 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoSteer: Faithful Chain-of-Thought Steering via Latent Manifold Gradients
Jan 15, 2026Recent advances in Large Language Models (LLMs) have improved multi-step reasoning. Most approaches rely on Chain-of-Thought (CoT) rationales. Previous studies have shown that LLMs often generate logically inconsistent reasoning steps even when their final answers are correct. These inconsistencies reduce the reliability of step-level reasoning. We propose GeoSteer, a manifold-based framework that improves the quality of intermediate reasoning. The method consists of: (1) constructing a CoT dataset with segment-level scores, (2) training a Variational Autoencoder (VAE) model and a quality estimation model to learn a low-dimensional manifold of high-quality CoT trajectories, and (3) steering hidden states of target LLMs toward higher-quality regions in the latent space. This update in a latent space behaves like a natural-gradient adjustment in the original hidden-state space. It ensures geometrically coherent steering. We evaluate GeoSteer on the GSM8k dataset using the Qwen3 series. We measure via answer accuracy and overall reasoning performance. GeoSteer improved the exact match accuracy by up to 2.6 points. It also enhanced the pairwise win rate by 5.3 points. These results indicate that GeoSteer provides an effective and controllable mechanism for improving the quality of intermediate reasoning in LLMs.
A Hybrid Search for Complex Table Question Answering in Securities Report
Nov 12, 2025Recently, Large Language Models (LLMs) are gaining increased attention in the domain of Table Question Answering (TQA), particularly for extracting information from tables in documents. However, directly entering entire tables as long text into LLMs often leads to incorrect answers because most LLMs cannot inherently capture complex table structures. In this paper, we propose a cell extraction method for TQA without manual identification, even for complex table headers. Our approach estimates table headers by computing similarities between a given question and individual cells via a hybrid retrieval mechanism that integrates a language model and TF-IDF. We then select as the answer the cells at the intersection of the most relevant row and column. Furthermore, the language model is trained using contrastive learning on a small dataset of question-header pairs to enhance performance. We evaluated our approach in the TQA dataset from the U4 shared task at NTCIR-18. The experimental results show that our pipeline achieves an accuracy of 74.6\%, outperforming existing LLMs such as GPT-4o mini~(63.9\%). In the future, although we used traditional encoder models for retrieval in this study, we plan to incorporate more efficient text-search models to improve performance and narrow the gap with human evaluation results.
Bias Vector: Mitigating Biases in Language Models with Task Arithmetic Approach
Dec 16, 2024The use of language models (LMs) has increased considerably in recent years, and the biases and stereotypes in training data that are reflected in the LM outputs are causing social problems. In this paper, inspired by the task arithmetic, we propose the ``Bias Vector'' method for the mitigation of these LM biases. The Bias Vector method does not require manually created debiasing data. The three main steps of our approach involve: (1) continual training the pre-trained LMs on biased data using masked language modeling; (2) constructing the Bias Vector as the difference between the weights of the biased LMs and those of pre-trained LMs; and (3) subtracting the Bias Vector from the weights of the pre-trained LMs for debiasing. We evaluated the Bias Vector method on the SEAT across three LMs and confirmed an average improvement of 0.177 points. We demonstrated that the Bias Vector method does not degrade the LM performance on downstream tasks in the GLUE benchmark. In addition, we examined the impact of scaling factors, which control the magnitudes of Bias Vectors, with effect sizes on the SEAT and conducted a comprehensive evaluation of our debiased LMs across both the SEAT and GLUE benchmarks.
Summarizing Utterances from Japanese Assembly Minutes using Political Sentence-BERT-based Method for QA Lab-PoliInfo-2 Task of NTCIR-15
Oct 22, 2020
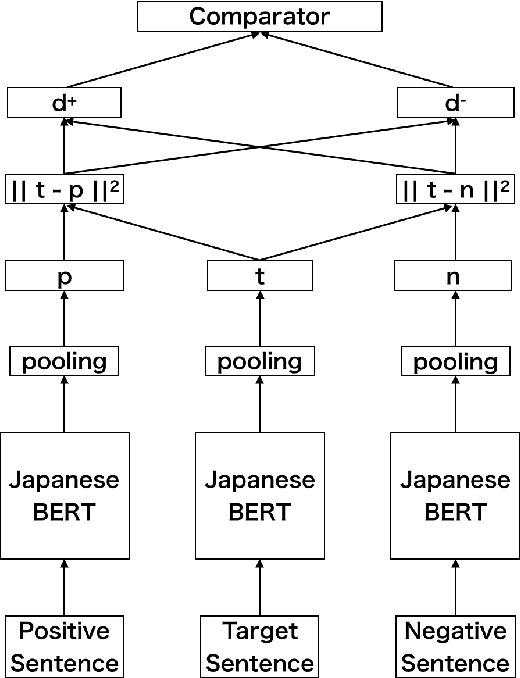
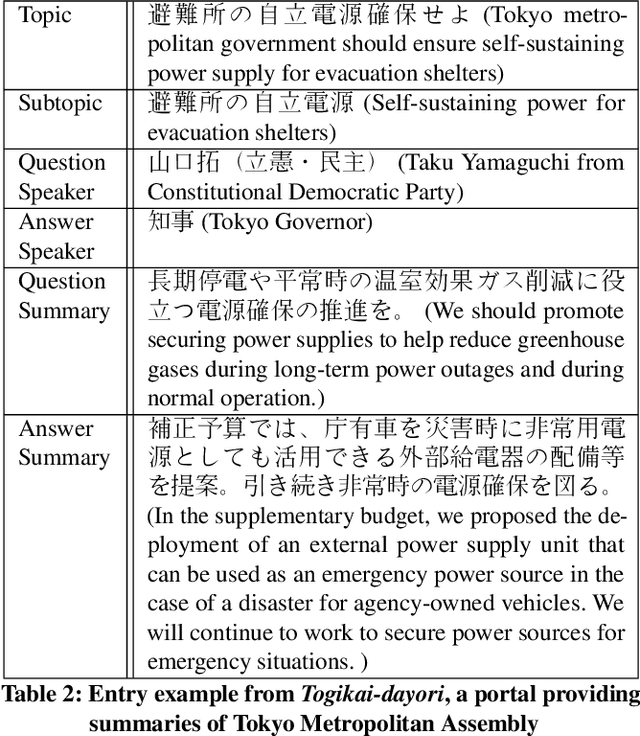

There are many discussions held during political meetings, and a large number of utterances for various topics is included in their transcripts. We need to read all of them if we want to follow speakers\' intentions or opinions about a given topic. To avoid such a costly and time-consuming process to grasp often longish discussions, NLP researchers work on generating concise summaries of utterances. Summarization subtask in QA Lab-PoliInfo-2 task of the NTCIR-15 addresses this problem for Japanese utterances in assembly minutes, and our team (SKRA) participated in this subtask. As a first step for summarizing utterances, we created a new pre-trained sentence embedding model, i.e. the Japanese Political Sentence-BERT. With this model, we summarize utterances without labelled data. This paper describes our approach to solving the task and discusses its results.