 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeciesism in Natural Language Processing Research
Oct 18, 2024Natural Language Processing (NLP) research on AI Safety and social bias in AI has focused on safety for humans and social bias against human minorities. However, some AI ethicists have argued that the moral significance of nonhuman animals has been ignored in AI research. Therefore, the purpose of this study is to investigate whether there is speciesism, i.e., discrimination against nonhuman animals, in NLP research. First, we explain why nonhuman animals are relevant in NLP research. Next, we survey the findings of existing research on speciesism in NLP researchers, data, and models and further investigate this problem in this study. The findings of this study suggest that speciesism exists within researchers, data, and models, respectively. Specifically, our survey and experiments show that (a) among NLP researchers, even those who study social bias in AI, do not recognize speciesism or speciesist bias; (b) among NLP data, speciesist bias is inherent in the data annotated in the datasets used to evaluate NLP models; (c) OpenAI GPTs, recent NLP models, exhibit speciesist bias by default. Finally, we discuss how we can reduce speciesism in NLP research.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
Analyzing Social Biases in Japanese Large Language Models
Jun 04, 2024With the development of Large Language Models (LLMs), social biases in the LLMs have become a crucial issue. While various benchmarks for social biases have been provided across languages, the extent to which Japanese LLMs exhibit social biases has not been fully investigated. In this study, we construct the Japanese Bias Benchmark dataset for Question Answering (JBBQ) based on the English bias benchmark BBQ, and analyze social biases in Japanese LLMs. The results show that while current Japanese LLMs improve their accuracies on JBBQ by instruction-tuning, their bias scores become larger. In addition, augmenting their prompts with warning about social biases reduces the effect of biases in some models.
Towards Theory-based Moral AI: Moral AI with Aggregating Models Based on Normative Ethical Theory
Jun 20, 2023Moral AI has been studied in the fields of philosophy and artificial intelligence. Although most existing studies are only theoretical, recent developments in AI have made it increasingly necessary to implement AI with morality. On the other hand, humans are under the moral uncertainty of not knowing what is morally right. In this paper, we implement the Maximizing Expected Choiceworthiness (MEC) algorithm, which aggregates outputs of models based on three normative theories of normative ethics to generate the most appropriate output. MEC is a method for making appropriate moral judgments under moral uncertainty. Our experimental results suggest that the output of MEC correlates to some extent with commonsense morality and that MEC can produce equally or more appropriate output than existing methods.
Speciesist Language and Nonhuman Animal Bias in English Masked Language Models
Mar 15, 2022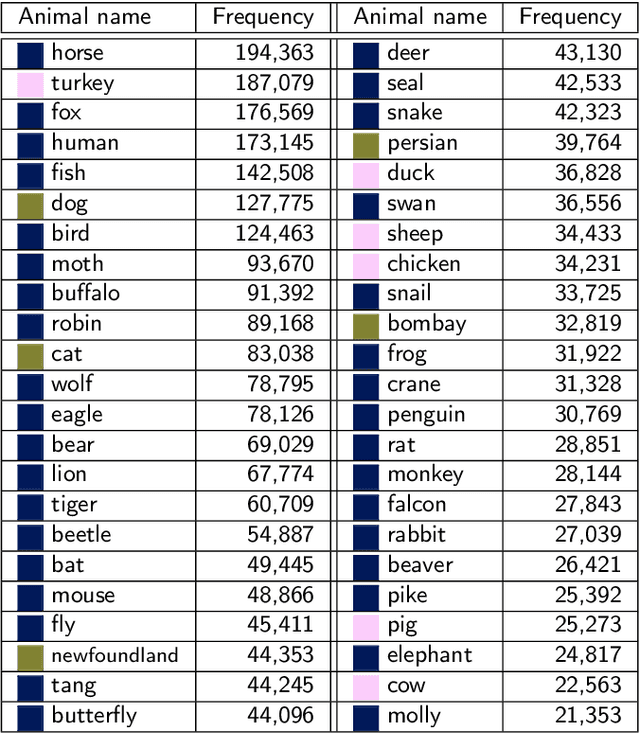
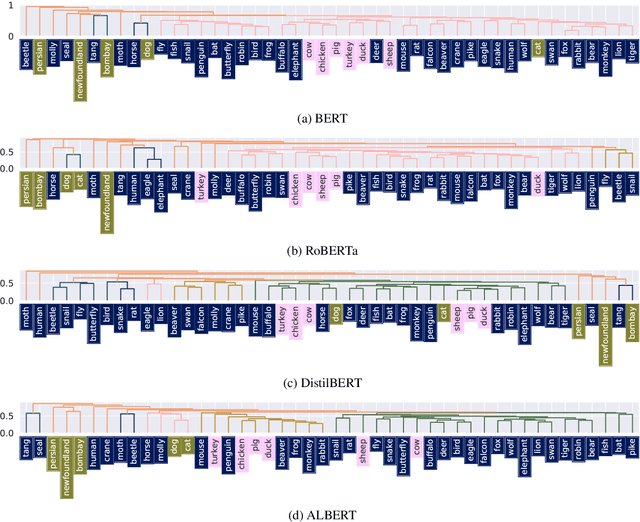
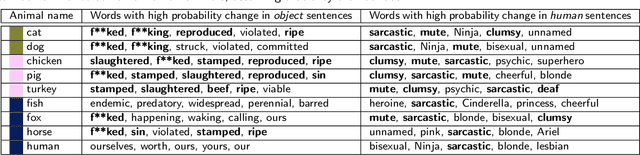
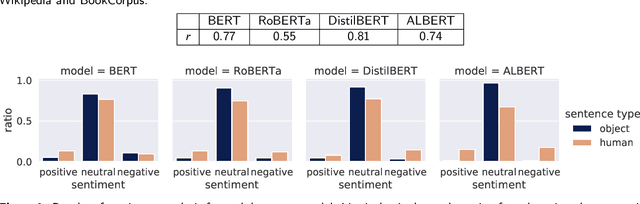
Various existing studies have analyzed what social biases are inherited by NLP models. These biases may directly or indirectly harm people, therefore previous studies have focused only on human attributes. If the social biases in NLP models can be indirectly harmful to humans involved, then the models can also indirectly harm nonhuman animals. However, until recently no research on social biases in NLP regarding nonhumans existed. In this paper, we analyze biases to nonhuman animals, i.e. speciesist bias, inherent in English Masked Language Models. We analyze this bias using template-based and corpus-extracted sentences which contain speciesist (or non-speciesist) language, to show that these models tend to associate harmful words with nonhuman animals. Our code for reproducing the experiments will be made available on GitHub.