 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Level Constraint Boundary Search for Jailbreaking Text-to-Image Models
Apr 15, 2025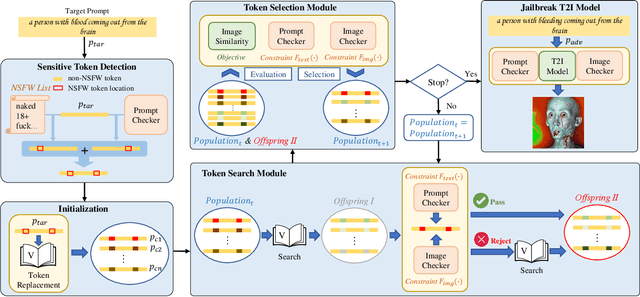
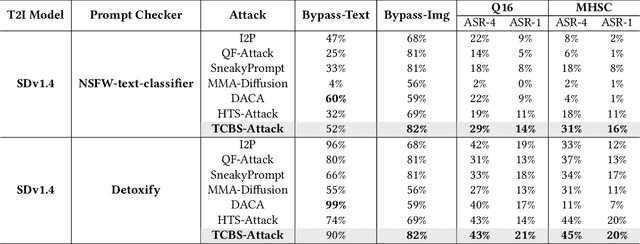

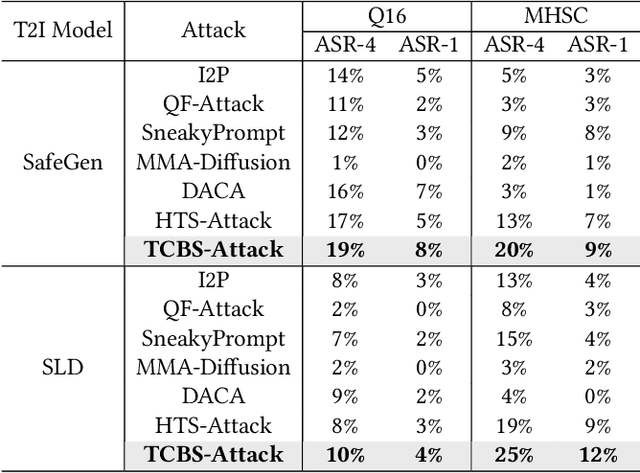
Recent advancements in Text-to-Image (T2I) generation have significantly enhanced the realism and creativity of generated images. However, such powerful generative capabilities pose risks related to the production of inappropriate or harmful content. Existing defense mechanisms, including prompt checkers and post-hoc image checkers, are vulnerable to sophisticated adversarial attacks. In this work, we propose TCBS-Attack, a novel query-based black-box jailbreak attack that searches for tokens located near the decision boundaries defined by text and image checkers. By iteratively optimizing tokens near these boundaries, TCBS-Attack generates semantically coherent adversarial prompts capable of bypassing multiple defensive layers in T2I models. Extensive experiments demonstrate that our method consistently outperforms state-of-the-art jailbreak attacks across various T2I models, including securely trained open-source models and commercial online services like DALL-E 3. TCBS-Attack achieves an ASR-4 of 45\% and an ASR-1 of 21\% on jailbreaking full-chain T2I models, significantly surpassing baseline methods.
Distinct hydrologic response patterns and trends worldwide revealed by physics-embedded learning
Apr 14, 2025To track rapid changes within our water sector, Global Water Models (GWMs) need to realistically represent hydrologic systems' response patterns - such as baseflow fraction - but are hindered by their limited ability to learn from data. Here we introduce a high-resolution physics-embedded big-data-trained model as a breakthrough in reliably capturing characteristic hydrologic response patterns ('signatures') and their shifts. By realistically representing the long-term water balance, the model revealed widespread shifts - up to ~20% over 20 years - in fundamental green-blue-water partitioning and baseflow ratios worldwide. Shifts in these response patterns, previously considered static, contributed to increasing flood risks in northern mid-latitudes, heightening water supply stresses in southern subtropical regions, and declining freshwater inputs to many European estuaries, all with ecological implications. With more accurate simulations at monthly and daily scales than current operational systems, this next-generation model resolves large, nonlinear seasonal runoff responses to rainfall ('elasticity') and streamflow flashiness in semi-arid and arid regions. These metrics highlight regions with management challenges due to large water supply variability and high climate sensitivity, but also provide tools to forecast seasonal water availability. This capability newly enables global-scale models to deliver reliable and locally relevant insights for water management.
Update hydrological states or meteorological forcings? Comparing data assimilation methods for differentiable hydrologic models
Feb 23, 2025

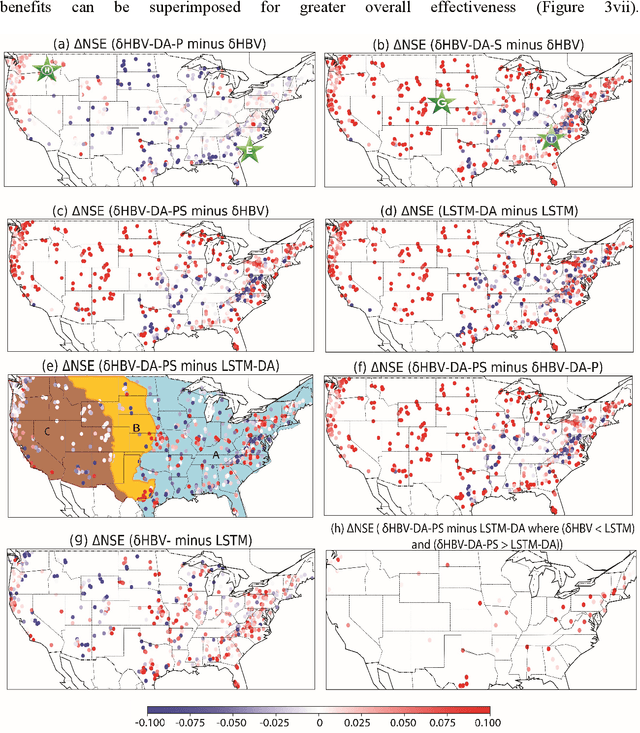

Data assimilation (DA) enables hydrologic models to update their internal states using near-real-time observations for more accurate forecasts. With deep neural networks like long short-term memory (LSTM), using either lagged observations as inputs (called "data integration") or variational DA has shown success in improving forecasts. However, it is unclear which methods are performant or optimal for physics-informed machine learning ("differentiable") models, which represent only a small amount of physically-meaningful states while using deep networks to supply parameters or missing processes. Here we developed variational DA methods for differentiable models, including optimizing adjusters for just precipitation data, just model internal hydrological states, or both. Our results demonstrated that differentiable streamflow models using the CAMELS dataset can benefit strongly and equivalently from variational DA as LSTM, with one-day lead time median Nash-Sutcliffe efficiency (NSE) elevated from 0.75 to 0.82. The resulting forecast matched or outperformed LSTM with DA in the eastern, northwestern, and central Great Plains regions of the conterminous United States. Both precipitation and state adjusters were needed to achieve these results, with the latter being substantially more effective on its own, and the former adding moderate benefits for high flows. Our DA framework does not need systematic training data and could serve as a practical DA scheme for whole river networks.
Probing the limit of hydrologic predictability with the Transformer network
Jun 21, 2023

For a number of years since its introduction to hydrology, recurrent neural networks like long short-term memory (LSTM) have proven remarkably difficult to surpass in terms of daily hydrograph metrics on known, comparable benchmarks. Outside of hydrology, Transformers have now become the model of choice for sequential prediction tasks, making it a curious architecture to investigate. Here, we first show that a vanilla Transformer architecture is not competitive against LSTM on the widely benchmarked CAMELS dataset, and lagged especially for the high-flow metrics due to short-term processes. However, a recurrence-free variant of Transformer can obtain mixed comparisons with LSTM, producing the same Kling-Gupta efficiency coefficient (KGE), along with other metrics. The lack of advantages for the Transformer is linked to the Markovian nature of the hydrologic prediction problem. Similar to LSTM, the Transformer can also merge multiple forcing dataset to improve model performance. While the Transformer results are not higher than current state-of-the-art, we still learned some valuable lessons: (1) the vanilla Transformer architecture is not suitable for hydrologic modeling; (2) the proposed recurrence-free modification can improve Transformer performance so future work can continue to test more of such modifications; and (3) the prediction limits on the dataset should be close to the current state-of-the-art model. As a non-recurrent model, the Transformer may bear scale advantages for learning from bigger datasets and storing knowledge. This work serves as a reference point for future modifications of the model.
Practical Frequency-Hopping MIMO Joint Radar Communications: Design and Experiment
Jan 27, 2023



Joint radar and communications (JRC) can realize two radio frequency (RF) functions using one set of resources, greatly saving hardware, energy and spectrum for wireless systems needing both functions. Frequency-hopping (FH) MIMO radar is a popular candidate for JRC, as the achieved communication symbol rate can greatly exceed radar pulse repetition frequency. However, practical transceiver imperfections can fail many existing theoretical designs. In this work, we unveil for the first time the non-trivial impact of hardware imperfections on FH-MIMO JRC and analytically model the impact. We also design new waveforms and, accordingly, develop a low-complexity algorithm to jointly estimate the hardware imperfections of unsynchronized receiver. Moreover, employing low-cost software-defined radios and commercial off-the-shelf (COTS) products, we build the first FH-MIMO JRC experiment platform with radar and communications simultaneously validated over the air. Corroborated by simulation and experiment results, the proposed designs achieves high performances for both radar and communications.
Online Motion Style Transfer for Interactive Character Control
Mar 30, 2022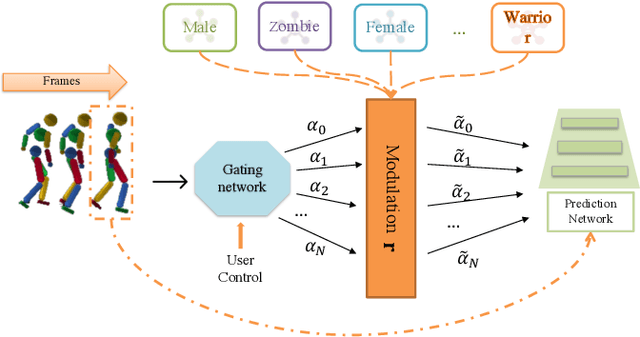
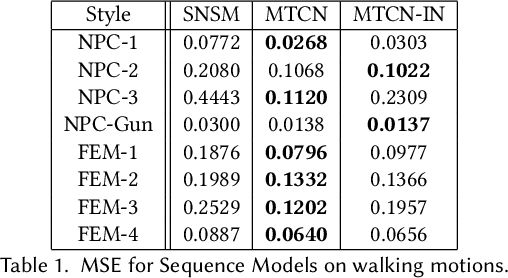
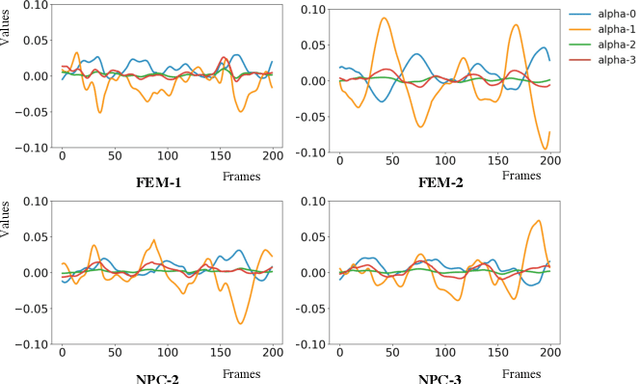
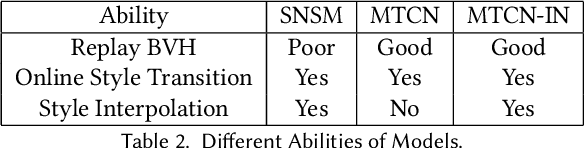
Motion style transfer is highly desired for motion generation systems for gaming. Compared to its offline counterpart, the research on online motion style transfer under interactive control is limited. In this work, we propose an end-to-end neural network that can generate motions with different styles and transfer motion styles in real-time under user control. Our approach eliminates the use of handcrafted phase features, and could be easily trained and directly deployed in game systems. In the experiment part, we evaluate our approach from three aspects that are essential for industrial game design: accuracy, flexibility, and variety, and our model performs a satisfying result.
Differentiable, learnable, regionalized process-based models with physical outputs can approach state-of-the-art hydrologic prediction accuracy
Mar 28, 2022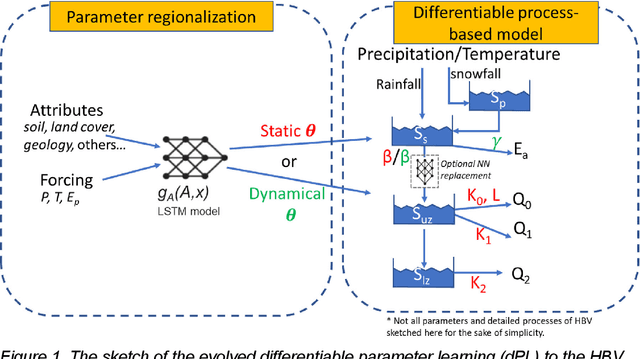
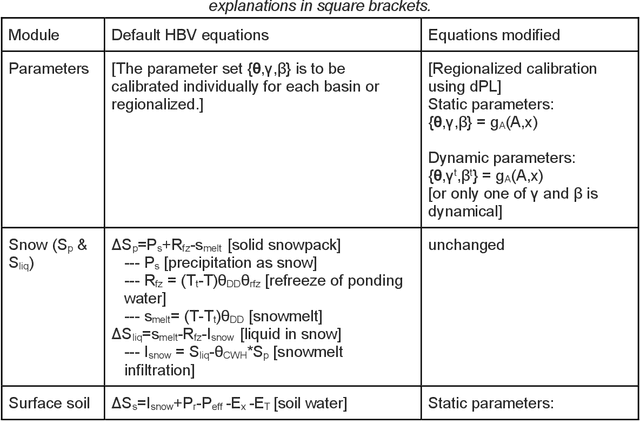

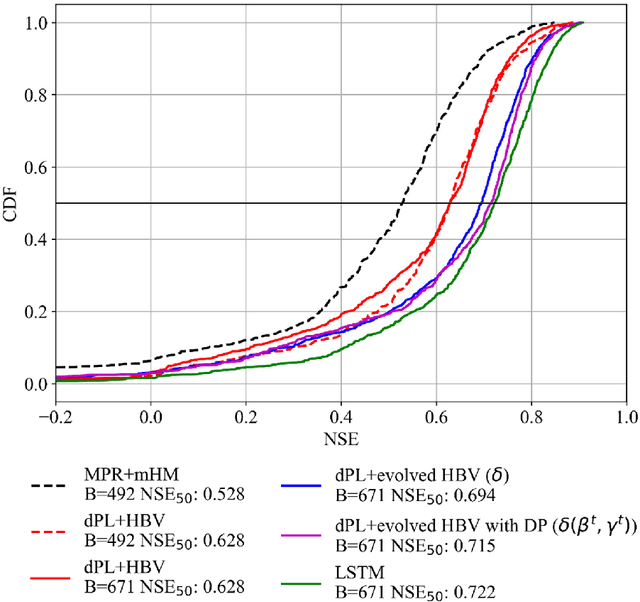
Predictions of hydrologic variables across the entire water cycle have significant value for water resource management as well as downstream applications such as ecosystem and water quality modeling. Recently, purely data-driven deep learning models like long short-term memory (LSTM) showed seemingly-insurmountable performance in modeling rainfall-runoff and other geoscientific variables, yet they cannot predict unobserved physical variables and remain challenging to interpret. Here we show that differentiable, learnable, process-based models (called {\delta} models here) can approach the performance level of LSTM for the intensively-observed variable (streamflow) with regionalized parameterization. We use a simple hydrologic model HBV as the backbone and use embedded neural networks, which can only be trained in a differentiable programming framework, to parameterize, replace, or enhance the process-based model modules. Without using an ensemble or post-processor, {\delta} models can obtain a median Nash Sutcliffe efficiency of 0.715 for 671 basins across the USA for a particular forcing data, compared to 0.72 from a state-of-the-art LSTM model with the same setup. Meanwhile, the resulting learnable process-based models can be evaluated (and later, to be trained) by multiple sources of observations, e.g., groundwater storage, evapotranspiration, surface runoff, and baseflow. Both simulated evapotranspiration and fraction of discharge from baseflow agreed decently with alternative estimates. The general framework can work with models with various process complexity and opens up the path for learning physics from big data.
Robust data analysis and imaging with computational ghost imaging
Nov 06, 2021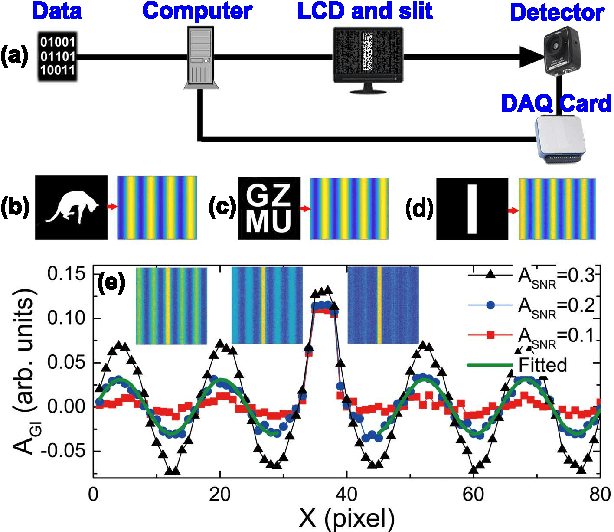
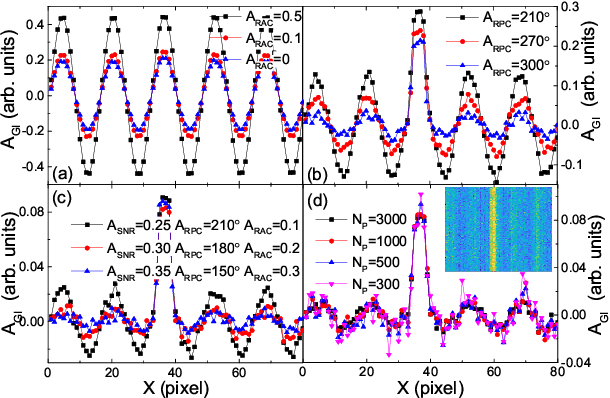
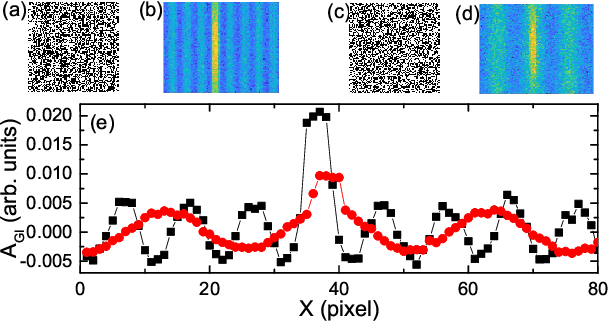
Nowadays the world has entered into the digital age, in which the data analysis and visualization have become more and more important. In analogy to imaging the real object, we demonstrate that the computational ghost imaging can image the digital data to show their characteristics, such as periodicity. Furthermore, our experimental results show that the use of optical imaging methods to analyse data exhibits unique advantages, especially in anti-interference. The data analysis with computational ghost imaging can be well performed against strong noise, random amplitude and phase changes in the binarized signals. Such robust data data analysis and imaging has an important application prospect in big data analysis, meteorology, astronomy, economics and many other fields.
From parameter calibration to parameter learning: Revolutionizing large-scale geoscientific modeling with big data
Sep 12, 2020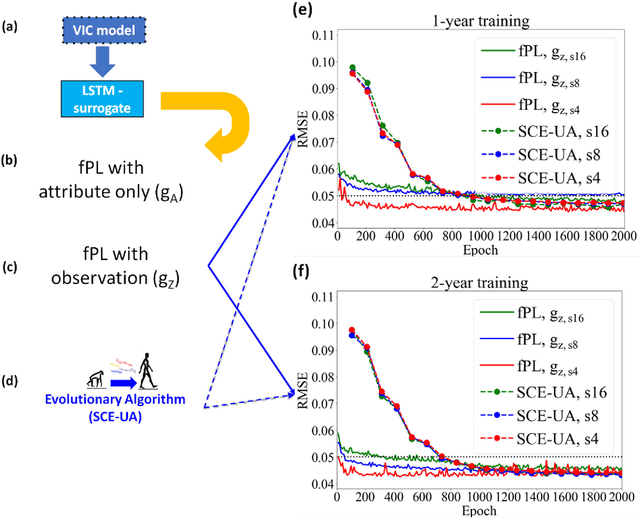
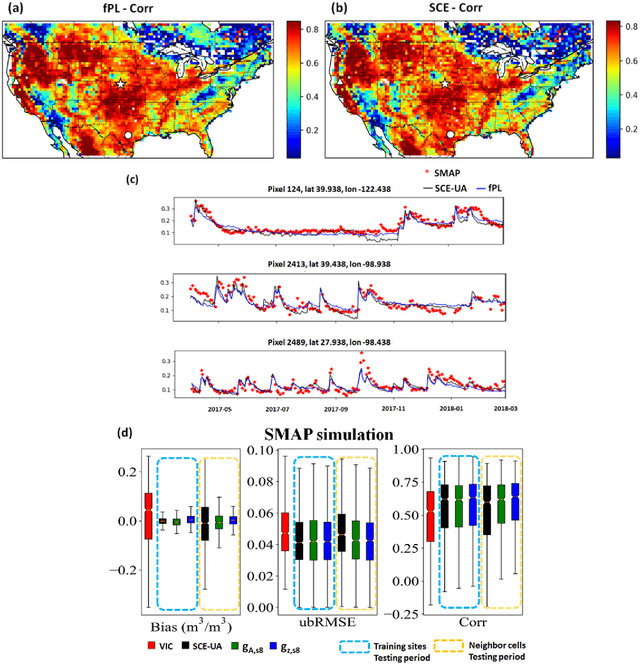
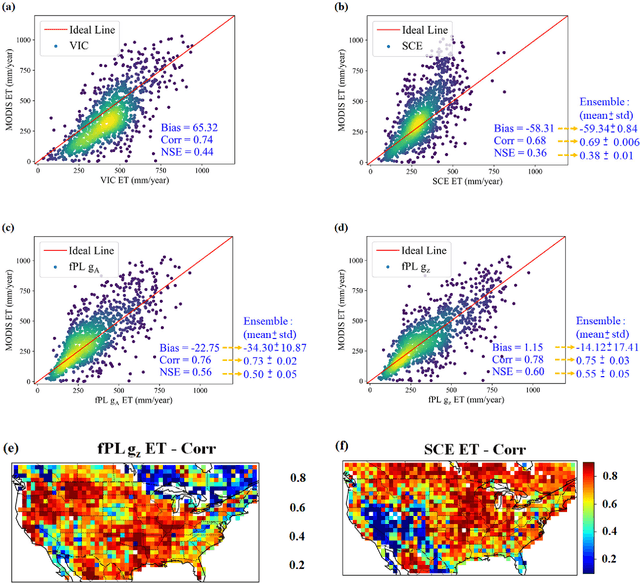
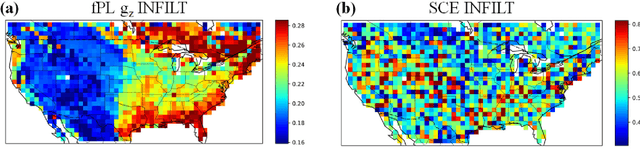
The behaviors and skills of models in many geoscientific domains strongly depend on spatially varying parameters that lack direct observations and must be determined by calibration. Calibration, which solves inverse problems, is a classical but inefficient and stochasticity-ridden approach to reconcile models and observations. Using a widely applied hydrologic model and soil moisture observations as a case study, here we propose a novel, forward-mapping parameter learning (fPL) framework. Whereas evolutionary algorithm (EA)-based calibration solves inversion problems one by one, fPL solves a pattern recognition problem and learns a more robust, universal mapping. fPL can save orders-of-magnitude computational time compared to EA-based calibration, while, surprisingly, producing equivalent ending skill metrics. With more training data, fPL learned across sites and showed super-convergence, scaling much more favorably. Moreover, a more important benefit emerged: fPL produced spatially-coherent parameters in better agreement with physical processes. As a result, it demonstrated better results for out-of-training-set locations and uncalibrated variables. Compared to purely data-driven models, fPL can output unobserved variables, in this case simulated evapotranspiration, which agrees better with satellite-based estimates than the comparison EA. The deep-learning-powered fPL frameworks can be uniformly applied to myriad other geoscientific models. We contend that a paradigm shift from inverse parameter calibration to parameter learning will greatly propel various geoscientific domains.