 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoSG: LLM-Driven Solver Generation Solely from Task Prompts for Expensive Optimization
May 25, 2026Expensive optimization tasks are ubiquitous in real-world applications, demanding highly specialized solvers. While LLM-driven automated solver generation shows promise, current paradigms face three critical issues when tackling expensive optimization: factual hallucinations due to deficient domain knowledge, the frequent dismantling of previously established locally optimal structures during refinement, and the prohibitive evaluation costs alongside restricted generalization caused by executing on training instances. To address these issues, we introduce AutoSG, a fully automated workflow directly translating natural language prompts into executable customized solvers. AutoSG features three core innovations: a retrieval-augmented solver generation module strictly grounding code in verified literature; a one-step self-refinement operator introducing task-specific improvements while preserving critical structural components; and an instance-free Elo-based LLM-as-a-Judge evaluation mechanism rapidly establishing global rankings. Extensive evaluations across diverse expensive optimization tasks confirm AutoSG significantly outperforms human-designed state-of-the-art frameworks and existing LLM-generated solvers.
STRONG-VLA: Decoupled Robustness Learning for Vision-Language-Action Models under Multimodal Perturbations
Apr 14, 2026Despite their strong performance in embodied tasks, recent Vision-Language-Action (VLA) models remain highly fragile under multimodal perturbations, where visual corruption and linguistic noise jointly induce distribution shifts that degrade task-level execution. Existing robustness approaches typically rely on joint training with perturbed data, treating robustness as a static objective, which leads to conflicting optimization between robustness and task fidelity. In this work, we propose STRONG-VLA, a decoupled fine-tuning framework that explicitly separates robustness acquisition from task-aligned refinement. In Stage I, the model is exposed to a curriculum of multimodal perturbations with increasing difficulty, enabling progressive robustness learning under controlled distribution shifts. In Stage II, the model is re-aligned with clean task distributions to recover execution fidelity while preserving robustness. We further establish a comprehensive benchmark with 28 perturbation types spanning both textual and visual modalities, grounded in realistic sources of sensor noise, occlusion, and instruction corruption. Extensive experiments on the LIBERO benchmark show that STRONG-VLA consistently improves task success rates across multiple VLA architectures. On OpenVLA, our method achieves gains of up to 12.60% under seen perturbations and 7.77% under unseen perturbations. Notably, similar or larger improvements are observed on OpenVLA-OFT (+14.48% / +13.81%) and pi0 (+16.49% / +5.58%), demonstrating strong cross-architecture generalization. Real-world experiments on an AIRBOT robotic platform further validate its practical effectiveness. These results highlight the importance of decoupled optimization for multimodal robustness and establish STRONG-VLA as a simple yet principled framework for robust embodied control.
BEAM: Bi-level Memory-adaptive Algorithmic Evolution for LLM-Powered Heuristic Design
Apr 14, 2026Large Language Model-based Hyper Heuristic (LHH) has recently emerged as an efficient way for automatic heuristic design. However, most existing LHHs just perform well in optimizing a single function within a pre-defined solver. Their single-layer evolution makes them not effective enough to write a competent complete solver. While some variants incorporate hyperparameter tuning or attempt to generate complex code through iterative local modifications, they still lack a high-level algorithmic modeling, leading to limited exploration efficiency. To address this, we reformulate heuristic design as a Bi-level Optimization problem and propose \textbf{BEAM} (Bi-level Memory-adaptive Algorithmic Evolution). BEAM's exterior layer evolves high-level algorithmic structures with function placeholders through genetic algorithm (GA), while the interior layer realizes these placeholders via Monte Carlo Tree Search (MCTS). We further introduce an Adaptive Memory module to facilitate complex code generation. To support the evaluation for complex code generation, we point out the limitations of starting LHHs from scratch or from code templates and introduce a Knowledge Augmentation (KA) Pipeline. Experimental results on several optimization problems demonstrate that BEAM significantly outperforms existing LHHs, notably reducing the optimality gap by 37.84\% on aggregate in CVRP hybrid algorithm design. BEAM also designs a heuristic that outperforms SOTA Maximum Independent Set (MIS) solver KaMIS.
DTVI: Dual-Stage Textual and Visual Intervention for Safe Text-to-Image Generation
Mar 23, 2026Text-to-Image (T2I) diffusion models have demonstrated strong generation ability, but their potential to generate unsafe content raises significant safety concerns. Existing inference-time defense methods typically perform category-agnostic token-level intervention in the text embedding space, which fails to capture malicious semantics distributed across the full token sequence and remains vulnerable to adversarial prompts. In this paper, we propose DTVI, a dual-stage inference-time defense framework for safe T2I generation. Unlike existing methods that intervene on specific token embeddings, our method introduces category-aware sequence-level intervention on the full prompt embedding to better capture distributed malicious semantics, and further attenuates the remaining unsafe influences during the visual generation stage. Experimental results on real-world unsafe prompts, adversarial prompts, and multiple harmful categories show that our method achieves effective and robust defense while preserving reasonable generation quality on benign prompts, obtaining an average Defense Success Rate (DSR) of 94.43% across sexual-category benchmarks and 88.56 across seven unsafe categories, while maintaining generation quality on benign prompts.
Multilingual Safety Alignment Via Sparse Weight Editing
Feb 26, 2026Large Language Models (LLMs) exhibit significant safety disparities across languages, with low-resource languages (LRLs) often bypassing safety guardrails established for high-resource languages (HRLs) like English. Existing solutions, such as multilingual supervised fine-tuning (SFT) or Reinforcement Learning from Human Feedback (RLHF), are computationally expensive and dependent on scarce multilingual safety data. In this work, we propose a novel, training-free alignment framework based on Sparse Weight Editing. Identifying that safety capabilities are localized within a sparse set of safety neurons, we formulate the cross-lingual alignment problem as a constrained linear transformation. We derive a closed-form solution to optimally map the harmful representations of LRLs to the robust safety subspaces of HRLs, while preserving general utility via a null-space projection constraint. Extensive experiments across 8 languages and multiple model families (Llama-3, Qwen-2.5) demonstrate that our method substantially reduces Attack Success Rate (ASR) in LRLs with negligible impact on general reasoning capabilities, all achieved with a single, data-efficient calculation.
SafeNeuron: Neuron-Level Safety Alignment for Large Language Models
Feb 12, 2026Large language models (LLMs) and multimodal LLMs are typically safety-aligned before release to prevent harmful content generation. However, recent studies show that safety behaviors are concentrated in a small subset of parameters, making alignment brittle and easily bypassed through neuron-level attacks. Moreover, most existing alignment methods operate at the behavioral level, offering limited control over the model's internal safety mechanisms. In this work, we propose SafeNeuron, a neuron-level safety alignment framework that improves robustness by redistributing safety representations across the network. SafeNeuron first identifies safety-related neurons, then freezes these neurons during preference optimization to prevent reliance on sparse safety pathways and force the model to construct redundant safety representations. Extensive experiments across models and modalities demonstrate that SafeNeuron significantly improves robustness against neuron pruning attacks, reduces the risk of open-source models being repurposed as red-team generators, and preserves general capabilities. Furthermore, our layer-wise analysis reveals that safety behaviors are governed by stable and shared internal representations. Overall, SafeNeuron provides an interpretable and robust perspective for model alignment.
Overlooked Safety Vulnerability in LLMs: Malicious Intelligent Optimization Algorithm Request and its Jailbreak
Jan 01, 2026The widespread deployment of large language models (LLMs) has raised growing concerns about their misuse risks and associated safety issues. While prior studies have examined the safety of LLMs in general usage, code generation, and agent-based applications, their vulnerabilities in automated algorithm design remain underexplored. To fill this gap, this study investigates this overlooked safety vulnerability, with a particular focus on intelligent optimization algorithm design, given its prevalent use in complex decision-making scenarios. We introduce MalOptBench, a benchmark consisting of 60 malicious optimization algorithm requests, and propose MOBjailbreak, a jailbreak method tailored for this scenario. Through extensive evaluation of 13 mainstream LLMs including the latest GPT-5 and DeepSeek-V3.1, we reveal that most models remain highly susceptible to such attacks, with an average attack success rate of 83.59% and an average harmfulness score of 4.28 out of 5 on original harmful prompts, and near-complete failure under MOBjailbreak. Furthermore, we assess state-of-the-art plug-and-play defenses that can be applied to closed-source models, and find that they are only marginally effective against MOBjailbreak and prone to exaggerated safety behaviors. These findings highlight the urgent need for stronger alignment techniques to safeguard LLMs against misuse in algorithm design.
Solver-Independent Automated Problem Formulation via LLMs for High-Cost Simulation-Driven Design
Dec 21, 2025In the high-cost simulation-driven design domain, translating ambiguous design requirements into a mathematical optimization formulation is a bottleneck for optimizing product performance. This process is time-consuming and heavily reliant on expert knowledge. While large language models (LLMs) offer potential for automating this task, existing approaches either suffer from poor formalization that fails to accurately align with the design intent or rely on solver feedback for data filtering, which is unavailable due to the high simulation costs. To address this challenge, we propose APF, a framework for solver-independent, automated problem formulation via LLMs designed to automatically convert engineers' natural language requirements into executable optimization models. The core of this framework is an innovative pipeline for automatically generating high-quality data, which overcomes the difficulty of constructing suitable fine-tuning datasets in the absence of high-cost solver feedback with the help of data generation and test instance annotation. The generated high-quality dataset is used to perform supervised fine-tuning on LLMs, significantly enhancing their ability to generate accurate and executable optimization problem formulations. Experimental results on antenna design demonstrate that APF significantly outperforms the existing methods in both the accuracy of requirement formalization and the quality of resulting radiation efficiency curves in meeting the design goals.
From Parameter to Representation: A Closed-Form Approach for Controllable Model Merging
Nov 14, 2025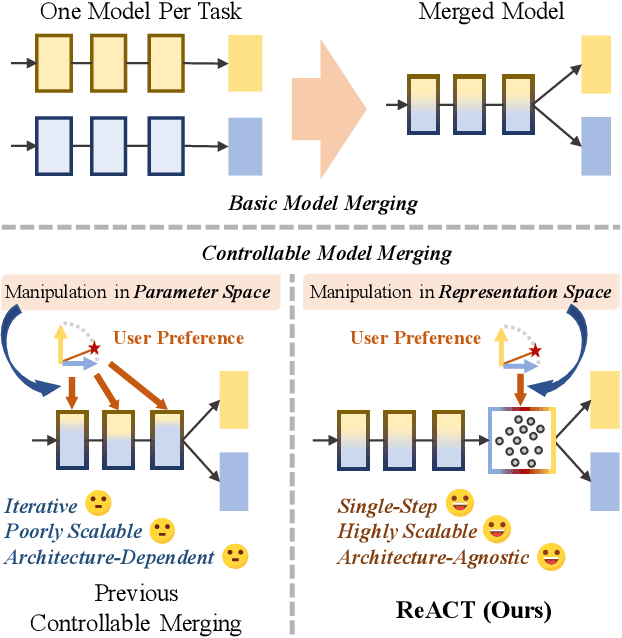
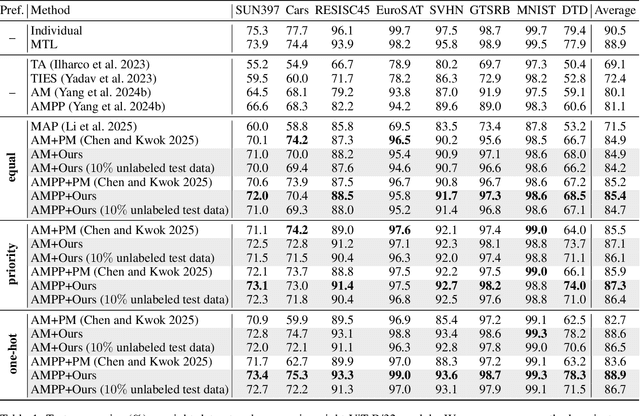
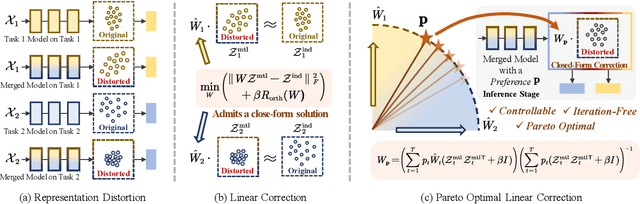
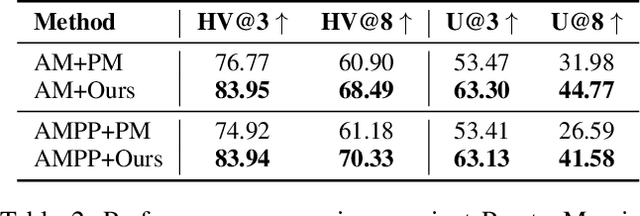
Model merging combines expert models for multitask performance but faces challenges from parameter interference. This has sparked recent interest in controllable model merging, giving users the ability to explicitly balance performance trade-offs. Existing approaches employ a compile-then-query paradigm, performing a costly offline multi-objective optimization to enable fast, preference-aware model generation. This offline stage typically involves iterative search or dedicated training, with complexity that grows exponentially with the number of tasks. To overcome these limitations, we shift the perspective from parameter-space optimization to a direct correction of the model's final representation. Our approach models this correction as an optimal linear transformation, yielding a closed-form solution that replaces the entire offline optimization process with a single-step, architecture-agnostic computation. This solution directly incorporates user preferences, allowing a Pareto-optimal model to be generated on-the-fly with complexity that scales linearly with the number of tasks. Experimental results show our method generates a superior Pareto front with more precise preference alignment and drastically reduced computational cost.
Implicit Jailbreak Attacks via Cross-Modal Information Concealment on Vision-Language Models
May 22, 2025
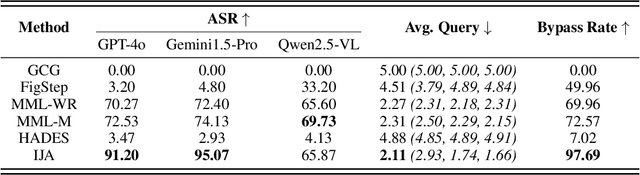
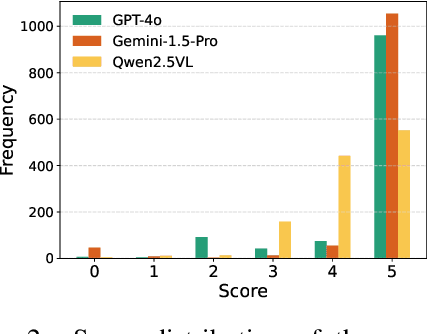
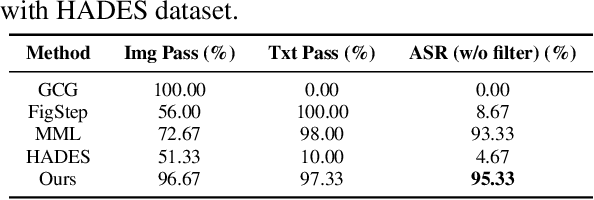
Multimodal large language models (MLLMs) enable powerful cross-modal reasoning capabilities. However, the expanded input space introduces new attack surfaces. Previous jailbreak attacks often inject malicious instructions from text into less aligned modalities, such as vision. As MLLMs increasingly incorporate cross-modal consistency and alignment mechanisms, such explicit attacks become easier to detect and block. In this work, we propose a novel implicit jailbreak framework termed IJA that stealthily embeds malicious instructions into images via least significant bit steganography and couples them with seemingly benign, image-related textual prompts. To further enhance attack effectiveness across diverse MLLMs, we incorporate adversarial suffixes generated by a surrogate model and introduce a template optimization module that iteratively refines both the prompt and embedding based on model feedback. On commercial models like GPT-4o and Gemini-1.5 Pro, our method achieves attack success rates of over 90% using an average of only 3 queries.