 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummarizing Utterances from Japanese Assembly Minutes using Political Sentence-BERT-based Method for QA Lab-PoliInfo-2 Task of NTCIR-15
Paper and Code

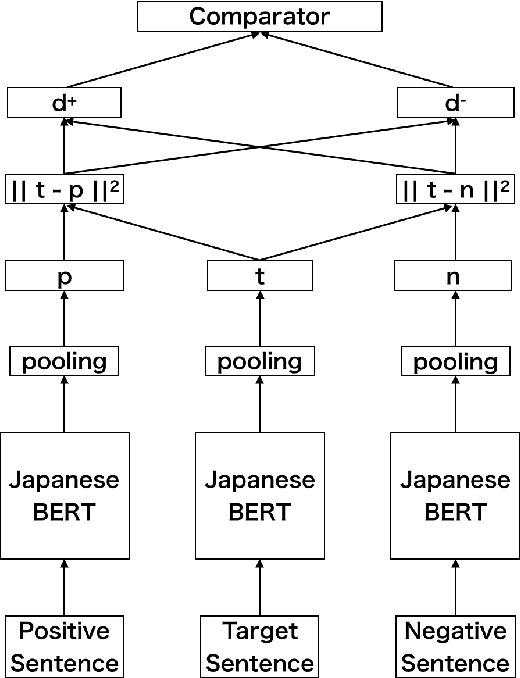
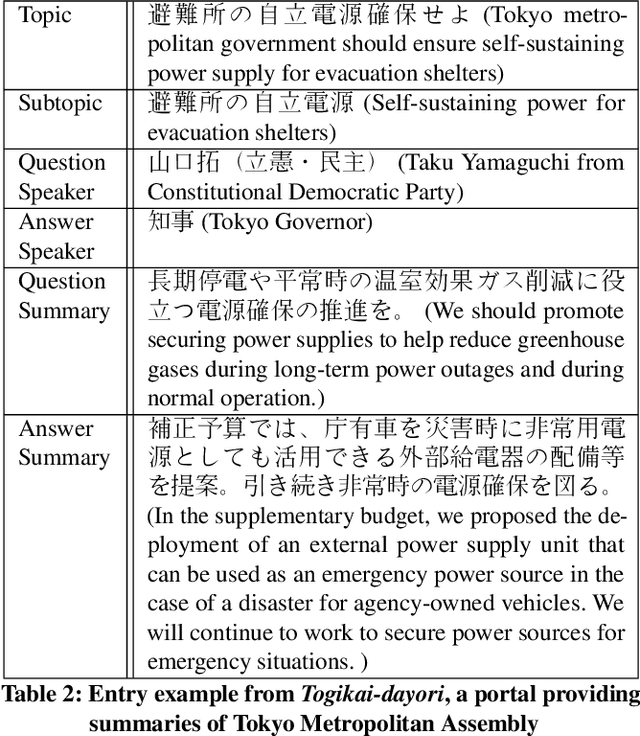

There are many discussions held during political meetings, and a large number of utterances for various topics is included in their transcripts. We need to read all of them if we want to follow speakers\' intentions or opinions about a given topic. To avoid such a costly and time-consuming process to grasp often longish discussions, NLP researchers work on generating concise summaries of utterances. Summarization subtask in QA Lab-PoliInfo-2 task of the NTCIR-15 addresses this problem for Japanese utterances in assembly minutes, and our team (SKRA) participated in this subtask. As a first step for summarizing utterances, we created a new pre-trained sentence embedding model, i.e. the Japanese Political Sentence-BERT. With this model, we summarize utterances without labelled data. This paper describes our approach to solving the task and discusses its results.