 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVADE: Multimodal Benchmark for Evasive Content Detection in E-Commerce Applications
May 23, 2025E-commerce platforms increasingly rely on Large Language Models (LLMs) and Vision-Language Models (VLMs) to detect illicit or misleading product content. However, these models remain vulnerable to evasive content: inputs (text or images) that superficially comply with platform policies while covertly conveying prohibited claims. Unlike traditional adversarial attacks that induce overt failures, evasive content exploits ambiguity and context, making it far harder to detect. Existing robustness benchmarks provide little guidance for this demanding, real-world challenge. We introduce EVADE, the first expert-curated, Chinese, multimodal benchmark specifically designed to evaluate foundation models on evasive content detection in e-commerce. The dataset contains 2,833 annotated text samples and 13,961 images spanning six demanding product categories, including body shaping, height growth, and health supplements. Two complementary tasks assess distinct capabilities: Single-Violation, which probes fine-grained reasoning under short prompts, and All-in-One, which tests long-context reasoning by merging overlapping policy rules into unified instructions. Notably, the All-in-One setting significantly narrows the performance gap between partial and full-match accuracy, suggesting that clearer rule definitions improve alignment between human and model judgment. We benchmark 26 mainstream LLMs and VLMs and observe substantial performance gaps: even state-of-the-art models frequently misclassify evasive samples. By releasing EVADE and strong baselines, we provide the first rigorous standard for evaluating evasive-content detection, expose fundamental limitations in current multimodal reasoning, and lay the groundwork for safer and more transparent content moderation systems in e-commerce. The dataset is publicly available at https://huggingface.co/datasets/koenshen/EVADE-Bench.
Unifying Structured Data as Graph for Data-to-Text Pre-Training
Jan 02, 2024Data-to-text (D2T) generation aims to transform structured data into natural language text. Data-to-text pre-training has proved to be powerful in enhancing D2T generation and yields impressive performances. However, previous pre-training methods either oversimplified structured data into a sequence without considering input structures or designed training objectives tailored for a specific data structure (e.g., table or knowledge graph). In this paper, we unify different types of structured data (i.e., table, key-value data, knowledge graph) into the graph format and cast different data-to-text generation tasks as graph-to-text generation. To effectively exploit the structural information of the input graph, we propose a structure-enhanced pre-training method for D2T generation by designing a structure-enhanced Transformer. Concretely, we devise a position matrix for the Transformer, encoding relative positional information of connected nodes in the input graph. In addition, we propose a new attention matrix to incorporate graph structures into the original Transformer by taking the available explicit connectivity structure into account. Extensive experiments on six benchmark datasets show the effectiveness of our model. Our source codes are available at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/unid2t.
Tenrec: A Large-scale Multipurpose Benchmark Dataset for Recommender Systems
Oct 20, 2022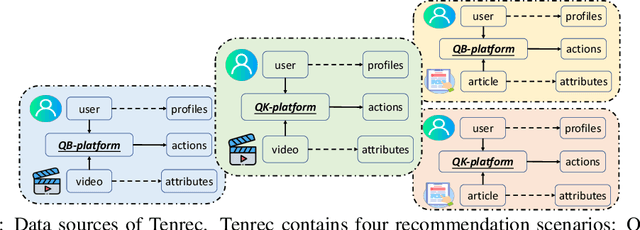
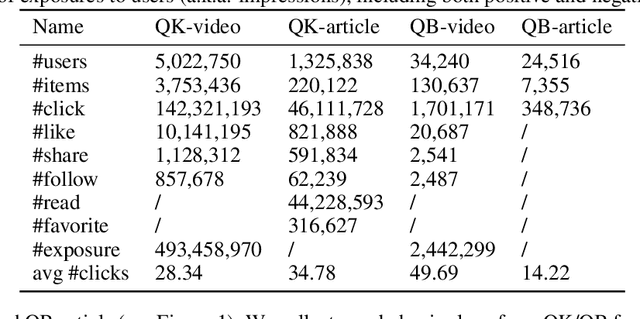
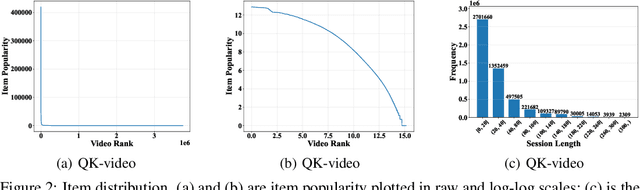

Existing benchmark datasets for recommender systems (RS) either are created at a small scale or involve very limited forms of user feedback. RS models evaluated on such datasets often lack practical values for large-scale real-world applications. In this paper, we describe Tenrec, a novel and publicly available data collection for RS that records various user feedback from four different recommendation scenarios. To be specific, Tenrec has the following five characteristics: (1) it is large-scale, containing around 5 million users and 140 million interactions; (2) it has not only positive user feedback, but also true negative feedback (vs. one-class recommendation); (3) it contains overlapped users and items across four different scenarios; (4) it contains various types of user positive feedback, in forms of clicks, likes, shares, and follows, etc; (5) it contains additional features beyond the user IDs and item IDs. We verify Tenrec on ten diverse recommendation tasks by running several classical baseline models per task. Tenrec has the potential to become a useful benchmark dataset for a majority of popular recommendation tasks.