 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs as Scalable, General-Purpose Simulators For Evolving Digital Agent Training
Oct 16, 2025
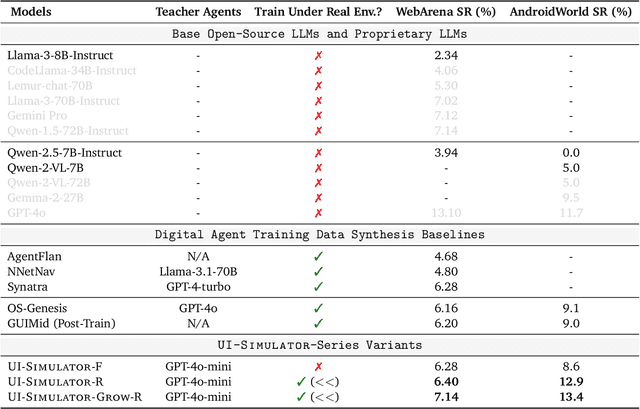

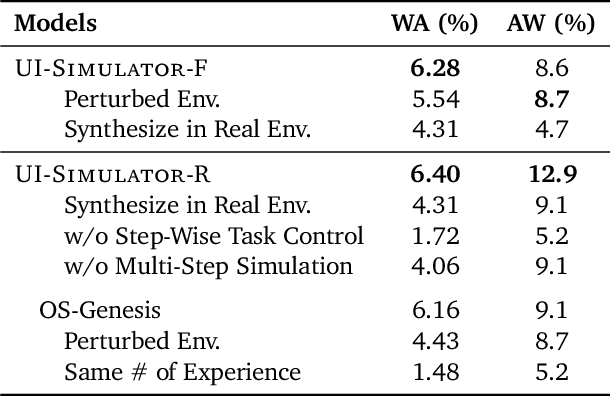
Digital agents require diverse, large-scale UI trajectories to generalize across real-world tasks, yet collecting such data is prohibitively expensive in both human annotation, infra and engineering perspectives. To this end, we introduce $\textbf{UI-Simulator}$, a scalable paradigm that generates structured UI states and transitions to synthesize training trajectories at scale. Our paradigm integrates a digital world simulator for diverse UI states, a guided rollout process for coherent exploration, and a trajectory wrapper that produces high-quality and diverse trajectories for agent training. We further propose $\textbf{UI-Simulator-Grow}$, a targeted scaling strategy that enables more rapid and data-efficient scaling by prioritizing high-impact tasks and synthesizes informative trajectory variants. Experiments on WebArena and AndroidWorld show that UI-Simulator rivals or surpasses open-source agents trained on real UIs with significantly better robustness, despite using weaker teacher models. Moreover, UI-Simulator-Grow matches the performance of Llama-3-70B-Instruct using only Llama-3-8B-Instruct as the base model, highlighting the potential of targeted synthesis scaling paradigm to continuously and efficiently enhance the digital agents.
OfficeBench: Benchmarking Language Agents across Multiple Applications for Office Automation
Jul 26, 2024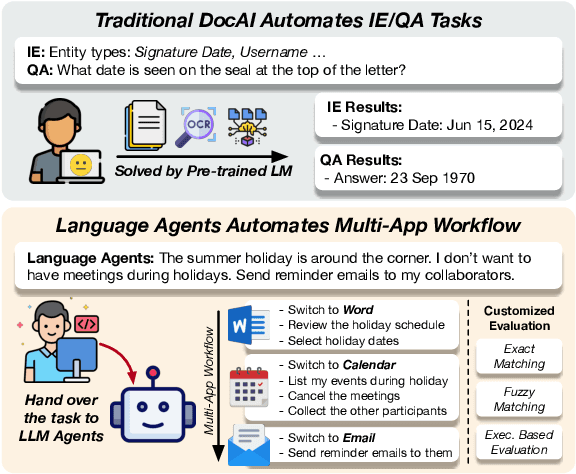

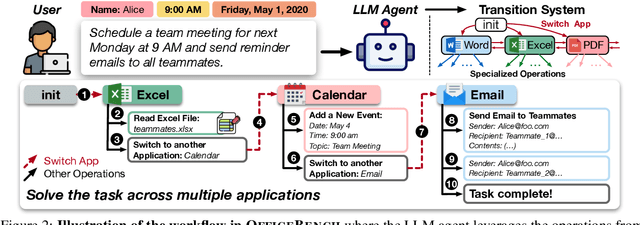
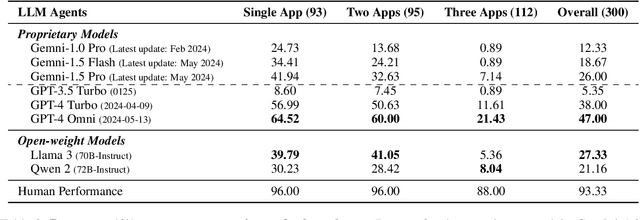
Office automation significantly enhances human productivity by automatically finishing routine tasks in the workflow. Beyond the basic information extraction studied in much of the prior document AI literature, the office automation research should be extended to more realistic office tasks which require to integrate various information sources in the office system and produce outputs through a series of decision-making processes. We introduce OfficeBench, one of the first office automation benchmarks for evaluating current LLM agents' capability to address office tasks in realistic office workflows. OfficeBench requires LLM agents to perform feasible long-horizon planning, proficiently switch between applications in a timely manner, and accurately ground their actions within a large combined action space, based on the contextual demands of the workflow. Applying our customized evaluation methods on each task, we find that GPT-4 Omni achieves the highest pass rate of 47.00%, demonstrating a decent performance in handling office tasks. However, this is still far below the human performance and accuracy standards required by real-world office workflows. We further observe that most issues are related to operation redundancy and hallucinations, as well as limitations in switching between multiple applications, which may provide valuable insights for developing effective agent frameworks for office automation.