 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling
Apr 08, 2026Building world models with spatial consistency and real-time interactivity remains a fundamental challenge in computer vision. Current video generation paradigms often struggle with a lack of spatial persistence and insufficient visual realism, making it difficult to support seamless navigation in complex environments. To address these challenges, we propose INSPATIO-WORLD, a novel real-time framework capable of recovering and generating high-fidelity, dynamic interactive scenes from a single reference video. At the core of our approach is a Spatiotemporal Autoregressive (STAR) architecture, which enables consistent and controllable scene evolution through two tightly coupled components: Implicit Spatiotemporal Cache aggregates reference and historical observations into a latent world representation, ensuring global consistency during long-horizon navigation; Explicit Spatial Constraint Module enforces geometric structure and translates user interactions into precise and physically plausible camera trajectories. Furthermore, we introduce Joint Distribution Matching Distillation (JDMD). By using real-world data distributions as a regularizing guide, JDMD effectively overcomes the fidelity degradation typically caused by over-reliance on synthetic data. Extensive experiments demonstrate that INSPATIO-WORLD significantly outperforms existing state-of-the-art (SOTA) models in spatial consistency and interaction precision, ranking first among real-time interactive methods on the WorldScore-Dynamic benchmark, and establishing a practical pipeline for navigating 4D environments reconstructed from monocular videos.
LaDy: Lagrangian-Dynamic Informed Network for Skeleton-based Action Segmentation via Spatial-Temporal Modulation
Mar 25, 2026Skeleton-based Temporal Action Segmentation (STAS) aims to densely parse untrimmed skeletal sequences into frame-level action categories. However, existing methods, while proficient at capturing spatio-temporal kinematics, neglect the underlying physical dynamics that govern human motion. This oversight limits inter-class discriminability between actions with similar kinematics but distinct dynamic intents, and hinders precise boundary localization where dynamic force profiles shift. To address these, we propose the Lagrangian-Dynamic Informed Network (LaDy), a framework integrating principles of Lagrangian dynamics into the segmentation process. Specifically, LaDy first computes generalized coordinates from joint positions and then estimates Lagrangian terms under physical constraints to explicitly synthesize the generalized forces. To further ensure physical coherence, our Energy Consistency Loss enforces the work-energy theorem, aligning kinetic energy change with the work done by the net force. The learned dynamics then drive a Spatio-Temporal Modulation module: Spatially, generalized forces are fused with spatial representations to provide more discriminative semantics. Temporally, salient dynamic signals are constructed for temporal gating, thereby significantly enhancing boundary awareness. Experiments on challenging datasets show that LaDy achieves state-of-the-art performance, validating the integration of physical dynamics for action segmentation. Code is available at https://github.com/HaoyuJi/LaDy.
Spectral Scalpel: Amplifying Adjacent Action Discrepancy via Frequency-Selective Filtering for Skeleton-Based Action Segmentation
Mar 25, 2026Skeleton-based Temporal Action Segmentation (STAS) seeks to densely segment and classify diverse actions within long, untrimmed skeletal motion sequences. However, existing STAS methodologies face challenges of limited inter-class discriminability and blurred segmentation boundaries, primarily due to insufficient distinction of spatio-temporal patterns between adjacent actions. To address these limitations, we propose Spectral Scalpel, a frequency-selective filtering framework aimed at suppressing shared frequency components between adjacent distinct actions while amplifying their action-specific frequencies, thereby enhancing inter-action discrepancies and sharpening transition boundaries. Specifically, Spectral Scalpel employs adaptive multi-scale spectral filters as scalpels to edit frequency spectra, coupled with a discrepancy loss between adjacent actions serving as the surgical objective. This design amplifies representational disparities between neighboring actions, effectively mitigating boundary localization ambiguities and inter-class confusion. Furthermore, complementing long-term temporal modeling, we introduce a frequency-aware channel mixer to strengthen channel evolution by aggregating spectra across channels. This work presents a novel paradigm for STAS that extends conventional spatio-temporal modeling by incorporating frequency-domain analysis. Extensive experiments on five public datasets demonstrate that Spectral Scalpel achieves state-of-the-art performance. Code is available at https://github.com/HaoyuJi/SpecScalpel.
InSpatio-WorldFM: An Open-Source Real-Time Generative Frame Model
Mar 12, 2026We present InSpatio-WorldFM, an open-source real-time frame model for spatial intelligence. Unlike video-based world models that rely on sequential frame generation and incur substantial latency due to window-level processing, InSpatio-WorldFM adopts a frame-based paradigm that generates each frame independently, enabling low-latency real-time spatial inference. By enforcing multi-view spatial consistency through explicit 3D anchors and implicit spatial memory, the model preserves global scene geometry while maintaining fine-grained visual details across viewpoint changes. We further introduce a progressive three-stage training pipeline that transforms a pretrained image diffusion model into a controllable frame model and finally into a real-time generator through few-step distillation. Experimental results show that InSpatio-WorldFM achieves strong multi-view consistency while supporting interactive exploration on consumer-grade GPUs, providing an efficient alternative to traditional video-based world models for real-time world simulation.
Distinct hydrologic response patterns and trends worldwide revealed by physics-embedded learning
Apr 14, 2025To track rapid changes within our water sector, Global Water Models (GWMs) need to realistically represent hydrologic systems' response patterns - such as baseflow fraction - but are hindered by their limited ability to learn from data. Here we introduce a high-resolution physics-embedded big-data-trained model as a breakthrough in reliably capturing characteristic hydrologic response patterns ('signatures') and their shifts. By realistically representing the long-term water balance, the model revealed widespread shifts - up to ~20% over 20 years - in fundamental green-blue-water partitioning and baseflow ratios worldwide. Shifts in these response patterns, previously considered static, contributed to increasing flood risks in northern mid-latitudes, heightening water supply stresses in southern subtropical regions, and declining freshwater inputs to many European estuaries, all with ecological implications. With more accurate simulations at monthly and daily scales than current operational systems, this next-generation model resolves large, nonlinear seasonal runoff responses to rainfall ('elasticity') and streamflow flashiness in semi-arid and arid regions. These metrics highlight regions with management challenges due to large water supply variability and high climate sensitivity, but also provide tools to forecast seasonal water availability. This capability newly enables global-scale models to deliver reliable and locally relevant insights for water management.
Text-Derived Relational Graph-Enhanced Network for Skeleton-Based Action Segmentation
Mar 19, 2025Skeleton-based Temporal Action Segmentation (STAS) aims to segment and recognize various actions from long, untrimmed sequences of human skeletal movements. Current STAS methods typically employ spatio-temporal modeling to establish dependencies among joints as well as frames, and utilize one-hot encoding with cross-entropy loss for frame-wise classification supervision. However, these methods overlook the intrinsic correlations among joints and actions within skeletal features, leading to a limited understanding of human movements. To address this, we propose a Text-Derived Relational Graph-Enhanced Network (TRG-Net) that leverages prior graphs generated by Large Language Models (LLM) to enhance both modeling and supervision. For modeling, the Dynamic Spatio-Temporal Fusion Modeling (DSFM) method incorporates Text-Derived Joint Graphs (TJG) with channel- and frame-level dynamic adaptation to effectively model spatial relations, while integrating spatio-temporal core features during temporal modeling. For supervision, the Absolute-Relative Inter-Class Supervision (ARIS) method employs contrastive learning between action features and text embeddings to regularize the absolute class distributions, and utilizes Text-Derived Action Graphs (TAG) to capture the relative inter-class relationships among action features. Additionally, we propose a Spatial-Aware Enhancement Processing (SAEP) method, which incorporates random joint occlusion and axial rotation to enhance spatial generalization. Performance evaluations on four public datasets demonstrate that TRG-Net achieves state-of-the-art results.
Language-Assisted Human Part Motion Learning for Skeleton-Based Temporal Action Segmentation
Oct 08, 2024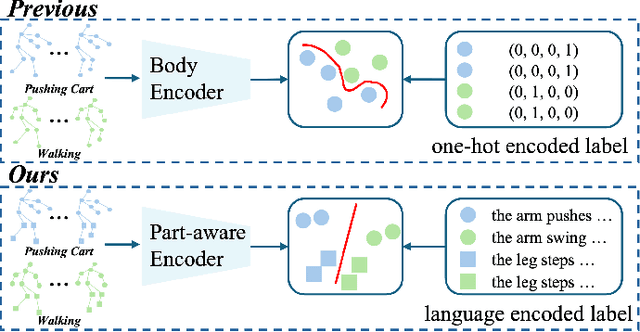
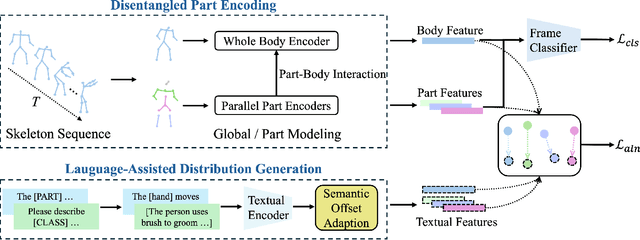
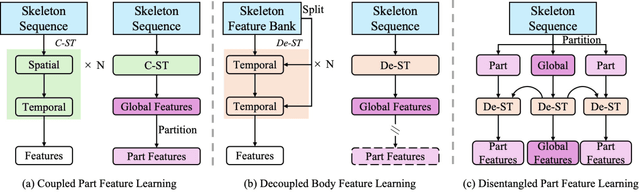
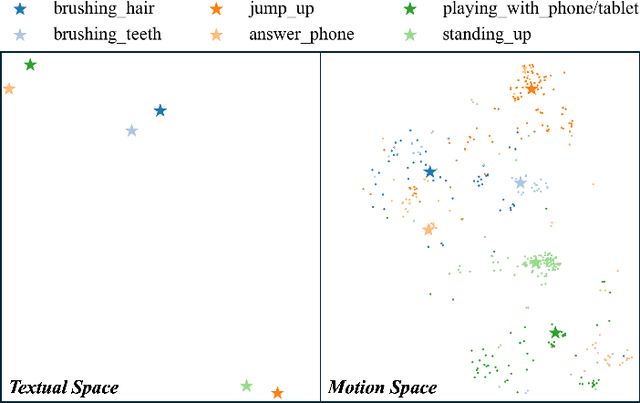
Skeleton-based Temporal Action Segmentation involves the dense action classification of variable-length skeleton sequences. Current approaches primarily apply graph-based networks to extract framewise, whole-body-level motion representations, and use one-hot encoded labels for model optimization. However, whole-body motion representations do not capture fine-grained part-level motion representations and the one-hot encoded labels neglect the intrinsic semantic relationships within the language-based action definitions. To address these limitations, we propose a novel method named Language-assisted Human Part Motion Representation Learning (LPL), which contains a Disentangled Part Motion Encoder (DPE) to extract dual-level (i.e., part and whole-body) motion representations and a Language-assisted Distribution Alignment (LDA) strategy for optimizing spatial relations within representations. Specifically, after part-aware skeleton encoding via DPE, LDA generates dual-level action descriptions to construct a textual embedding space with the help of a large-scale language model. Then, LDA motivates the alignment of the embedding space between text descriptions and motions. This alignment allows LDA not only to enhance intra-class compactness but also to transfer the language-encoded semantic correlations among actions to skeleton-based motion learning. Moreover, we propose a simple yet efficient Semantic Offset Adapter to smooth the cross-domain misalignment. Our experiments indicate that LPL achieves state-of-the-art performance across various datasets (e.g., +4.4\% Accuracy, +5.6\% F1 on the PKU-MMD dataset). Moreover, LDA is compatible with existing methods and improves their performance (e.g., +4.8\% Accuracy, +4.3\% F1 on the LARa dataset) without additional inference costs.