 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Theory-based Moral AI: Moral AI with Aggregating Models Based on Normative Ethical Theory
Jun 20, 2023Moral AI has been studied in the fields of philosophy and artificial intelligence. Although most existing studies are only theoretical, recent developments in AI have made it increasingly necessary to implement AI with morality. On the other hand, humans are under the moral uncertainty of not knowing what is morally right. In this paper, we implement the Maximizing Expected Choiceworthiness (MEC) algorithm, which aggregates outputs of models based on three normative theories of normative ethics to generate the most appropriate output. MEC is a method for making appropriate moral judgments under moral uncertainty. Our experimental results suggest that the output of MEC correlates to some extent with commonsense morality and that MEC can produce equally or more appropriate output than existing methods.
Speciesist Language and Nonhuman Animal Bias in English Masked Language Models
Mar 15, 2022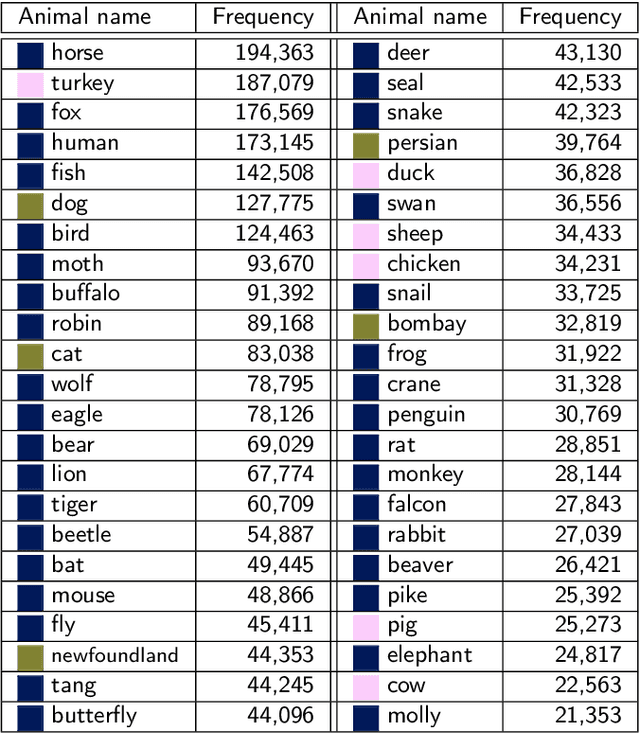
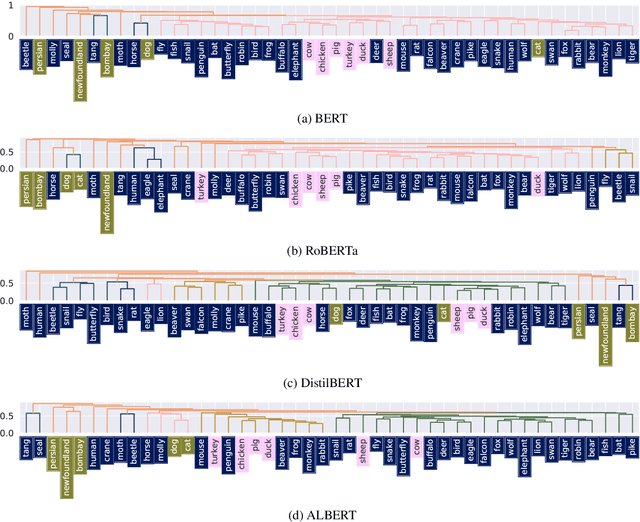
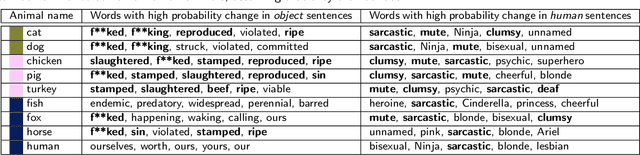
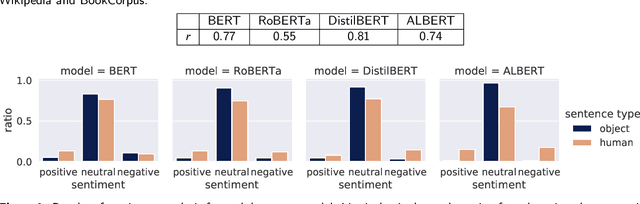
Various existing studies have analyzed what social biases are inherited by NLP models. These biases may directly or indirectly harm people, therefore previous studies have focused only on human attributes. If the social biases in NLP models can be indirectly harmful to humans involved, then the models can also indirectly harm nonhuman animals. However, until recently no research on social biases in NLP regarding nonhumans existed. In this paper, we analyze biases to nonhuman animals, i.e. speciesist bias, inherent in English Masked Language Models. We analyze this bias using template-based and corpus-extracted sentences which contain speciesist (or non-speciesist) language, to show that these models tend to associate harmful words with nonhuman animals. Our code for reproducing the experiments will be made available on GitHub.
In the Service of Online Order: Tackling Cyber-Bullying with Machine Learning and Affect Analysis
Mar 04, 2022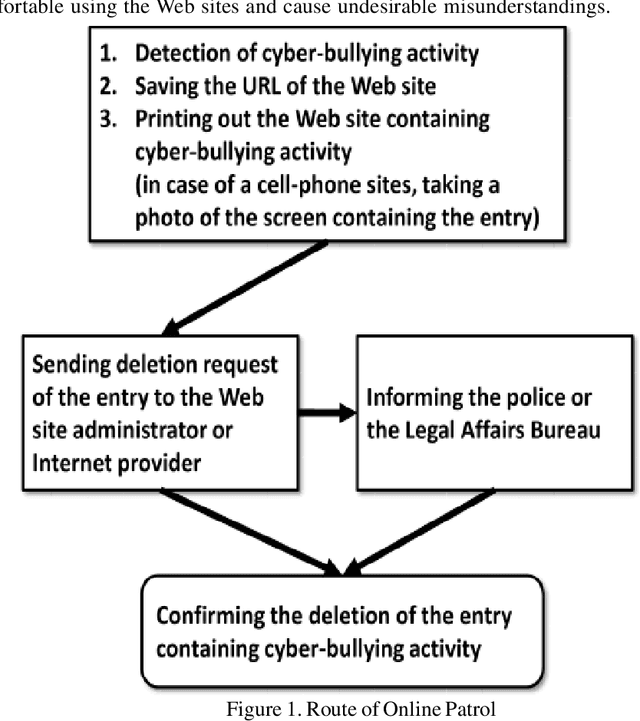
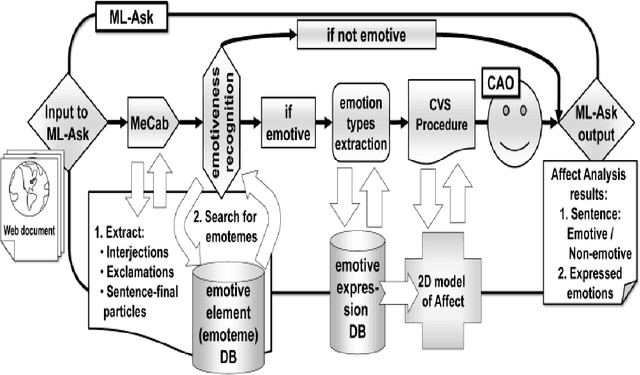
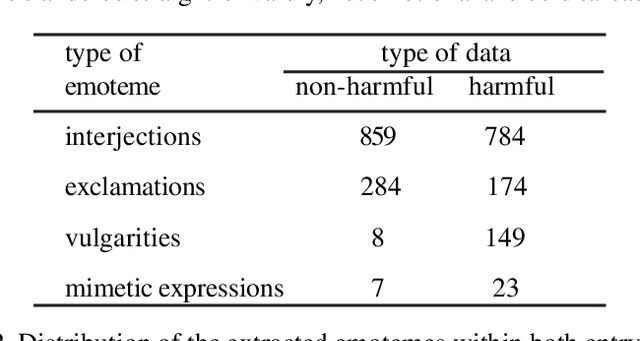
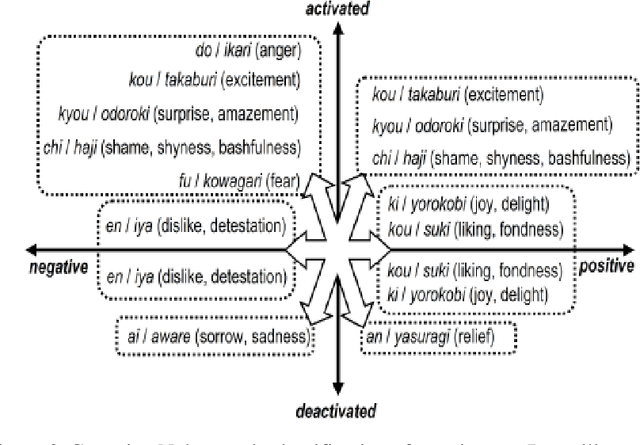
One of the burning problems lately in Japan has been cyber-bullying, or slandering and bullying people online. The problem has been especially noticed on unofficial Web sites of Japanese schools. Volunteers consisting of school personnel and PTA (Parent-Teacher Association) members have started Online Patrol to spot malicious contents within Web forums and blogs. In practise, Online Patrol assumes reading through the whole Web contents, which is a task difficult to perform manually. With this paper we introduce a research intended to help PTA members perform Online Patrol more efficiently. We aim to develop a set of tools that can automatically detect malicious entries and report them to PTA members. First, we collected cyber-bullying data from unofficial school Web sites. Then we performed analysis of this data in two ways. Firstly, we analysed the entries with a multifaceted affect analysis system in order to find distinctive features for cyber-bullying and apply them to a machine learning classifier. Secondly, we applied a SVM based machine learning method to train a classifier for detection of cyber-bullying. The system was able to classify cyber-bullying entries with 88.2% of balanced F-score.
* 12 pages, 11 tables, 6 figures
Summarizing Utterances from Japanese Assembly Minutes using Political Sentence-BERT-based Method for QA Lab-PoliInfo-2 Task of NTCIR-15
Oct 22, 2020
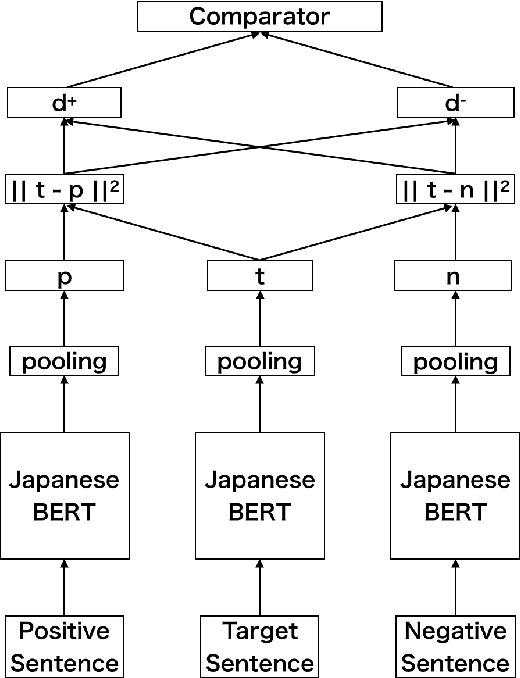
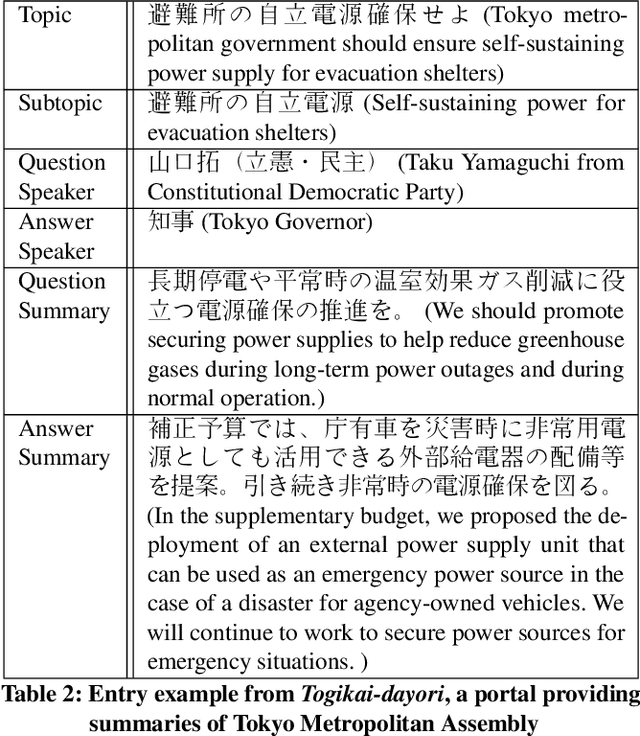

There are many discussions held during political meetings, and a large number of utterances for various topics is included in their transcripts. We need to read all of them if we want to follow speakers\' intentions or opinions about a given topic. To avoid such a costly and time-consuming process to grasp often longish discussions, NLP researchers work on generating concise summaries of utterances. Summarization subtask in QA Lab-PoliInfo-2 task of the NTCIR-15 addresses this problem for Japanese utterances in assembly minutes, and our team (SKRA) participated in this subtask. As a first step for summarizing utterances, we created a new pre-trained sentence embedding model, i.e. the Japanese Political Sentence-BERT. With this model, we summarize utterances without labelled data. This paper describes our approach to solving the task and discusses its results.