 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Context is Not Long at All: A Prospector of Long-Dependency Data for Large Language Models
May 28, 2024Long-context modeling capabilities are important for large language models (LLMs) in various applications. However, directly training LLMs with long context windows is insufficient to enhance this capability since some training samples do not exhibit strong semantic dependencies across long contexts. In this study, we propose a data mining framework \textbf{ProLong} that can assign each training sample with a long dependency score, which can be used to rank and filter samples that are more advantageous for enhancing long-context modeling abilities in LLM training. Specifically, we first use delta perplexity scores to measure the \textit{Dependency Strength} between text segments in a given document. Then we refine this metric based on the \textit{Dependency Distance} of these segments to incorporate spatial relationships across long-contexts. Final results are calibrated with a \textit{Dependency Specificity} metric to prevent trivial dependencies introduced by repetitive patterns. Moreover, a random sampling approach is proposed to optimize the computational efficiency of ProLong. Comprehensive experiments on multiple benchmarks indicate that ProLong effectively identifies documents that carry long dependencies and LLMs trained on these documents exhibit significantly enhanced long-context modeling capabilities.
DEEM: Diffusion Models Serve as the Eyes of Large Language Models for Image Perception
May 24, 2024



The development of large language models (LLMs) has significantly advanced the emergence of large multimodal models (LMMs). While LMMs have achieved tremendous success by promoting the synergy between multimodal comprehension and creation, they often face challenges when confronted with out-of-distribution data. This is primarily due to their reliance on image encoders trained to encode images into task-relevant features, which may lead them to disregard irrelevant details. Delving into the modeling capabilities of diffusion models for images naturally prompts the question: Can diffusion models serve as the eyes of large language models for image perception? In this paper, we propose DEEM, a simple and effective approach that utilizes the generative feedback of diffusion models to align the semantic distributions of the image encoder. This addresses the drawbacks of previous methods that solely relied on image encoders like ViT, thereby enhancing the model's resilience against out-of-distribution samples and reducing visual hallucinations. Importantly, this is achieved without requiring additional training modules and with fewer training parameters. We extensively evaluated DEEM on both our newly constructed RobustVQA benchmark and another well-known benchmark, POPE, for object hallucination. Compared to the state-of-the-art interleaved content generation models, DEEM exhibits enhanced robustness and a superior capacity to alleviate model hallucinations while utilizing fewer trainable parameters, less pre-training data (10%), and a smaller base model size.
Unifying Structured Data as Graph for Data-to-Text Pre-Training
Jan 02, 2024Data-to-text (D2T) generation aims to transform structured data into natural language text. Data-to-text pre-training has proved to be powerful in enhancing D2T generation and yields impressive performances. However, previous pre-training methods either oversimplified structured data into a sequence without considering input structures or designed training objectives tailored for a specific data structure (e.g., table or knowledge graph). In this paper, we unify different types of structured data (i.e., table, key-value data, knowledge graph) into the graph format and cast different data-to-text generation tasks as graph-to-text generation. To effectively exploit the structural information of the input graph, we propose a structure-enhanced pre-training method for D2T generation by designing a structure-enhanced Transformer. Concretely, we devise a position matrix for the Transformer, encoding relative positional information of connected nodes in the input graph. In addition, we propose a new attention matrix to incorporate graph structures into the original Transformer by taking the available explicit connectivity structure into account. Extensive experiments on six benchmark datasets show the effectiveness of our model. Our source codes are available at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/unid2t.
VDialogUE: A Unified Evaluation Benchmark for Visually-grounded Dialogue
Sep 14, 2023



Visually-grounded dialog systems, which integrate multiple modes of communication such as text and visual inputs, have become an increasingly popular area of investigation. However, the absence of a standardized evaluation framework poses a challenge in assessing the development of this field. To this end, we propose \textbf{VDialogUE}, a \textbf{V}isually-grounded \textbf{Dialog}ue benchmark for \textbf{U}nified \textbf{E}valuation. It defines five core multi-modal dialogue tasks and covers six datasets. Furthermore, in order to provide a comprehensive assessment of the model's performance across all tasks, we developed a novel evaluation metric called VDscore, which is based on the Analytic Hierarchy Process~(AHP) method. Additionally, we present a straightforward yet efficient baseline model, named \textbf{VISIT}~(\textbf{VIS}ually-grounded d\textbf{I}alog \textbf{T}ransformer), to promote the advancement of general multi-modal dialogue systems. It progressively builds its multi-modal foundation and dialogue capability via a two-stage pre-training strategy. We believe that the VDialogUE benchmark, along with the evaluation scripts and our baseline models, will accelerate the development of visually-grounded dialog systems and lead to the development of more sophisticated and effective pre-trained models.
CGoDial: A Large-Scale Benchmark for Chinese Goal-oriented Dialog Evaluation
Nov 21, 2022Practical dialog systems need to deal with various knowledge sources, noisy user expressions, and the shortage of annotated data. To better solve the above problems, we propose CGoDial, new challenging and comprehensive Chinese benchmark for multi-domain Goal-oriented Dialog evaluation. It contains 96,763 dialog sessions and 574,949 dialog turns totally, covering three datasets with different knowledge sources: 1) a slot-based dialog (SBD) dataset with table-formed knowledge, 2) a flow-based dialog (FBD) dataset with tree-formed knowledge, and a retrieval-based dialog (RBD) dataset with candidate-formed knowledge. To bridge the gap between academic benchmarks and spoken dialog scenarios, we either collect data from real conversations or add spoken features to existing datasets via crowd-sourcing. The proposed experimental settings include the combinations of training with either the entire training set or a few-shot training set, and testing with either the standard test set or a hard test subset, which can assess model capabilities in terms of general prediction, fast adaptability and reliable robustness.
SPACE-3: Unified Dialog Model Pre-training for Task-Oriented Dialog Understanding and Generation
Sep 14, 2022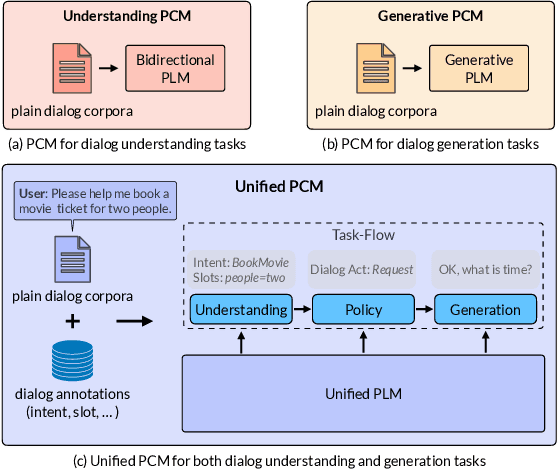
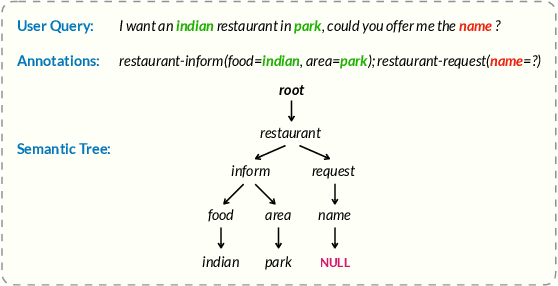
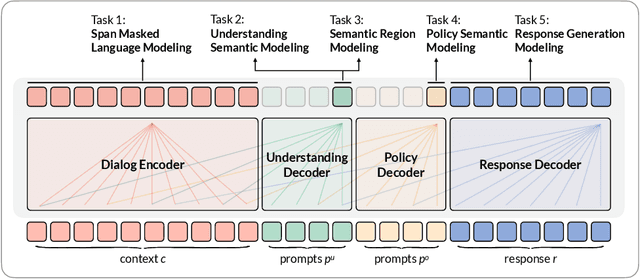
Recently, pre-training methods have shown remarkable success in task-oriented dialog (TOD) systems. However, most existing pre-trained models for TOD focus on either dialog understanding or dialog generation, but not both. In this paper, we propose SPACE-3, a novel unified semi-supervised pre-trained conversation model learning from large-scale dialog corpora with limited annotations, which can be effectively fine-tuned on a wide range of downstream dialog tasks. Specifically, SPACE-3 consists of four successive components in a single transformer to maintain a task-flow in TOD systems: (i) a dialog encoding module to encode dialog history, (ii) a dialog understanding module to extract semantic vectors from either user queries or system responses, (iii) a dialog policy module to generate a policy vector that contains high-level semantics of the response, and (iv) a dialog generation module to produce appropriate responses. We design a dedicated pre-training objective for each component. Concretely, we pre-train the dialog encoding module with span mask language modeling to learn contextualized dialog information. To capture the structured dialog semantics, we pre-train the dialog understanding module via a novel tree-induced semi-supervised contrastive learning objective with the help of extra dialog annotations. In addition, we pre-train the dialog policy module by minimizing the L2 distance between its output policy vector and the semantic vector of the response for policy optimization. Finally, the dialog generation model is pre-trained by language modeling. Results show that SPACE-3 achieves state-of-the-art performance on eight downstream dialog benchmarks, including intent prediction, dialog state tracking, and end-to-end dialog modeling. We also show that SPACE-3 has a stronger few-shot ability than existing models under the low-resource setting.
SPACE-2: Tree-Structured Semi-Supervised Contrastive Pre-training for Task-Oriented Dialog Understanding
Sep 14, 2022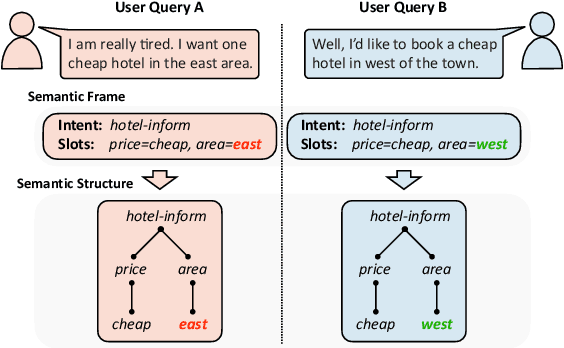
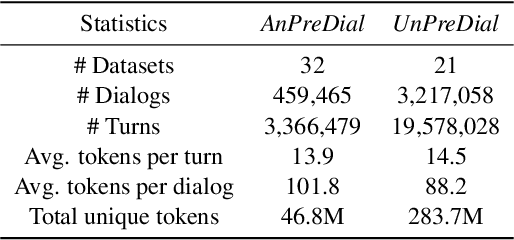
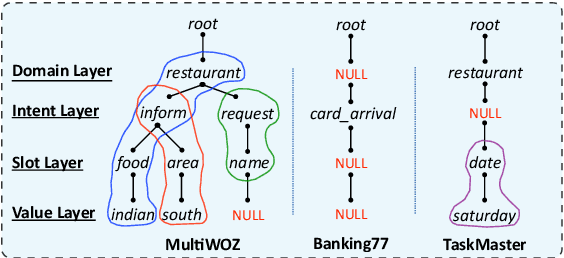
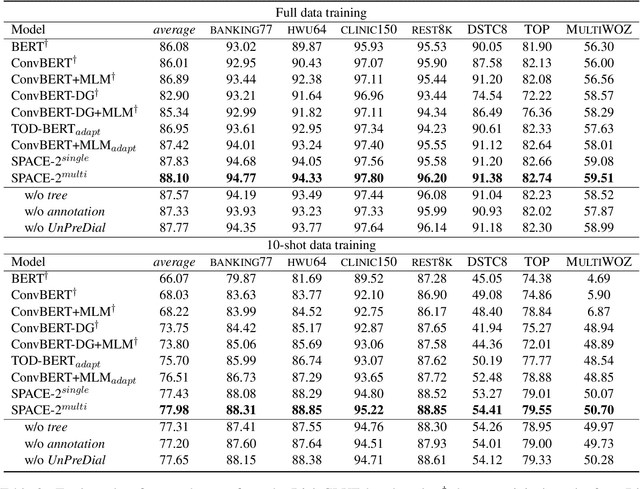
Pre-training methods with contrastive learning objectives have shown remarkable success in dialog understanding tasks. However, current contrastive learning solely considers the self-augmented dialog samples as positive samples and treats all other dialog samples as negative ones, which enforces dissimilar representations even for dialogs that are semantically related. In this paper, we propose SPACE-2, a tree-structured pre-trained conversation model, which learns dialog representations from limited labeled dialogs and large-scale unlabeled dialog corpora via semi-supervised contrastive pre-training. Concretely, we first define a general semantic tree structure (STS) to unify the inconsistent annotation schema across different dialog datasets, so that the rich structural information stored in all labeled data can be exploited. Then we propose a novel multi-view score function to increase the relevance of all possible dialogs that share similar STSs and only push away other completely different dialogs during supervised contrastive pre-training. To fully exploit unlabeled dialogs, a basic self-supervised contrastive loss is also added to refine the learned representations. Experiments show that our method can achieve new state-of-the-art results on the DialoGLUE benchmark consisting of seven datasets and four popular dialog understanding tasks. For reproducibility, we release the code and data at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/space-2.
GALAXY: A Generative Pre-trained Model for Task-Oriented Dialog with Semi-Supervised Learning and Explicit Policy Injection
Dec 27, 2021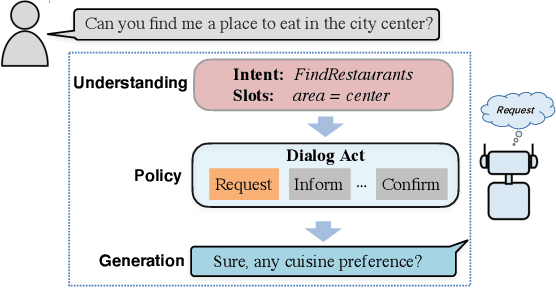
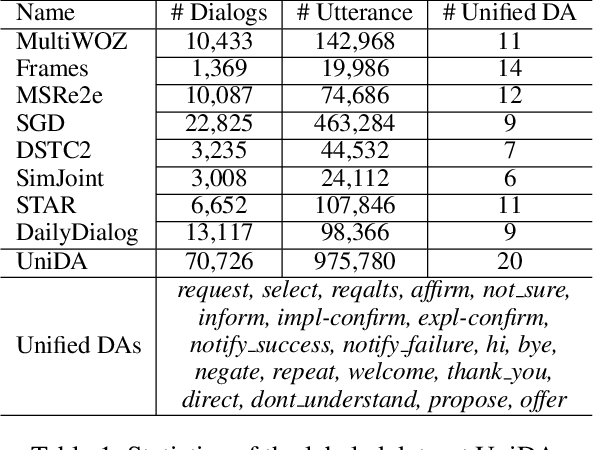

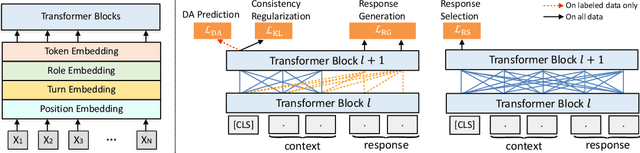
Pre-trained models have proved to be powerful in enhancing task-oriented dialog systems. However, current pre-training methods mainly focus on enhancing dialog understanding and generation tasks while neglecting the exploitation of dialog policy. In this paper, we propose GALAXY, a novel pre-trained dialog model that explicitly learns dialog policy from limited labeled dialogs and large-scale unlabeled dialog corpora via semi-supervised learning. Specifically, we introduce a dialog act prediction task for policy optimization during pre-training and employ a consistency regularization term to refine the learned representation with the help of unlabeled dialogs. We also implement a gating mechanism to weigh suitable unlabeled dialog samples. Empirical results show that GALAXY substantially improves the performance of task-oriented dialog systems, and achieves new state-of-the-art results on benchmark datasets: In-Car, MultiWOZ2.0 and MultiWOZ2.1, improving their end-to-end combined scores by 2.5, 5.3 and 5.5 points, respectively. We also show that GALAXY has a stronger few-shot ability than existing models under various low-resource settings.
A Template-guided Hybrid Pointer Network for Knowledge-basedTask-oriented Dialogue Systems
Jun 10, 2021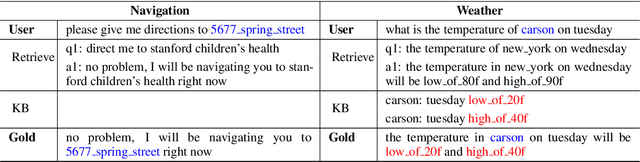
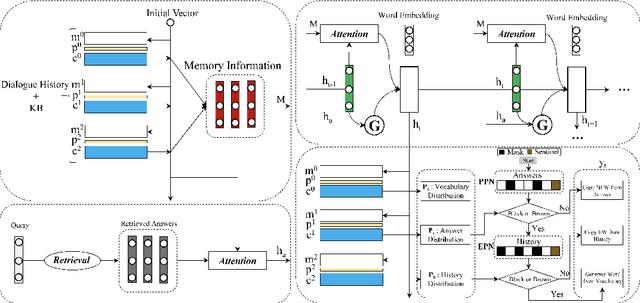
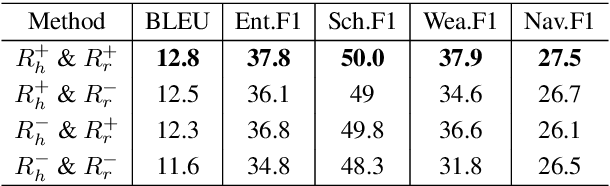
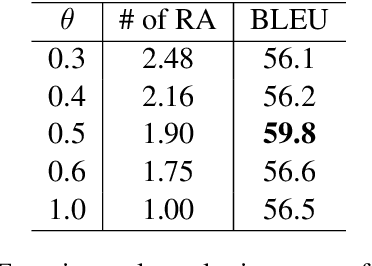
Most existing neural network based task-oriented dialogue systems follow encoder-decoder paradigm, where the decoder purely depends on the source texts to generate a sequence of words, usually suffering from instability and poor readability. Inspired by the traditional template-based generation approaches, we propose a template-guided hybrid pointer network for the knowledge-based task-oriented dialogue system, which retrieves several potentially relevant answers from a pre-constructed domain-specific conversational repository as guidance answers, and incorporates the guidance answers into both the encoding and decoding processes. Specifically, we design a memory pointer network model with a gating mechanism to fully exploit the semantic correlation between the retrieved answers and the ground-truth response. We evaluate our model on four widely used task-oriented datasets, including one simulated and three manually created datasets. The experimental results demonstrate that the proposed model achieves significantly better performance than the state-of-the-art methods over different automatic evaluation metrics.