 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPACE-3: Unified Dialog Model Pre-training for Task-Oriented Dialog Understanding and Generation
Paper and Code
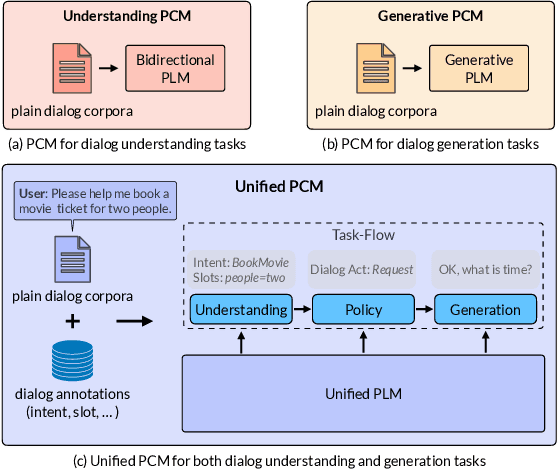
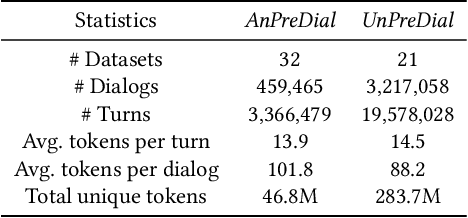
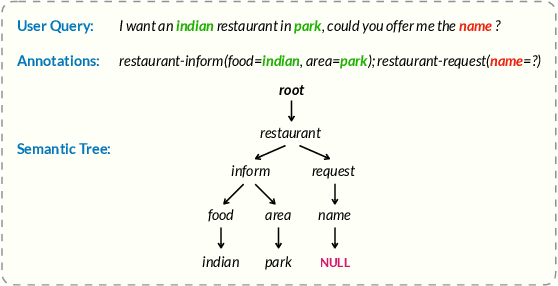
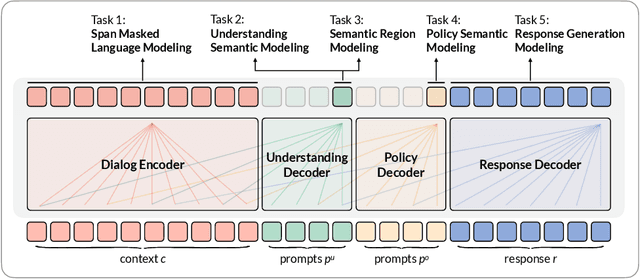
Recently, pre-training methods have shown remarkable success in task-oriented dialog (TOD) systems. However, most existing pre-trained models for TOD focus on either dialog understanding or dialog generation, but not both. In this paper, we propose SPACE-3, a novel unified semi-supervised pre-trained conversation model learning from large-scale dialog corpora with limited annotations, which can be effectively fine-tuned on a wide range of downstream dialog tasks. Specifically, SPACE-3 consists of four successive components in a single transformer to maintain a task-flow in TOD systems: (i) a dialog encoding module to encode dialog history, (ii) a dialog understanding module to extract semantic vectors from either user queries or system responses, (iii) a dialog policy module to generate a policy vector that contains high-level semantics of the response, and (iv) a dialog generation module to produce appropriate responses. We design a dedicated pre-training objective for each component. Concretely, we pre-train the dialog encoding module with span mask language modeling to learn contextualized dialog information. To capture the structured dialog semantics, we pre-train the dialog understanding module via a novel tree-induced semi-supervised contrastive learning objective with the help of extra dialog annotations. In addition, we pre-train the dialog policy module by minimizing the L2 distance between its output policy vector and the semantic vector of the response for policy optimization. Finally, the dialog generation model is pre-trained by language modeling. Results show that SPACE-3 achieves state-of-the-art performance on eight downstream dialog benchmarks, including intent prediction, dialog state tracking, and end-to-end dialog modeling. We also show that SPACE-3 has a stronger few-shot ability than existing models under the low-resource setting.