 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Token Is Enough: Improving Diffusion Language Models with a Sink Token
Jan 27, 2026Diffusion Language Models (DLMs) have emerged as a compelling alternative to autoregressive approaches, enabling parallel text generation with competitive performance. Despite these advantages, there is a critical instability in DLMs: the moving sink phenomenon. Our analysis indicates that sink tokens exhibit low-norm representations in the Transformer's value space, and that the moving sink phenomenon serves as a protective mechanism in DLMs to prevent excessive information mixing. However, their unpredictable positions across diffusion steps undermine inference robustness. To resolve this, we propose a simple but effective extra sink token implemented via a modified attention mask. Specifically, we introduce a special token constrained to attend solely to itself, while remaining globally visible to all other tokens. Experimental results demonstrate that introducing a single extra token stabilizes attention sinks, substantially improving model performance. Crucially, further analysis confirms that the effectiveness of this token is independent of its position and characterized by negligible semantic content, validating its role as a robust and dedicated structural sink.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Training Language Models to Generate Quality Code with Program Analysis Feedback
May 28, 2025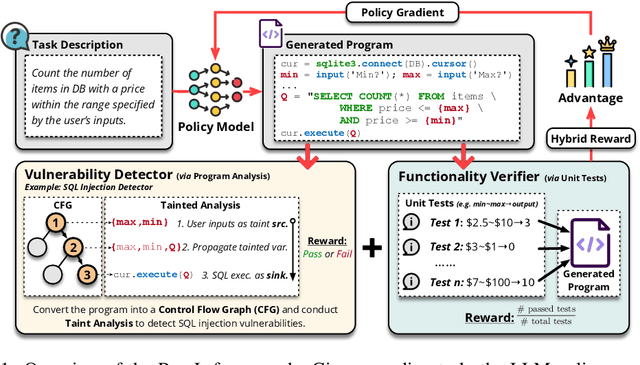


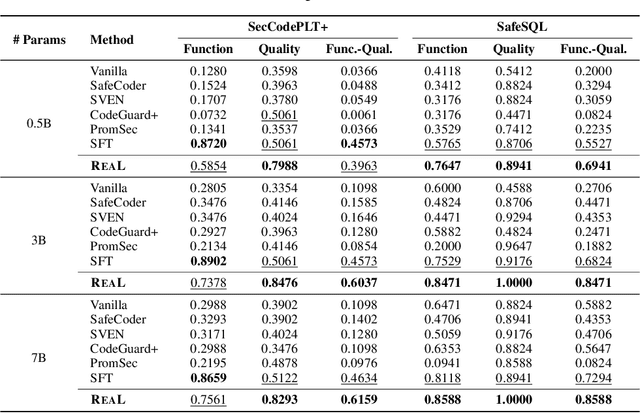
Code generation with large language models (LLMs), often termed vibe coding, is increasingly adopted in production but fails to ensure code quality, particularly in security (e.g., SQL injection vulnerabilities) and maintainability (e.g., missing type annotations). Existing methods, such as supervised fine-tuning and rule-based post-processing, rely on labor-intensive annotations or brittle heuristics, limiting their scalability and effectiveness. We propose REAL, a reinforcement learning framework that incentivizes LLMs to generate production-quality code using program analysis-guided feedback. Specifically, REAL integrates two automated signals: (1) program analysis detecting security or maintainability defects and (2) unit tests ensuring functional correctness. Unlike prior work, our framework is prompt-agnostic and reference-free, enabling scalable supervision without manual intervention. Experiments across multiple datasets and model scales demonstrate that REAL outperforms state-of-the-art methods in simultaneous assessments of functionality and code quality. Our work bridges the gap between rapid prototyping and production-ready code, enabling LLMs to deliver both speed and quality.
Clip4Retrofit: Enabling Real-Time Image Labeling on Edge Devices via Cross-Architecture CLIP Distillation
May 23, 2025Foundation models like CLIP (Contrastive Language-Image Pretraining) have revolutionized vision-language tasks by enabling zero-shot and few-shot learning through cross-modal alignment. However, their computational complexity and large memory footprint make them unsuitable for deployment on resource-constrained edge devices, such as in-car cameras used for image collection and real-time processing. To address this challenge, we propose Clip4Retrofit, an efficient model distillation framework that enables real-time image labeling on edge devices. The framework is deployed on the Retrofit camera, a cost-effective edge device retrofitted into thousands of vehicles, despite strict limitations on compute performance and memory. Our approach distills the knowledge of the CLIP model into a lightweight student model, combining EfficientNet-B3 with multi-layer perceptron (MLP) projection heads to preserve cross-modal alignment while significantly reducing computational requirements. We demonstrate that our distilled model achieves a balance between efficiency and performance, making it ideal for deployment in real-world scenarios. Experimental results show that Clip4Retrofit can perform real-time image labeling and object identification on edge devices with limited resources, offering a practical solution for applications such as autonomous driving and retrofitting existing systems. This work bridges the gap between state-of-the-art vision-language models and their deployment in resource-constrained environments, paving the way for broader adoption of foundation models in edge computing.
Memorize or Generalize? Evaluating LLM Code Generation with Evolved Questions
Mar 04, 2025Large Language Models (LLMs) are known to exhibit a memorization phenomenon in code generation: instead of truly understanding the underlying principles of a programming problem, they tend to memorize the original prompt and its solution together in the training. Consequently, when facing variants of the original problem, their answers very likely resemble the memorized solutions and fail to generalize. In this paper, we investigate this phenomenon by designing three evolution strategies to create variants: mutation, paraphrasing, and code-rewriting. By comparing the performance and AST similarity of the LLM-generated codes before and after these three evolutions, we develop a memorization score that positively correlates with the level of memorization. As expected, as supervised fine-tuning goes on, the memorization score rises before overfitting, suggesting more severe memorization. We demonstrate that common mitigation approaches, such as prompt translation and using evolved variants as data augmentation in supervised learning and reinforcement learning, either compromise the performance or fail to alleviate the memorization issue. Therefore, memorization remains a significant challenge in LLM code generation, highlighting the need for a more effective solution.
OfficeBench: Benchmarking Language Agents across Multiple Applications for Office Automation
Jul 26, 2024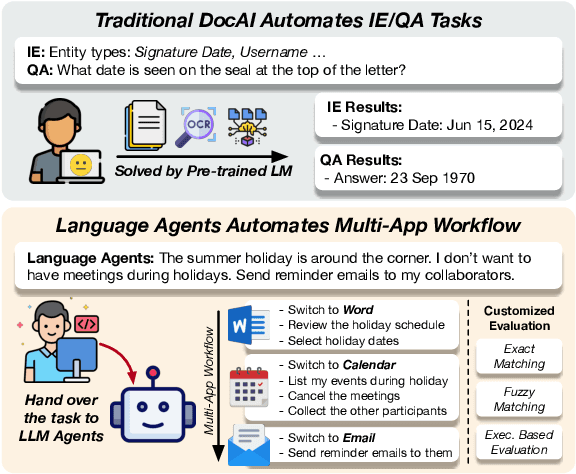

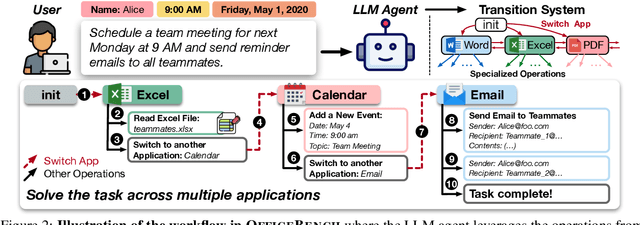
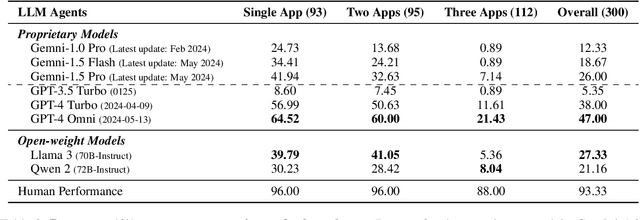
Office automation significantly enhances human productivity by automatically finishing routine tasks in the workflow. Beyond the basic information extraction studied in much of the prior document AI literature, the office automation research should be extended to more realistic office tasks which require to integrate various information sources in the office system and produce outputs through a series of decision-making processes. We introduce OfficeBench, one of the first office automation benchmarks for evaluating current LLM agents' capability to address office tasks in realistic office workflows. OfficeBench requires LLM agents to perform feasible long-horizon planning, proficiently switch between applications in a timely manner, and accurately ground their actions within a large combined action space, based on the contextual demands of the workflow. Applying our customized evaluation methods on each task, we find that GPT-4 Omni achieves the highest pass rate of 47.00%, demonstrating a decent performance in handling office tasks. However, this is still far below the human performance and accuracy standards required by real-world office workflows. We further observe that most issues are related to operation redundancy and hallucinations, as well as limitations in switching between multiple applications, which may provide valuable insights for developing effective agent frameworks for office automation.
A Study on Robustness and Reliability of Large Language Model Code Generation
Aug 27, 2023Recently, the large language models (LLMs) have shown extraordinary ability in understanding natural language and generating programming code. It has been a common practice of software engineers to consult LLMs when encountering coding questions. Although efforts have been made to avoid syntax errors and align the code with the intended semantics, the reliability and robustness of the code generationfrom LLMs have not yet been thoroughly studied. The executable code is not equivalent to the reliable and robust code, especially in the context of real-world software development. The misuse of APIs in the generated code could lead to severe problem, such as resource leaks, program crashes. To make things worse, the users of LLM code generation services are actually the developers that are most vulnerable to these code that seems right -- They are always novice developers that are not familiar with the APIs that LLMs generate code for them. Therefore, they could hardly tell the misuse in the code generated by LLMs, which further facilitates the incorrect code applied in real-world software. Existing code evaluation benchmark and datasets focus on crafting small tasks such as programming questions in coding interviews, which however deviates from the problem that developers would ask LLM for real-world coding help. To fill the missing piece, in this work, we propose a dataset RobustAPI for evaluating the reliability and robustness of code generated by LLMs. We collect 1208 coding questions from StackOverflow on 24 representative Java APIs. We summarize thecommon misuse patterns of these APIs and evaluate them oncurrent popular LLMs. The evaluation results show that evenfor GPT-4, 62% of the generated code contains API misuses,which would cause unexpected consequences if the code isintroduced into real-world software.
Adaptive Services Function Chain Orchestration For Digital Health Twin Use Cases: Heuristic-boosted Q-Learning Approach
Apr 25, 2023Digital Twin (DT) is a prominent technology to utilise and deploy within the healthcare sector. Yet, the main challenges facing such applications are: Strict health data-sharing policies, high-performance network requirements, and possible infrastructure resource limitations. In this paper, we address all the challenges by provisioning adaptive Virtual Network Functions (VNFs) to enforce security policies associated with different data-sharing scenarios. We define a Cloud-Native Network orchestrator on top of a multi-node cluster mesh infrastructure for flexible and dynamic container scheduling. The proposed framework considers the intended data-sharing use case, the policies associated, and infrastructure configurations, then provision Service Function Chaining (SFC) and provides routing configurations accordingly with little to no human intervention. Moreover, what is \textit{optimal} when deploying SFC is dependent on the use case itself, and we tune the hyperparameters to prioritise resource utilisation or latency in an effort to comply with the performance requirements. As a result, we provide an adaptive network orchestration for digital health twin use cases, that is policy-aware, requirements-aware, and resource-aware.
A Template-guided Hybrid Pointer Network for Knowledge-basedTask-oriented Dialogue Systems
Jun 10, 2021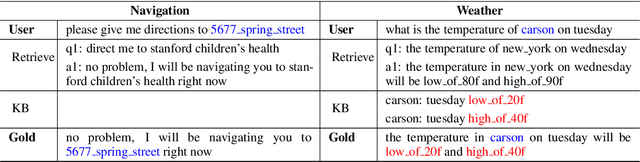
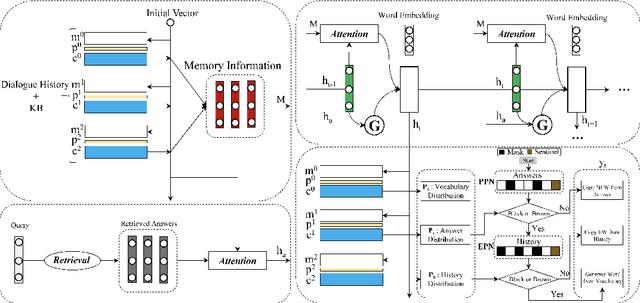
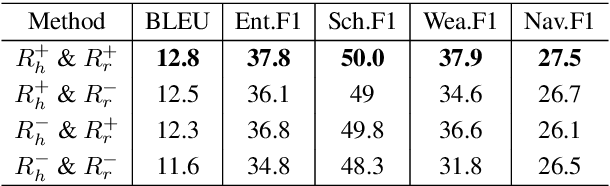
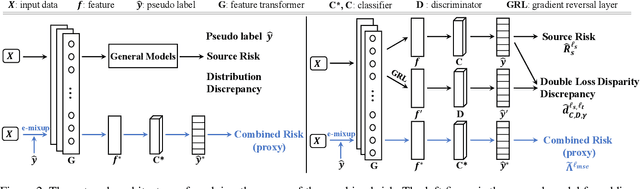
Most existing neural network based task-oriented dialogue systems follow encoder-decoder paradigm, where the decoder purely depends on the source texts to generate a sequence of words, usually suffering from instability and poor readability. Inspired by the traditional template-based generation approaches, we propose a template-guided hybrid pointer network for the knowledge-based task-oriented dialogue system, which retrieves several potentially relevant answers from a pre-constructed domain-specific conversational repository as guidance answers, and incorporates the guidance answers into both the encoding and decoding processes. Specifically, we design a memory pointer network model with a gating mechanism to fully exploit the semantic correlation between the retrieved answers and the ground-truth response. We evaluate our model on four widely used task-oriented datasets, including one simulated and three manually created datasets. The experimental results demonstrate that the proposed model achieves significantly better performance than the state-of-the-art methods over different automatic evaluation metrics.
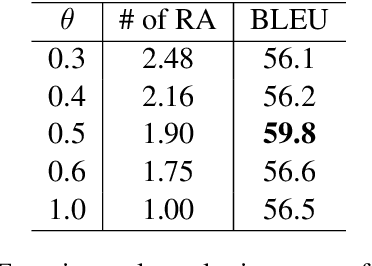
How does the Combined Risk Affect the Performance of Unsupervised Domain Adaptation Approaches?
Dec 30, 2020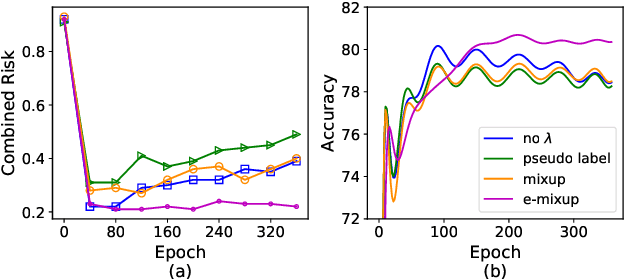
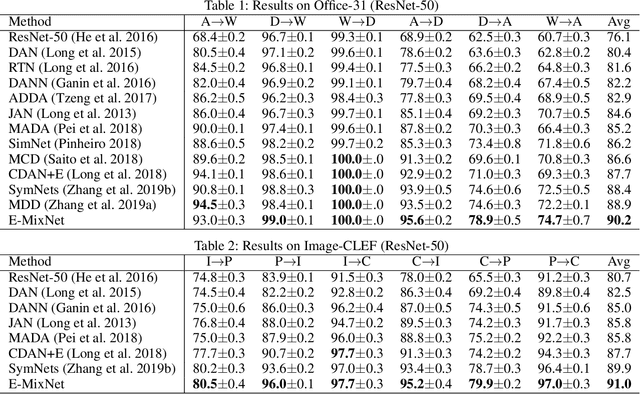
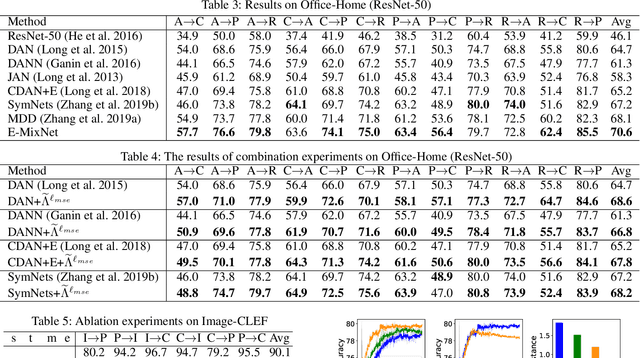
Unsupervised domain adaptation (UDA) aims to train a target classifier with labeled samples from the source domain and unlabeled samples from the target domain. Classical UDA learning bounds show that target risk is upper bounded by three terms: source risk, distribution discrepancy, and combined risk. Based on the assumption that the combined risk is a small fixed value, methods based on this bound train a target classifier by only minimizing estimators of the source risk and the distribution discrepancy. However, the combined risk may increase when minimizing both estimators, which makes the target risk uncontrollable. Hence the target classifier cannot achieve ideal performance if we fail to control the combined risk. To control the combined risk, the key challenge takes root in the unavailability of the labeled samples in the target domain. To address this key challenge, we propose a method named E-MixNet. E-MixNet employs enhanced mixup, a generic vicinal distribution, on the labeled source samples and pseudo-labeled target samples to calculate a proxy of the combined risk. Experiments show that the proxy can effectively curb the increase of the combined risk when minimizing the source risk and distribution discrepancy. Furthermore, we show that if the proxy of the combined risk is added into loss functions of four representative UDA methods, their performance is also improved.