 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Social Biases in Japanese Large Language Models
Jun 04, 2024With the development of Large Language Models (LLMs), social biases in the LLMs have become a crucial issue. While various benchmarks for social biases have been provided across languages, the extent to which Japanese LLMs exhibit social biases has not been fully investigated. In this study, we construct the Japanese Bias Benchmark dataset for Question Answering (JBBQ) based on the English bias benchmark BBQ, and analyze social biases in Japanese LLMs. The results show that while current Japanese LLMs improve their accuracies on JBBQ by instruction-tuning, their bias scores become larger. In addition, augmenting their prompts with warning about social biases reduces the effect of biases in some models.
Constructing Multilingual Code Search Dataset Using Neural Machine Translation
Jun 27, 2023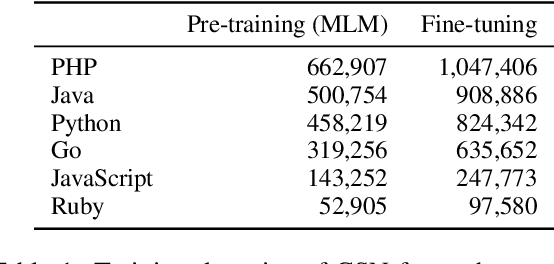
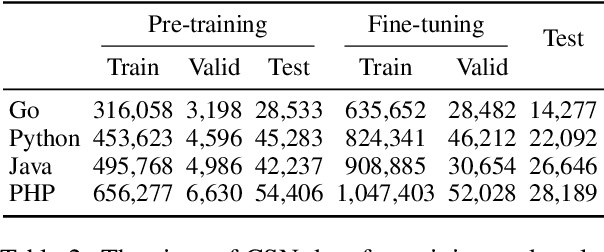
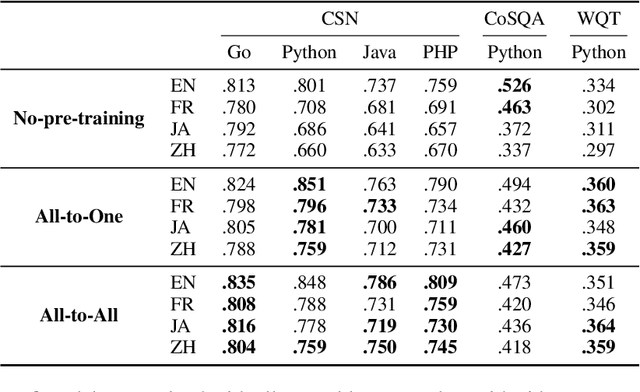
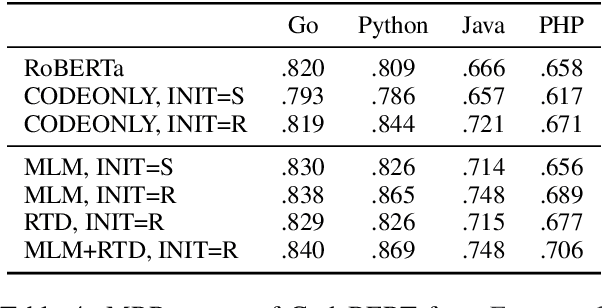
Code search is a task to find programming codes that semantically match the given natural language queries. Even though some of the existing datasets for this task are multilingual on the programming language side, their query data are only in English. In this research, we create a multilingual code search dataset in four natural and four programming languages using a neural machine translation model. Using our dataset, we pre-train and fine-tune the Transformer-based models and then evaluate them on multiple code search test sets. Our results show that the model pre-trained with all natural and programming language data has performed best in most cases. By applying back-translation data filtering to our dataset, we demonstrate that the translation quality affects the model's performance to a certain extent, but the data size matters more.
Analyzing Syntactic Generalization Capacity of Pre-trained Language Models on Japanese Honorific Conversion
Jun 05, 2023Using Japanese honorifics is challenging because it requires not only knowledge of the grammatical rules but also contextual information, such as social relationships. It remains unclear whether pre-trained large language models (LLMs) can flexibly handle Japanese honorifics like humans. To analyze this, we introduce an honorific conversion task that considers social relationships among people mentioned in a conversation. We construct a Japanese honorifics dataset from problem templates of various sentence structures to investigate the syntactic generalization capacity of GPT-3, one of the leading LLMs, on this task under two settings: fine-tuning and prompt learning. Our results showed that the fine-tuned GPT-3 performed better in a context-aware honorific conversion task than the prompt-based one. The fine-tuned model demonstrated overall syntactic generalizability towards compound honorific sentences, except when tested with the data involving direct speech.