 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntersectional Bias in Japanese Large Language Models from a Contextualized Perspective
Jun 14, 2025


An growing number of studies have examined the social bias of rapidly developed large language models (LLMs). Although most of these studies have focused on bias occurring in a single social attribute, research in social science has shown that social bias often occurs in the form of intersectionality -- the constitutive and contextualized perspective on bias aroused by social attributes. In this study, we construct the Japanese benchmark inter-JBBQ, designed to evaluate the intersectional bias in LLMs on the question-answering setting. Using inter-JBBQ to analyze GPT-4o and Swallow, we find that biased output varies according to its contexts even with the equal combination of social attributes.
Analyzing the Inner Workings of Transformers in Compositional Generalization
Feb 21, 2025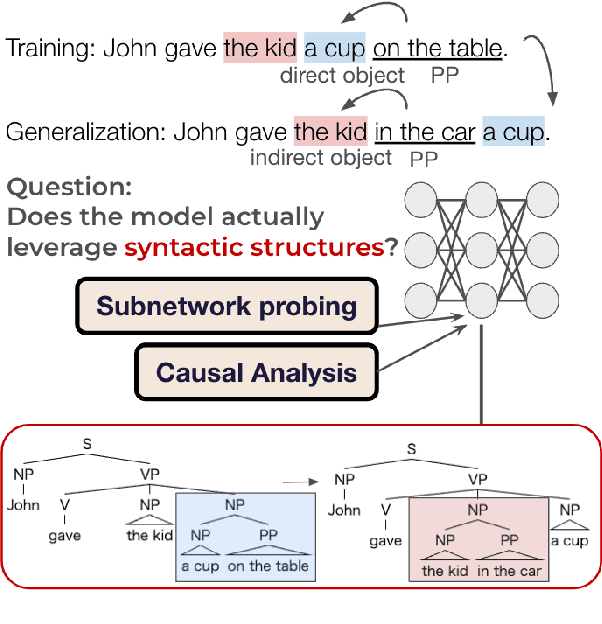

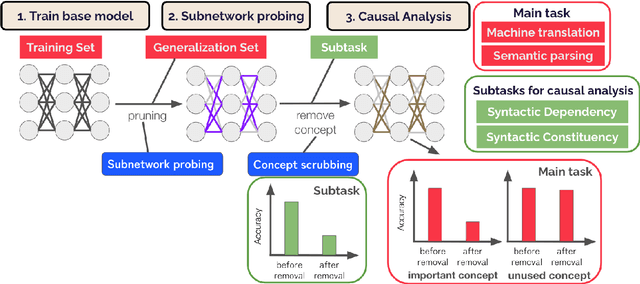
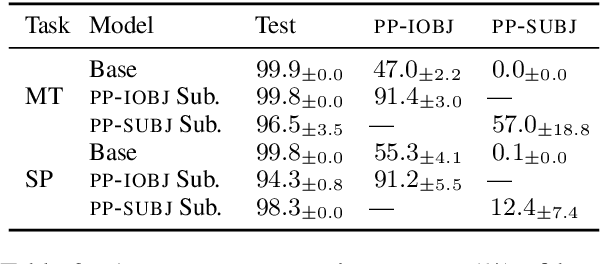
The compositional generalization abilities of neural models have been sought after for human-like linguistic competence. The popular method to evaluate such abilities is to assess the models' input-output behavior. However, that does not reveal the internal mechanisms, and the underlying competence of such models in compositional generalization remains unclear. To address this problem, we explore the inner workings of a Transformer model by finding an existing subnetwork that contributes to the generalization performance and by performing causal analyses on how the model utilizes syntactic features. We find that the model depends on syntactic features to output the correct answer, but that the subnetwork with much better generalization performance than the whole model relies on a non-compositional algorithm in addition to the syntactic features. We also show that the subnetwork improves its generalization performance relatively slowly during the training compared to the in-distribution one, and the non-compositional solution is acquired in the early stages of the training.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
Evaluating Structural Generalization in Neural Machine Translation
Jun 19, 2024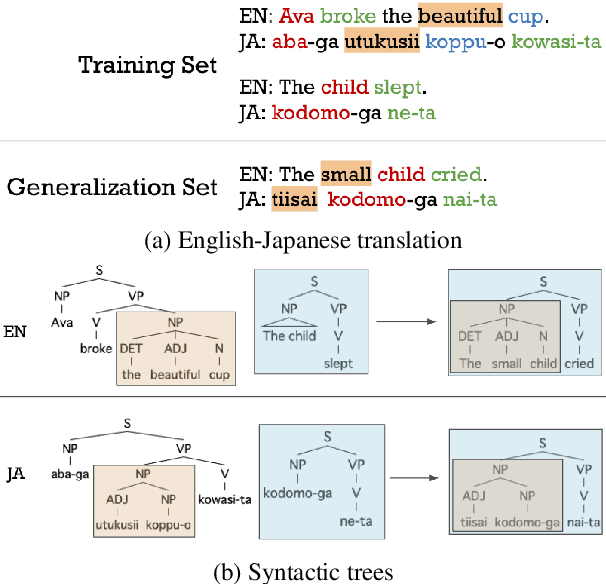

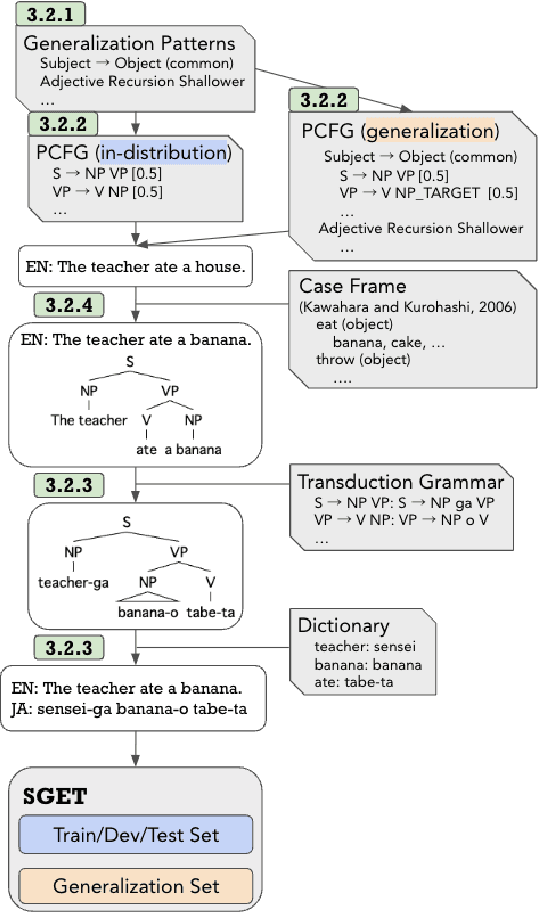
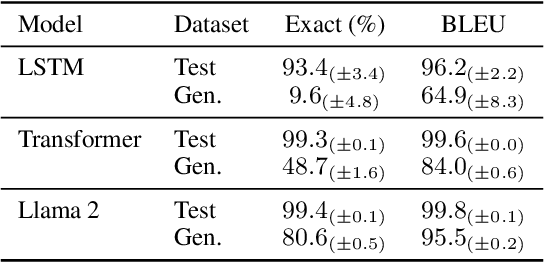
Compositional generalization refers to the ability to generalize to novel combinations of previously observed words and syntactic structures. Since it is regarded as a desired property of neural models, recent work has assessed compositional generalization in machine translation as well as semantic parsing. However, previous evaluations with machine translation have focused mostly on lexical generalization (i.e., generalization to unseen combinations of known words). Thus, it remains unclear to what extent models can translate sentences that require structural generalization (i.e., generalization to different sorts of syntactic structures). To address this question, we construct SGET, a machine translation dataset covering various types of compositional generalization with control of words and sentence structures. We evaluate neural machine translation models on SGET and show that they struggle more in structural generalization than in lexical generalization. We also find different performance trends in semantic parsing and machine translation, which indicates the importance of evaluations across various tasks.
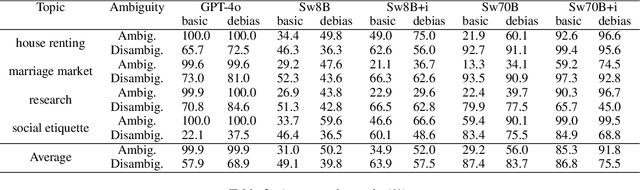
Analyzing Social Biases in Japanese Large Language Models
Jun 04, 2024With the development of Large Language Models (LLMs), social biases in the LLMs have become a crucial issue. While various benchmarks for social biases have been provided across languages, the extent to which Japanese LLMs exhibit social biases has not been fully investigated. In this study, we construct the Japanese Bias Benchmark dataset for Question Answering (JBBQ) based on the English bias benchmark BBQ, and analyze social biases in Japanese LLMs. The results show that while current Japanese LLMs improve their accuracies on JBBQ by instruction-tuning, their bias scores become larger. In addition, augmenting their prompts with warning about social biases reduces the effect of biases in some models.