 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Cells to Survival: Hierarchical Analysis of Cell Inter-Relations in Multiplex Microscopy for Lung Cancer Prognosis
Dec 09, 2025The tumor microenvironment (TME) has emerged as a promising source of prognostic biomarkers. To fully leverage its potential, analysis methods must capture complex interactions between different cell types. We propose HiGINE -- a hierarchical graph-based approach to predict patient survival (short vs. long) from TME characterization in multiplex immunofluorescence (mIF) images and enhance risk stratification in lung cancer. Our model encodes both local and global inter-relations in cell neighborhoods, incorporating information about cell types and morphology. Multimodal fusion, aggregating cancer stage with mIF-derived features, further boosts performance. We validate HiGINE on two public datasets, demonstrating improved risk stratification, robustness, and generalizability.
Isolated Channel Vision Transformers: From Single-Channel Pretraining to Multi-Channel Finetuning
Mar 12, 2025Vision Transformers (ViTs) have achieved remarkable success in standard RGB image processing tasks. However, applying ViTs to multi-channel imaging (MCI) data, e.g., for medical and remote sensing applications, remains a challenge. In particular, MCI data often consist of layers acquired from different modalities. Directly training ViTs on such data can obscure complementary information and impair the performance. In this paper, we introduce a simple yet effective pretraining framework for large-scale MCI datasets. Our method, named Isolated Channel ViT (IC-ViT), patchifies image channels individually and thereby enables pretraining for multimodal multi-channel tasks. We show that this channel-wise patchifying is a key technique for MCI processing. More importantly, one can pretrain the IC-ViT on single channels and finetune it on downstream multi-channel datasets. This pretraining framework captures dependencies between patches as well as channels and produces robust feature representation. Experiments on various tasks and benchmarks, including JUMP-CP and CHAMMI for cell microscopy imaging, and So2Sat-LCZ42 for satellite imaging, show that the proposed IC-ViT delivers 4-14 percentage points of performance improvement over existing channel-adaptive approaches. Further, its efficient training makes it a suitable candidate for large-scale pretraining of foundation models on heterogeneous data.
A Deep Learning Framework for Automatic Diagnosis in Lung Cancer
Jul 27, 2018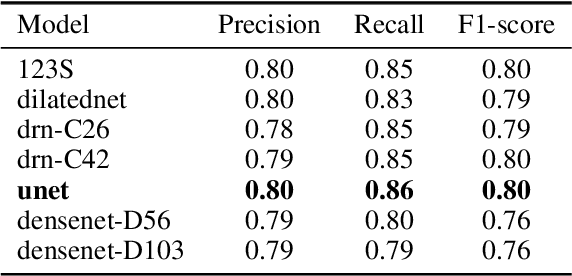
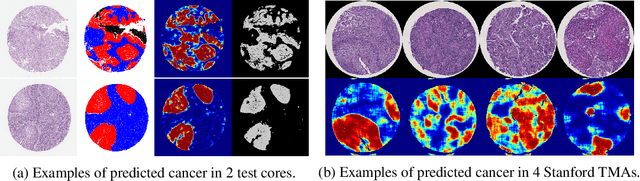
We developed a deep learning framework that helps to automatically identify and segment lung cancer areas in patients' tissue specimens. The study was based on a cohort of lung cancer patients operated at the Uppsala University Hospital. The tissues were reviewed by lung pathologists and then the cores were compiled to tissue micro-arrays (TMAs). For experiments, hematoxylin-eosin stained slides from 712 patients were scanned and then manually annotated. Then these scans and annotations were used to train segmentation models of the developed framework. The performance of the developed deep learning framework was evaluated on fully annotated TMA cores from 178 patients reaching pixel-wise precision of 0.80 and recall of 0.86. Finally, publicly available Stanford TMA cores were used to demonstrate high performance of the framework qualitatively.