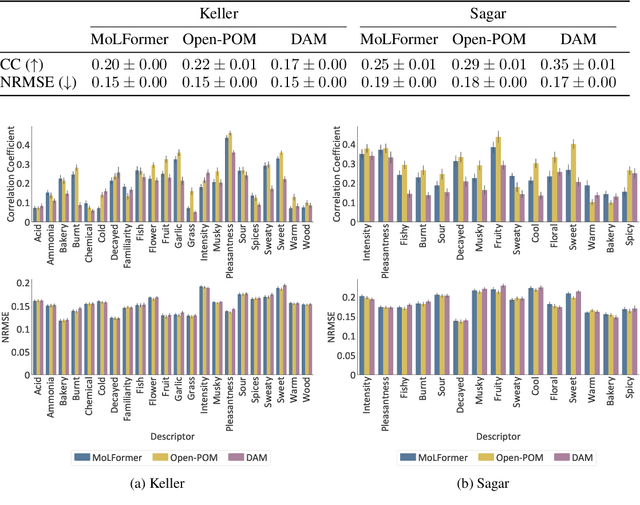
The human brain encodes stimuli from the environment into representations that form a sensory perception of the world. Despite recent advances in understanding visual and auditory perception, olfactory perception remains an under-explored topic in the machine learning community due to the lack of large-scale datasets annotated with labels of human olfactory perception. In this work, we ask the question of whether pre-trained transformer models of chemical structures encode representations that are aligned with human olfactory perception, i.e., can transformers smell like humans? We demonstrate that representations encoded from transformers pre-trained on general chemical structures are highly aligned with human olfactory perception. We use multiple datasets and different types of perceptual representations to show that the representations encoded by transformer models are able to predict: (i) labels associated with odorants provided by experts; (ii) continuous ratings provided by human participants with respect to pre-defined descriptors; and (iii) similarity ratings between odorants provided by human participants. Finally, we evaluate the extent to which this alignment is associated with physicochemical features of odorants known to be relevant for olfactory decoding.
Regularization properties of adversarially-trained linear regression
Oct 16, 2023State-of-the-art machine learning models can be vulnerable to very small input perturbations that are adversarially constructed. Adversarial training is an effective approach to defend against it. Formulated as a min-max problem, it searches for the best solution when the training data were corrupted by the worst-case attacks. Linear models are among the simple models where vulnerabilities can be observed and are the focus of our study. In this case, adversarial training leads to a convex optimization problem which can be formulated as the minimization of a finite sum. We provide a comparative analysis between the solution of adversarial training in linear regression and other regularization methods. Our main findings are that: (A) Adversarial training yields the minimum-norm interpolating solution in the overparameterized regime (more parameters than data), as long as the maximum disturbance radius is smaller than a threshold. And, conversely, the minimum-norm interpolator is the solution to adversarial training with a given radius. (B) Adversarial training can be equivalent to parameter shrinking methods (ridge regression and Lasso). This happens in the underparametrized region, for an appropriate choice of adversarial radius and zero-mean symmetrically distributed covariates. (C) For $\ell_\infty$-adversarial training -- as in square-root Lasso -- the choice of adversarial radius for optimal bounds does not depend on the additive noise variance. We confirm our theoretical findings with numerical examples.
End-to-end Risk Prediction of Atrial Fibrillation from the 12-Lead ECG by Deep Neural Networks
Sep 28, 2023



Background: Atrial fibrillation (AF) is one of the most common cardiac arrhythmias that affects millions of people each year worldwide and it is closely linked to increased risk of cardiovascular diseases such as stroke and heart failure. Machine learning methods have shown promising results in evaluating the risk of developing atrial fibrillation from the electrocardiogram. We aim to develop and evaluate one such algorithm on a large CODE dataset collected in Brazil. Results: The deep neural network model identified patients without indication of AF in the presented ECG but who will develop AF in the future with an AUC score of 0.845. From our survival model, we obtain that patients in the high-risk group (i.e. with the probability of a future AF case being greater than 0.7) are 50% more likely to develop AF within 40 weeks, while patients belonging to the minimal-risk group (i.e. with the probability of a future AF case being less than or equal to 0.1) have more than 85% chance of remaining AF free up until after seven years. Conclusion: We developed and validated a model for AF risk prediction. If applied in clinical practice, the model possesses the potential of providing valuable and useful information in decision-making and patient management processes.
* 16 pages with 7 figures
Deep networks for system identification: a Survey
Jan 30, 2023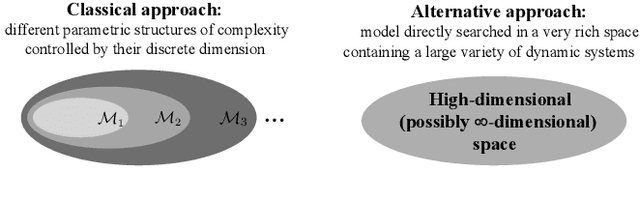
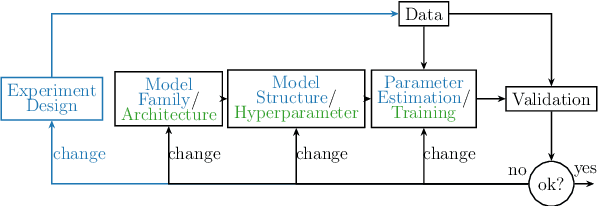
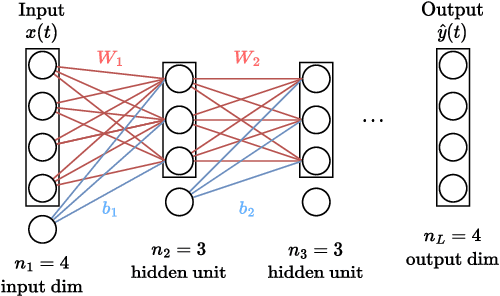
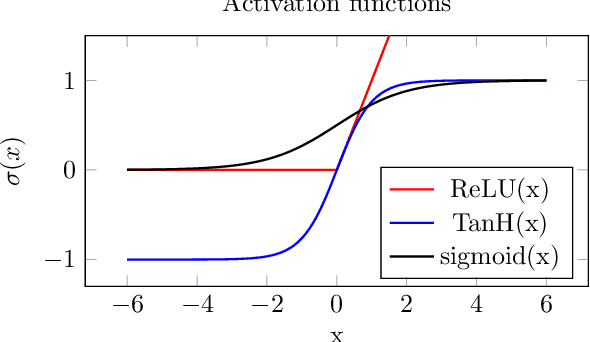
Deep learning is a topic of considerable current interest. The availability of massive data collections and powerful software resources has led to an impressive amount of results in many application areas that reveal essential but hidden properties of the observations. System identification learns mathematical descriptions of dynamic systems from input-output data and can thus benefit from the advances of deep neural networks to enrich the possible range of models to choose from. For this reason, we provide a survey of deep learning from a system identification perspective. We cover a wide spectrum of topics to enable researchers to understand the methods, providing rigorous practical and theoretical insights into the benefits and challenges of using them. The main aim of the identified model is to predict new data from previous observations. This can be achieved with different deep learning based modelling techniques and we discuss architectures commonly adopted in the literature, like feedforward, convolutional, and recurrent networks. Their parameters have to be estimated from past data trying to optimize the prediction performance. For this purpose, we discuss a specific set of first-order optimization tools that is emerged as efficient. The survey then draws connections to the well-studied area of kernel-based methods. They control the data fit by regularization terms that penalize models not in line with prior assumptions. We illustrate how to cast them in deep architectures to obtain deep kernel-based methods. The success of deep learning also resulted in surprising empirical observations, like the counter-intuitive behaviour of models with many parameters. We discuss the role of overparameterized models, including their connection to kernels, as well as implicit regularization mechanisms which affect generalization, specifically the interesting phenomena of benign overfitting ...