 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreaming Out Loud: A Self-Synthesis Approach For Training Vision-Language Models With Developmentally Plausible Data
Paper and Code
Oct 29, 2024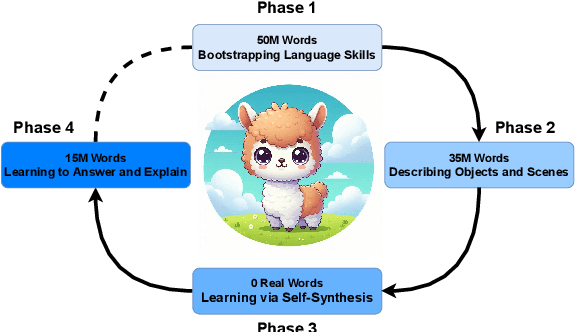

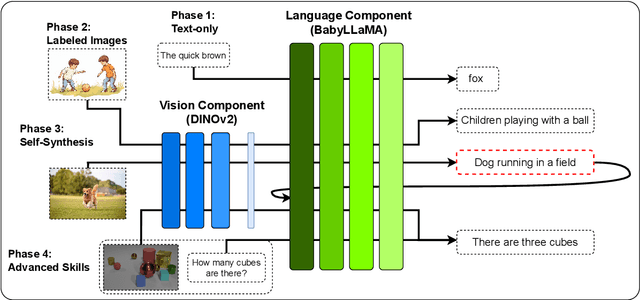
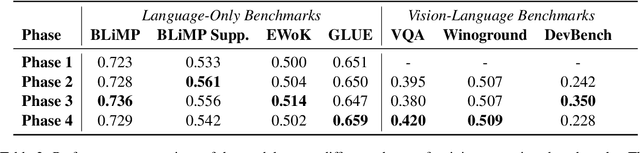
While today's large language models exhibit impressive abilities in generating human-like text, they require massive amounts of data during training. We here take inspiration from human cognitive development to train models in limited data conditions. Specifically we present a self-synthesis approach that iterates through four phases: Phase 1 sets up fundamental language abilities, training the model from scratch on a small corpus. Language is then associated with the visual environment in phase 2, integrating the model with a vision encoder to generate descriptive captions from labeled images. In the "self-synthesis" phase 3, the model generates captions for unlabeled images, that it then uses to further train its language component with a mix of synthetic, and previous real-world text. This phase is meant to expand the model's linguistic repertoire, similar to humans self-annotating new experiences. Finally, phase 4 develops advanced cognitive skills, by training the model on specific tasks such as visual question answering and reasoning. Our approach offers a proof of concept for training a multimodal model using a developmentally plausible amount of data.