 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstration-based learning for few-shot biomedical named entity recognition under machine reading comprehension
Aug 12, 2023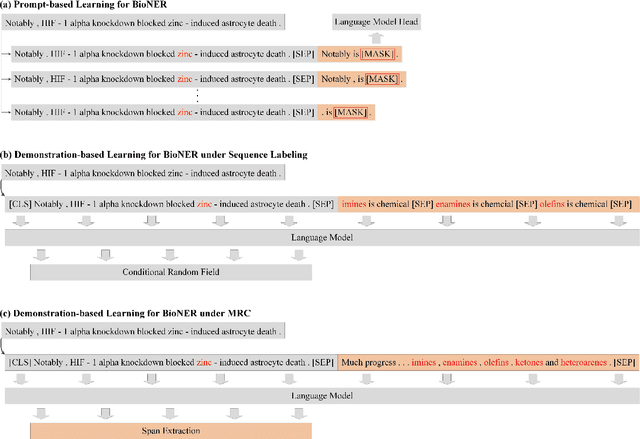

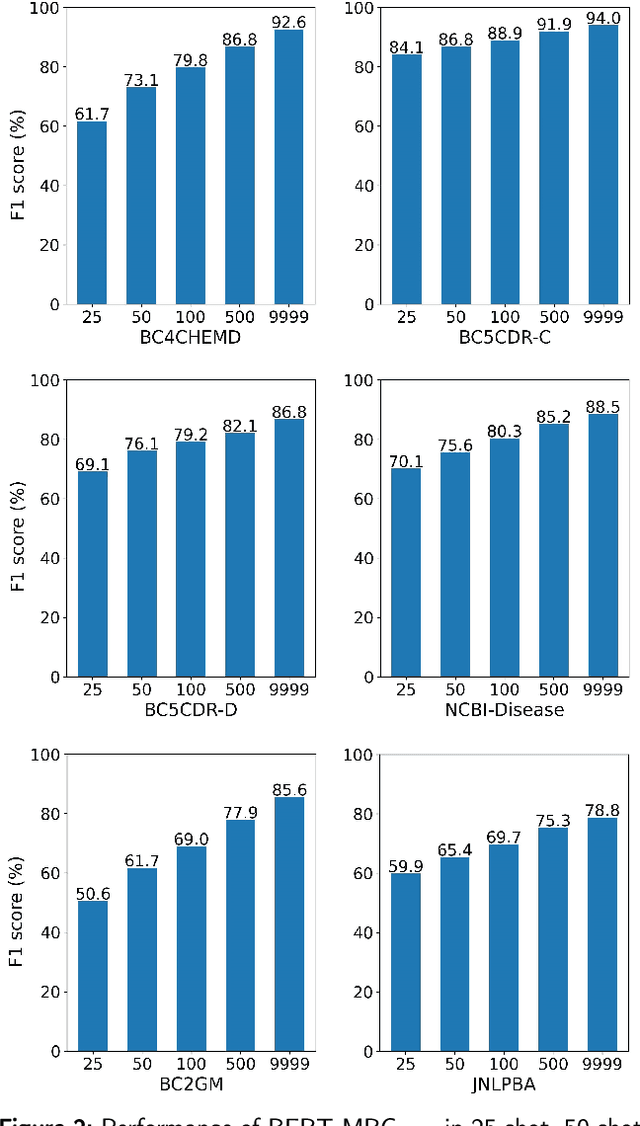
Although deep learning techniques have shown significant achievements, they frequently depend on extensive amounts of hand-labeled data and tend to perform inadequately in few-shot scenarios. The objective of this study is to devise a strategy that can improve the model's capability to recognize biomedical entities in scenarios of few-shot learning. By redefining biomedical named entity recognition (BioNER) as a machine reading comprehension (MRC) problem, we propose a demonstration-based learning method to address few-shot BioNER, which involves constructing appropriate task demonstrations. In assessing our proposed method, we compared the proposed method with existing advanced methods using six benchmark datasets, including BC4CHEMD, BC5CDR-Chemical, BC5CDR-Disease, NCBI-Disease, BC2GM, and JNLPBA. We examined the models' efficacy by reporting F1 scores from both the 25-shot and 50-shot learning experiments. In 25-shot learning, we observed 1.1% improvements in the average F1 scores compared to the baseline method, reaching 61.7%, 84.1%, 69.1%, 70.1%, 50.6%, and 59.9% on six datasets, respectively. In 50-shot learning, we further improved the average F1 scores by 1.0% compared to the baseline method, reaching 73.1%, 86.8%, 76.1%, 75.6%, 61.7%, and 65.4%, respectively. We reported that in the realm of few-shot learning BioNER, MRC-based language models are much more proficient in recognizing biomedical entities compared to the sequence labeling approach. Furthermore, our MRC-language models can compete successfully with fully-supervised learning methodologies that rely heavily on the availability of abundant annotated data. These results highlight possible pathways for future advancements in few-shot BioNER methodologies.
Chemical-protein Interaction Extraction via Gaussian Probability Distribution and External Biomedical Knowledge
Nov 21, 2019
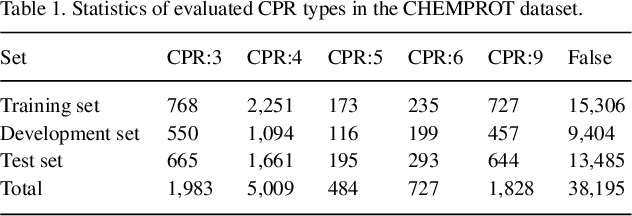
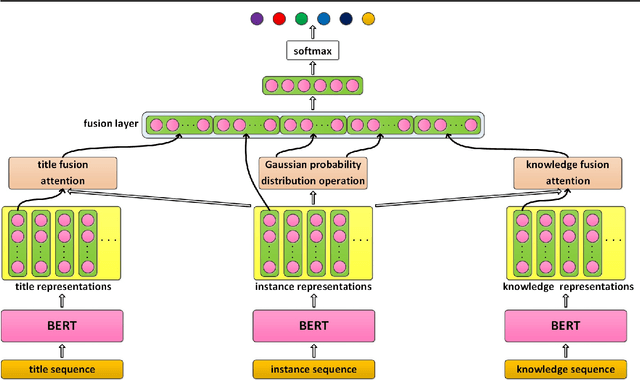
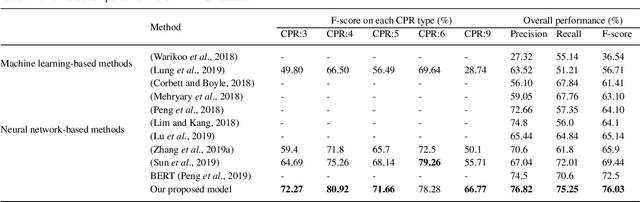
The biomedical literature contains a wealth of chemical-protein interactions (CPIs). Automatically extracting CPIs described in biomedical literature is essential for drug discovery, precision medicine, as well as basic biomedical research. However, the existing methods do not consider the impact of overlapping relations on CPI extraction. This leads to the extraction of sentences with overlapping relations becoming the bottleneck of CPI extraction. In this paper, we propose a novel neural network-based approach to improve the CPI extraction performance of sentences with overlapping relations. Specifically, the approach first employs BERT to generate high-quality contextual representations of the title sequence, instance sequence, and knowledge sequence. Then, the Gaussian probability distribution is introduced to capture the local structure of the instance. Meanwhile, the attention mechanism is applied to fuse the title information and biomedical knowledge, respectively. Finally, the related representations are concatenated and fed into the softmax function to extract CPIs. We evaluate our proposed model on the CHEMPROT corpus. Our proposed model is superior in performance as compared with other state-of-the-art models. The experimental results show that the Gaussian probability distribution and external knowledge are complementary to each other. Integrating them can effectively improve the CPI extraction performance. Furthermore, the Gaussian probability distribution can significantly improve the extraction performance of sentences with overlapping relations in biomedical relation extraction tasks. Data and code are available at https://github.com/CongSun-dlut/CPI_extraction.