 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of LLM Memorization at Statistical and Internal Levels: Cross-Model Commonalities and Model-Specific Signatures
Mar 23, 2026Memorization is a fundamental component of intelligence for both humans and LLMs. However, while LLM performance scales rapidly, our understanding of memorization lags. Due to limited access to the pre-training data of LLMs, most previous studies focus on a single model series, leading to isolated observations among series, making it unclear which findings are general or specific. In this study, we collect multiple model series (Pythia, OpenLLaMa, StarCoder, OLMo1/2/3) and analyze their shared or unique memorization behavior at both the statistical and internal levels, connecting individual observations while showing new findings. At the statistical level, we reveal that the memorization rate scales log-linearly with model size, and memorized sequences can be further compressed. Further analysis demonstrated a shared frequency and domain distribution pattern for memorized sequences. However, different models also show individual features under the above observations. At the internal level, we find that LLMs can remove certain injected perturbations, while memorized sequences are more sensitive. By decoding middle layers and attention head ablation, we revealed the general decoding process and shared important heads for memorization. However, the distribution of those important heads differs between families, showing a unique family-level feature. Through bridging various experiments and revealing new findings, this study paves the way for a universal and fundamental understanding of memorization in LLM.
Intersectional Bias in Japanese Large Language Models from a Contextualized Perspective
Jun 14, 2025

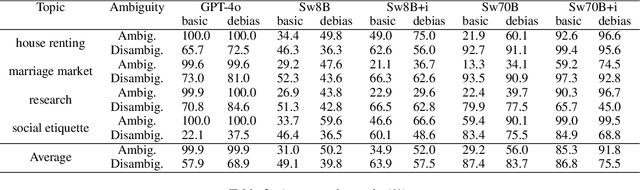

An growing number of studies have examined the social bias of rapidly developed large language models (LLMs). Although most of these studies have focused on bias occurring in a single social attribute, research in social science has shown that social bias often occurs in the form of intersectionality -- the constitutive and contextualized perspective on bias aroused by social attributes. In this study, we construct the Japanese benchmark inter-JBBQ, designed to evaluate the intersectional bias in LLMs on the question-answering setting. Using inter-JBBQ to analyze GPT-4o and Swallow, we find that biased output varies according to its contexts even with the equal combination of social attributes.
A Statistical and Multi-Perspective Revisiting of the Membership Inference Attack in Large Language Models
Dec 18, 2024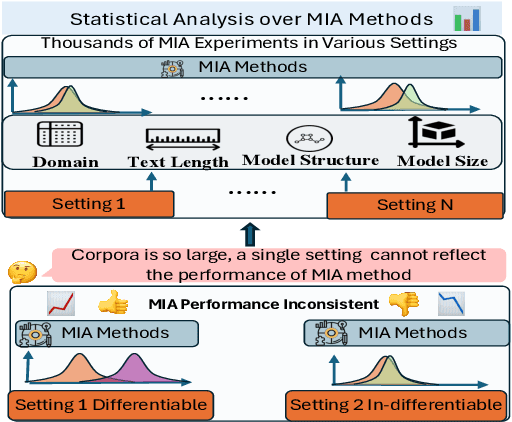



The lack of data transparency in Large Language Models (LLMs) has highlighted the importance of Membership Inference Attack (MIA), which differentiates trained (member) and untrained (non-member) data. Though it shows success in previous studies, recent research reported a near-random performance in different settings, highlighting a significant performance inconsistency. We assume that a single setting doesn't represent the distribution of the vast corpora, causing members and non-members with different distributions to be sampled and causing inconsistency. In this study, instead of a single setting, we statistically revisit MIA methods from various settings with thousands of experiments for each MIA method, along with study in text feature, embedding, threshold decision, and decoding dynamics of members and non-members. We found that (1) MIA performance improves with model size and varies with domains, while most methods do not statistically outperform baselines, (2) Though MIA performance is generally low, a notable amount of differentiable member and non-member outliers exists and vary across MIA methods, (3) Deciding a threshold to separate members and non-members is an overlooked challenge, (4) Text dissimilarity and long text benefit MIA performance, (5) Differentiable or not is reflected in the LLM embedding, (6) Member and non-members show different decoding dynamics.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
A Multi-Perspective Analysis of Memorization in Large Language Models
May 19, 2024Large Language Models (LLMs), trained on massive corpora with billions of parameters, show unprecedented performance in various fields. Though surprised by their excellent performances, researchers also noticed some special behaviors of those LLMs. One of those behaviors is memorization, in which LLMs can generate the same content used to train them. Though previous research has discussed memorization, the memorization of LLMs still lacks explanation, especially the cause of memorization and the dynamics of generating them. In this research, we comprehensively discussed memorization from various perspectives and extended the discussion scope to not only just the memorized content but also less and unmemorized content. Through various studies, we found that: (1) Through experiments, we revealed the relation of memorization between model size, continuation size, and context size. Further, we showed how unmemorized sentences transition to memorized sentences. (2) Through embedding analysis, we showed the distribution and decoding dynamics across model size in embedding space for sentences with different memorization scores. The n-gram statistics analysis presents d (3) An analysis over n-gram and entropy decoding dynamics discovered a boundary effect when the model starts to generate memorized sentences or unmemorized sentences. (4)We trained a Transformer model to predict the memorization of different models, showing that it is possible to predict memorizations by context.
Sound of Story: Multi-modal Storytelling with Audio
Oct 30, 2023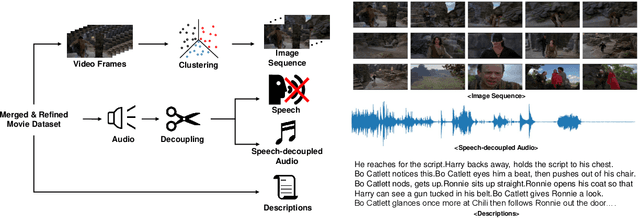



Storytelling is multi-modal in the real world. When one tells a story, one may use all of the visualizations and sounds along with the story itself. However, prior studies on storytelling datasets and tasks have paid little attention to sound even though sound also conveys meaningful semantics of the story. Therefore, we propose to extend story understanding and telling areas by establishing a new component called "background sound" which is story context-based audio without any linguistic information. For this purpose, we introduce a new dataset, called "Sound of Story (SoS)", which has paired image and text sequences with corresponding sound or background music for a story. To the best of our knowledge, this is the largest well-curated dataset for storytelling with sound. Our SoS dataset consists of 27,354 stories with 19.6 images per story and 984 hours of speech-decoupled audio such as background music and other sounds. As benchmark tasks for storytelling with sound and the dataset, we propose retrieval tasks between modalities, and audio generation tasks from image-text sequences, introducing strong baselines for them. We believe the proposed dataset and tasks may shed light on the multi-modal understanding of storytelling in terms of sound. Downloading the dataset and baseline codes for each task will be released in the link: https://github.com/Sosdatasets/SoS_Dataset.