 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Language to Cognition: How LLMs Outgrow the Human Language Network
Mar 03, 2025Large language models (LLMs) exhibit remarkable similarity to neural activity in the human language network. However, the key properties of language shaping brain-like representations, and their evolution during training as a function of different tasks remain unclear. We here benchmark 34 training checkpoints spanning 300B tokens across 8 different model sizes to analyze how brain alignment relates to linguistic competence. Specifically, we find that brain alignment tracks the development of formal linguistic competence -- i.e., knowledge of linguistic rules -- more closely than functional linguistic competence. While functional competence, which involves world knowledge and reasoning, continues to develop throughout training, its relationship with brain alignment is weaker, suggesting that the human language network primarily encodes formal linguistic structure rather than broader cognitive functions. We further show that model size is not a reliable predictor of brain alignment when controlling for feature size and find that the correlation between next-word prediction, behavioral alignment and brain alignment fades once models surpass human language proficiency. Finally, using the largest set of rigorous neural language benchmarks to date, we show that language brain alignment benchmarks remain unsaturated, highlighting opportunities for improving future models. Taken together, our findings suggest that the human language network is best modeled by formal, rather than functional, aspects of language.
Dreaming Out Loud: A Self-Synthesis Approach For Training Vision-Language Models With Developmentally Plausible Data
Oct 29, 2024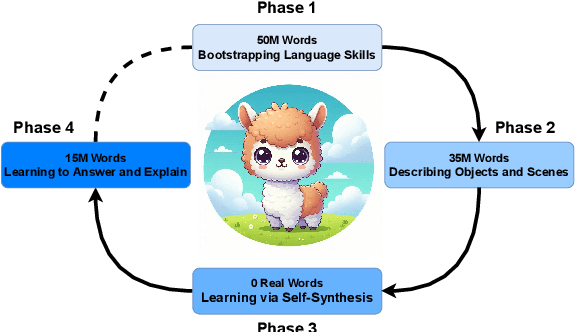

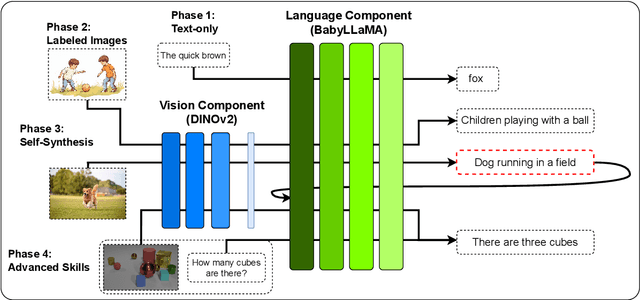
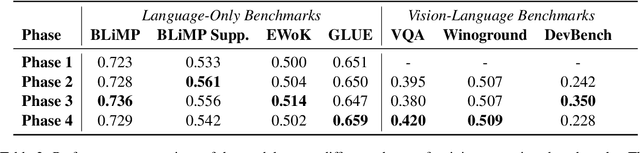
While today's large language models exhibit impressive abilities in generating human-like text, they require massive amounts of data during training. We here take inspiration from human cognitive development to train models in limited data conditions. Specifically we present a self-synthesis approach that iterates through four phases: Phase 1 sets up fundamental language abilities, training the model from scratch on a small corpus. Language is then associated with the visual environment in phase 2, integrating the model with a vision encoder to generate descriptive captions from labeled images. In the "self-synthesis" phase 3, the model generates captions for unlabeled images, that it then uses to further train its language component with a mix of synthetic, and previous real-world text. This phase is meant to expand the model's linguistic repertoire, similar to humans self-annotating new experiences. Finally, phase 4 develops advanced cognitive skills, by training the model on specific tasks such as visual question answering and reasoning. Our approach offers a proof of concept for training a multimodal model using a developmentally plausible amount of data.
When are Lemons Purple? The Concept Association Bias of CLIP
Dec 22, 2022Large-scale vision-language models such as CLIP have shown impressive performance on zero-shot image classification and image-to-text retrieval. However, such zero-shot performance of CLIP-based models does not realize in tasks that require a finer-grained correspondence between vision and language, such as Visual Question Answering (VQA). We investigate why this is the case, and report an interesting phenomenon of CLIP, which we call the Concept Association Bias (CAB), as a potential cause of the difficulty of applying CLIP to VQA and similar tasks. CAB is especially apparent when two concepts are present in the given image while a text prompt only contains a single concept. In such a case, we find that CLIP tends to treat input as a bag of concepts and attempts to fill in the other missing concept crossmodally, leading to an unexpected zero-shot prediction. For example, when asked for the color of a lemon in an image, CLIP predicts ``purple'' if the image contains a lemon and an eggplant. We demonstrate the Concept Association Bias of CLIP by showing that CLIP's zero-shot classification performance greatly suffers when there is a strong concept association between an object (e.g. lemon) and an attribute (e.g. its color). On the other hand, when the association between object and attribute is weak, we do not see this phenomenon. Furthermore, we show that CAB is significantly mitigated when we enable CLIP to learn deeper structure across image and text embeddings by adding an additional Transformer on top of CLIP and fine-tuning it on VQA. We find that across such fine-tuned variants of CLIP, the strength of CAB in a model predicts how well it performs on VQA.
Online Motion Style Transfer for Interactive Character Control
Mar 30, 2022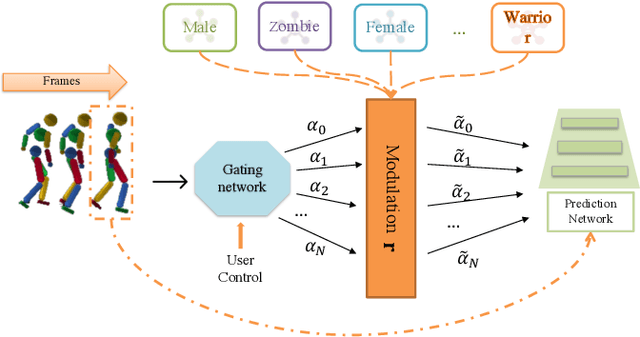
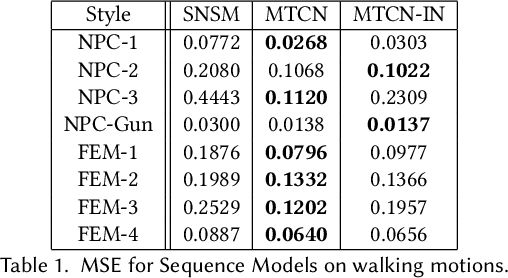
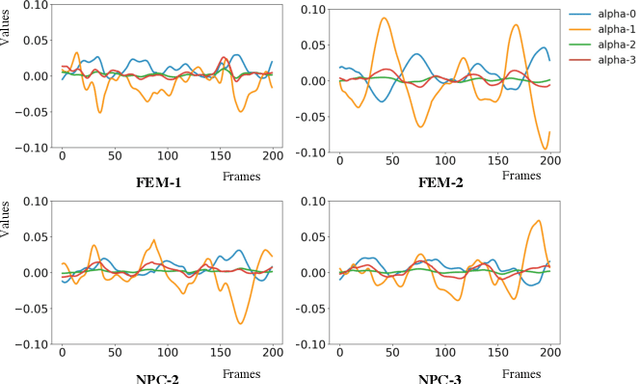
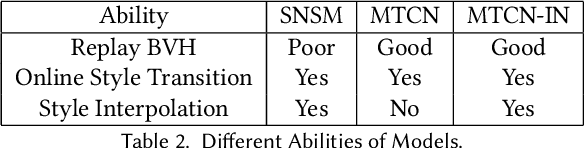
Motion style transfer is highly desired for motion generation systems for gaming. Compared to its offline counterpart, the research on online motion style transfer under interactive control is limited. In this work, we propose an end-to-end neural network that can generate motions with different styles and transfer motion styles in real-time under user control. Our approach eliminates the use of handcrafted phase features, and could be easily trained and directly deployed in game systems. In the experiment part, we evaluate our approach from three aspects that are essential for industrial game design: accuracy, flexibility, and variety, and our model performs a satisfying result.
Learning-Aided Heuristics Design for Storage System
Jun 14, 2021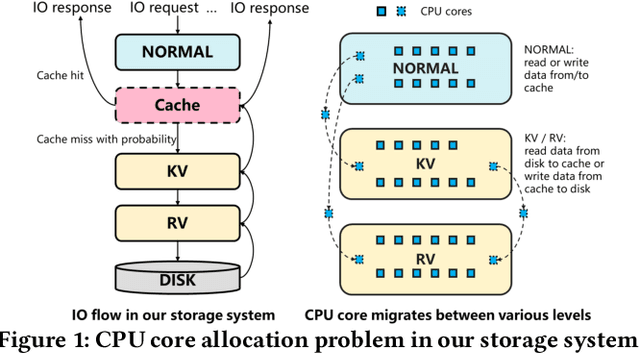
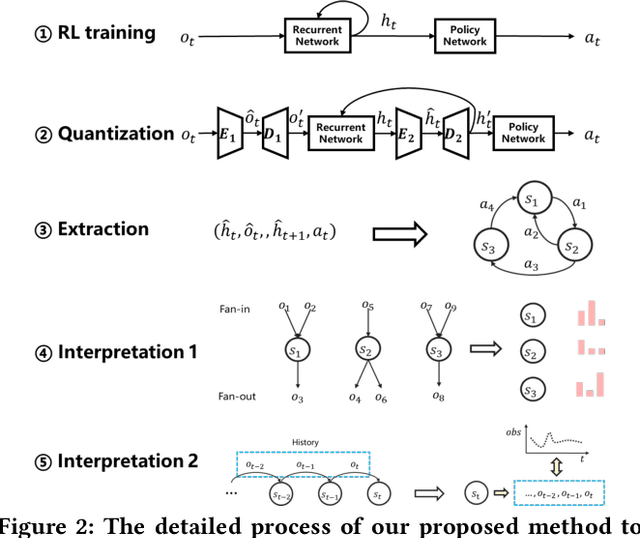
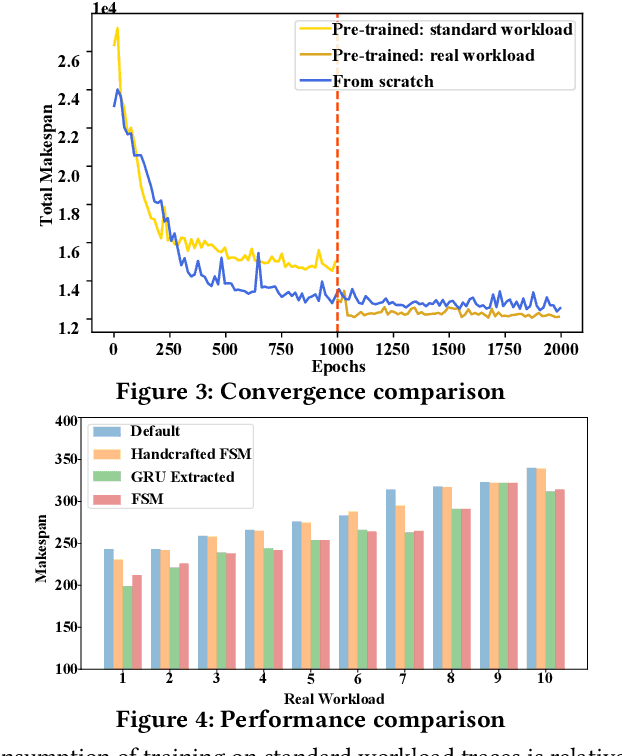
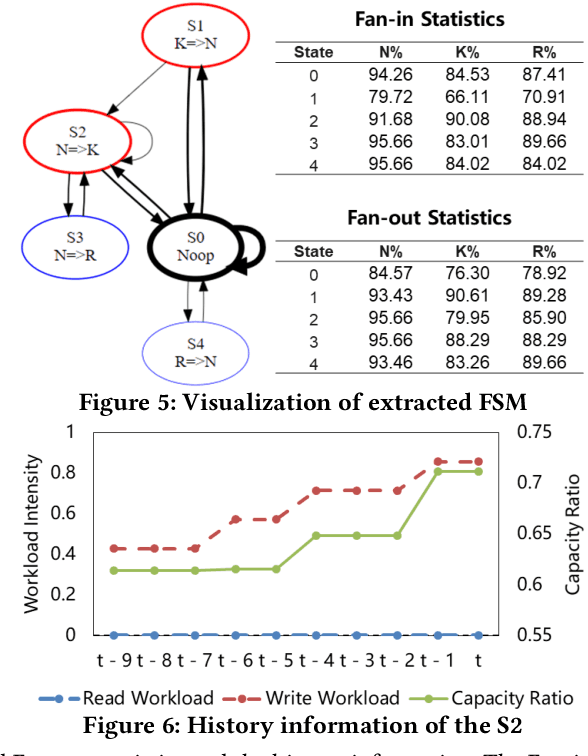
Computer systems such as storage systems normally require transparent white-box algorithms that are interpretable for human experts. In this work, we propose a learning-aided heuristic design method, which automatically generates human-readable strategies from Deep Reinforcement Learning (DRL) agents. This method benefits from the power of deep learning but avoids the shortcoming of its black-box property. Besides the white-box advantage, experiments in our storage productions resource allocation scenario also show that this solution outperforms the systems default settings and the elaborately handcrafted strategy by human experts.