 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecision Synthesis of Multi-Tracer PET via VLM-Modulated Rectified Flow for Stratifying Mild Cognitive Impairment
Apr 13, 2026The biological definition of Alzheimer's disease (AD) relies on multi-modal neuroimaging, yet the clinical utility of positron emission tomography (PET) is limited by cost and radiation exposure, hindering early screening at preclinical or prodromal stages. While generative models offer a promising alternative by synthesizing PET from magnetic resonance imaging (MRI), achieving subject-specific precision remains a primary challenge. Here, we introduce DIReCT$++$, a Domain-Informed ReCTified flow model for synthesizing multi-tracer PET from MRI combined with fundamental clinical information. Our approach integrates a 3D rectified flow architecture to capture complex cross-modal and cross-tracer relationships with a domain-adapted vision-language model (BiomedCLIP) that provides text-guided, personalized generation using clinical scores and imaging knowledge. Extensive evaluations on multi-center datasets demonstrate that DIReCT$++$ not only produces synthetic PET images ($^{18}$F-AV-45 and $^{18}$F-FDG) of superior fidelity and generalizability but also accurately recapitulates disease-specific patterns. Crucially, combining these synthesized PET images with MRI enables precise personalized stratification of mild cognitive impairment (MCI), advancing a scalable, data-efficient tool for the early diagnosis and prognostic prediction of AD. The source code will be released on https://github.com/ladderlab-xjtu/DIReCT-PLUS.
Choosing How to Remember: Adaptive Memory Structures for LLM Agents
Feb 15, 2026Memory is critical for enabling large language model (LLM) based agents to maintain coherent behavior over long-horizon interactions. However, existing agent memory systems suffer from two key gaps: they rely on a one-size-fits-all memory structure and do not model memory structure selection as a context-adaptive decision, limiting their ability to handle heterogeneous interaction patterns and resulting in suboptimal performance. We propose a unified framework, FluxMem, that enables adaptive memory organization for LLM agents. Our framework equips agents with multiple complementary memory structures. It explicitly learns to select among these structures based on interaction-level features, using offline supervision derived from downstream response quality and memory utilization. To support robust long-horizon memory evolution, we further introduce a three-level memory hierarchy and a Beta Mixture Model-based probabilistic gate for distribution-aware memory fusion, replacing brittle similarity thresholds. Experiments on two long-horizon benchmarks, PERSONAMEM and LoCoMo, demonstrate that our method achieves average improvements of 9.18% and 6.14%.
Delving into Spectral Clustering with Vision-Language Representations
Feb 10, 2026Spectral clustering is known as a powerful technique in unsupervised data analysis. The vast majority of approaches to spectral clustering are driven by a single modality, leaving the rich information in multi-modal representations untapped. Inspired by the recent success of vision-language pre-training, this paper enriches the landscape of spectral clustering from a single-modal to a multi-modal regime. Particularly, we propose Neural Tangent Kernel Spectral Clustering that leverages cross-modal alignment in pre-trained vision-language models. By anchoring the neural tangent kernel with positive nouns, i.e., those semantically close to the images of interest, we arrive at formulating the affinity between images as a coupling of their visual proximity and semantic overlap. We show that this formulation amplifies within-cluster connections while suppressing spurious ones across clusters, hence encouraging block-diagonal structures. In addition, we present a regularized affinity diffusion mechanism that adaptively ensembles affinity matrices induced by different prompts. Extensive experiments on \textbf{16} benchmarks -- including classical, large-scale, fine-grained and domain-shifted datasets -- manifest that our method consistently outperforms the state-of-the-art by a large margin.
EExApp: GNN-Based Reinforcement Learning for Radio Unit Energy Optimization in 5G O-RAN
Feb 09, 2026With over 3.5 million 5G base stations deployed globally, their collective energy consumption (projected to exceed 131 TWh annually) raises significant concerns over both operational costs and environmental impacts. In this paper, we present EExAPP, a deep reinforcement learning (DRL)-based xApp for 5G Open Radio Access Network (O-RAN) that jointly optimizes radio unit (RU) sleep scheduling and distributed unit (DU) resource slicing. EExAPP uses a dual-actor-dual-critic Proximal Policy Optimization (PPO) architecture, with dedicated actor-critic pairs targeting energy efficiency and quality-of-service (QoS) compliance. A transformer-based encoder enables scalable handling of variable user equipment (UE) populations by encoding all-UE observations into fixed-dimensional representations. To coordinate the two optimization objectives, a bipartite Graph Attention Network (GAT) is used to modulate actor updates based on both critic outputs, enabling adaptive tradeoffs between power savings and QoS. We have implemented EExAPP and deployed it on a real-world 5G O-RAN testbed with live traffic, commercial RU and smartphones. Extensive over-the-air experiments and ablation studies confirm that EExAPP significantly outperforms existing methods in reducing the energy consumption of RU while maintaining QoS.
VGAS: Value-Guided Action-Chunk Selection for Few-Shot Vision-Language-Action Adaptation
Feb 07, 2026Vision--Language--Action (VLA) models bridge multimodal reasoning with physical control, but adapting them to new tasks with scarce demonstrations remains unreliable. While fine-tuned VLA policies often produce semantically plausible trajectories, failures often arise from unresolved geometric ambiguities, where near-miss action candidates lead to divergent execution outcomes under limited supervision. We study few-shot VLA adaptation from a \emph{generation--selection} perspective and propose a novel framework \textbf{VGAS} (\textbf{V}alue-\textbf{G}uided \textbf{A}ction-chunk \textbf{S}election). It performs inference-time best-of-$N$ selection to identify action chunks that are both semantically faithful and geometrically precise. Specifically, \textbf{VGAS} employs a finetuned VLA as a high-recall proposal generator and introduces the \textrm{Q-Chunk-Former}, a geometrically grounded Transformer critic to resolve fine-grained geometric ambiguities. In addition, we propose \textit{Explicit Geometric Regularization} (\texttt{EGR}), which explicitly shapes a discriminative value landscape to preserve action ranking resolution among near-miss candidates while mitigating value instability under scarce supervision. Experiments and theoretical analysis demonstrate that \textbf{VGAS} consistently improves success rates and robustness under limited demonstrations and distribution shifts. Our code is available at https://github.com/Jyugo-15/VGAS.
Bandwidth-constrained Variational Message Encoding for Cooperative Multi-agent Reinforcement Learning
Dec 11, 2025Graph-based multi-agent reinforcement learning (MARL) enables coordinated behavior under partial observability by modeling agents as nodes and communication links as edges. While recent methods excel at learning sparse coordination graphs-determining who communicates with whom-they do not address what information should be transmitted under hard bandwidth constraints. We study this bandwidth-limited regime and show that naive dimensionality reduction consistently degrades coordination performance. Hard bandwidth constraints force selective encoding, but deterministic projections lack mechanisms to control how compression occurs. We introduce Bandwidth-constrained Variational Message Encoding (BVME), a lightweight module that treats messages as samples from learned Gaussian posteriors regularized via KL divergence to an uninformative prior. BVME's variational framework provides principled, tunable control over compression strength through interpretable hyperparameters, directly constraining the representations used for decision-making. Across SMACv1, SMACv2, and MPE benchmarks, BVME achieves comparable or superior performance while using 67--83% fewer message dimensions, with gains most pronounced on sparse graphs where message quality critically impacts coordination. Ablations reveal U-shaped sensitivity to bandwidth, with BVME excelling at extreme ratios while adding minimal overhead.
Autonomous Source Knowledge Selection in Multi-Domain Adaptation
Dec 08, 2025Unsupervised multi-domain adaptation plays a key role in transfer learning by leveraging acquired rich source information from multiple source domains to solve target task from an unlabeled target domain. However, multiple source domains often contain much redundant or unrelated information which can harm transfer performance, especially when in massive-source domain settings. It is urgent to develop effective strategies for identifying and selecting the most transferable knowledge from massive source domains to address the target task. In this paper, we propose a multi-domain adaptation method named \underline{\textit{Auto}}nomous Source Knowledge \underline{\textit{S}}election (AutoS) to autonomosly select source training samples and models, enabling the prediction of target task using more relevant and transferable source information. The proposed method employs a density-driven selection strategy to choose source samples during training and to determine which source models should contribute to target prediction. Simulteneously, a pseudo-label enhancement module built on a pre-trained multimodal modal is employed to mitigate target label noise and improve self-supervision. Experiments on real-world datasets indicate the superiority of the proposed method.
SPAD: Seven-Source Token Probability Attribution with Syntactic Aggregation for Detecting Hallucinations in RAG
Dec 08, 2025Detecting hallucinations in Retrieval-Augmented Generation (RAG) remains a challenge. Prior approaches attribute hallucinations to a binary conflict between internal knowledge (stored in FFNs) and retrieved context. However, this perspective is incomplete, failing to account for the impact of other components in the generative process, such as the user query, previously generated tokens, the current token itself, and the final LayerNorm adjustment. To address this, we introduce SPAD. First, we mathematically attribute each token's probability into seven distinct sources: Query, RAG, Past, Current Token, FFN, Final LayerNorm, and Initial Embedding. This attribution quantifies how each source contributes to the generation of the current token. Then, we aggregate these scores by POS tags to quantify how different components drive specific linguistic categories. By identifying anomalies, such as Nouns relying on Final LayerNorm, SPAD effectively detects hallucinations. Extensive experiments demonstrate that SPAD achieves state-of-the-art performance
Autonomous Concept Drift Threshold Determination
Nov 13, 2025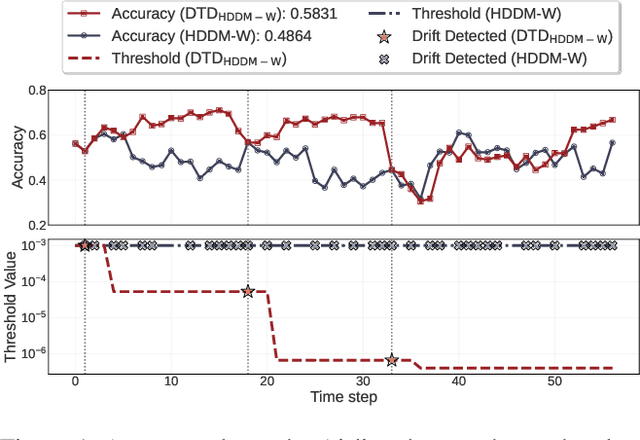
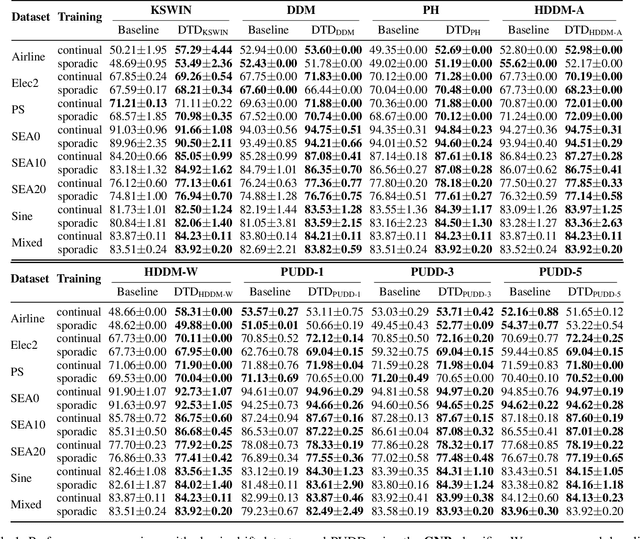
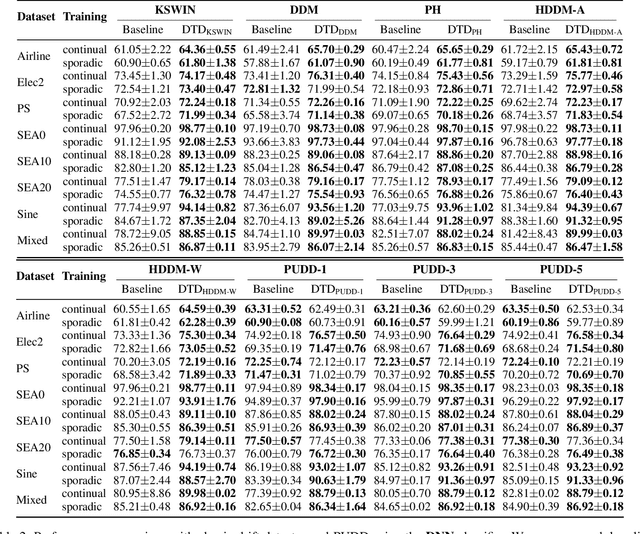
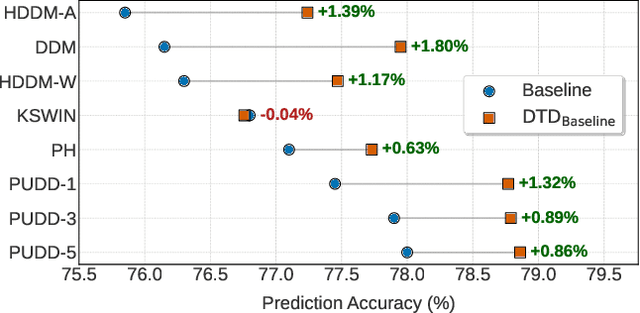
Existing drift detection methods focus on designing sensitive test statistics. They treat the detection threshold as a fixed hyperparameter, set once to balance false alarms and late detections, and applied uniformly across all datasets and over time. However, maintaining model performance is the key objective from the perspective of machine learning, and we observe that model performance is highly sensitive to this threshold. This observation inspires us to investigate whether a dynamic threshold could be provably better. In this paper, we prove that a threshold that adapts over time can outperform any single fixed threshold. The main idea of the proof is that a dynamic strategy, constructed by combining the best threshold from each individual data segment, is guaranteed to outperform any single threshold that apply to all segments. Based on the theorem, we propose a Dynamic Threshold Determination algorithm. It enhances existing drift detection frameworks with a novel comparison phase to inform how the threshold should be adjusted. Extensive experiments on a wide range of synthetic and real-world datasets, including both image and tabular data, validate that our approach substantially enhances the performance of state-of-the-art drift detectors.
Near-Real-Time Resource Slicing for QoS Optimization in 5G O-RAN using Deep Reinforcement Learning
Sep 17, 2025Open-Radio Access Network (O-RAN) has become an important paradigm for 5G and beyond radio access networks. This paper presents an xApp called xSlice for the Near-Real-Time (Near-RT) RAN Intelligent Controller (RIC) of 5G O-RANs. xSlice is an online learning algorithm that adaptively adjusts MAC-layer resource allocation in response to dynamic network states, including time-varying wireless channel conditions, user mobility, traffic fluctuations, and changes in user demand. To address these network dynamics, we first formulate the Quality-of-Service (QoS) optimization problem as a regret minimization problem by quantifying the QoS demands of all traffic sessions through weighting their throughput, latency, and reliability. We then develop a deep reinforcement learning (DRL) framework that utilizes an actor-critic model to combine the advantages of both value-based and policy-based updating methods. A graph convolutional network (GCN) is incorporated as a component of the DRL framework for graph embedding of RAN data, enabling xSlice to handle a dynamic number of traffic sessions. We have implemented xSlice on an O-RAN testbed with 10 smartphones and conducted extensive experiments to evaluate its performance in realistic scenarios. Experimental results show that xSlice can reduce performance regret by 67% compared to the state-of-the-art solutions. Source code is available on GitHub [1].