 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Data Scarcity in Time Series Analysis: A Foundation Model with Series-Symbol Data Generation
Feb 21, 2025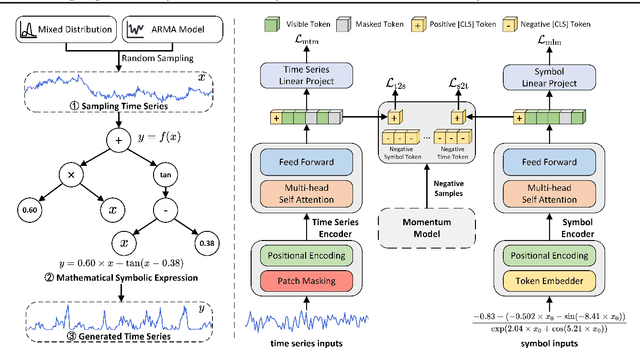



Foundation models for time series analysis (TSA) have attracted significant attention. However, challenges such as data scarcity and data imbalance continue to hinder their development. To address this, we consider modeling complex systems through symbolic expressions that serve as semantic descriptors of time series. Building on this concept, we introduce a series-symbol (S2) dual-modulity data generation mechanism, enabling the unrestricted creation of high-quality time series data paired with corresponding symbolic representations. Leveraging the S2 dataset, we develop SymTime, a pre-trained foundation model for TSA. SymTime demonstrates competitive performance across five major TSA tasks when fine-tuned with downstream task, rivaling foundation models pre-trained on real-world datasets. This approach underscores the potential of dual-modality data generation and pretraining mechanisms in overcoming data scarcity and enhancing task performance.
GLHF: General Learned Evolutionary Algorithm Via Hyper Functions
May 06, 2024Pretrained Optimization Models (POMs) leverage knowledge gained from optimizing various tasks, providing efficient solutions for new optimization challenges through direct usage or fine-tuning. Despite the inefficiencies and limited generalization abilities observed in current POMs, our proposed model, the general pre-trained optimization model (GPOM), addresses these shortcomings. GPOM constructs a population-based pretrained Black-Box Optimization (BBO) model tailored for continuous optimization. Evaluation on the BBOB benchmark and two robot control tasks demonstrates that GPOM outperforms other pretrained BBO models significantly, especially for high-dimensional tasks. Its direct optimization performance exceeds that of state-of-the-art evolutionary algorithms and POMs. Furthermore, GPOM exhibits robust generalization capabilities across diverse task distributions, dimensions, population sizes, and optimization horizons.
EMOFM: Ensemble MLP mOdel with Feature-based Mixers for Click-Through Rate Prediction
Oct 15, 2023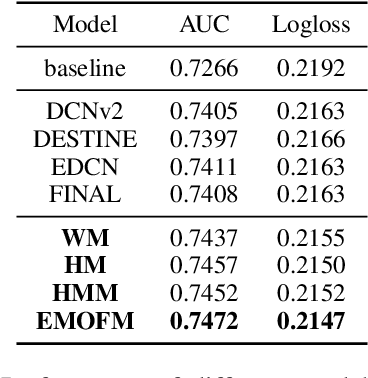
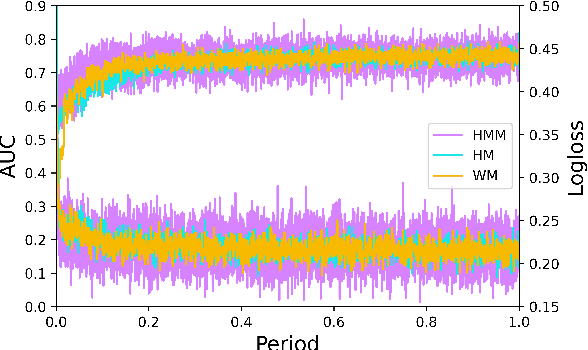
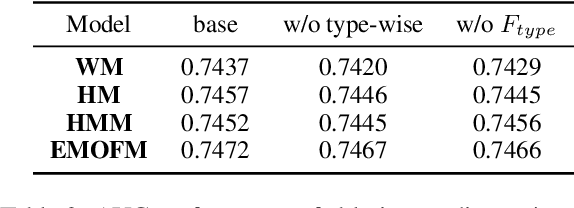
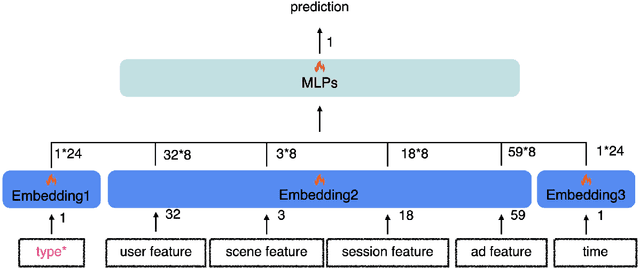
Track one of CTI competition is on click-through rate (CTR) prediction. The dataset contains millions of records and each field-wise feature in a record consists of hashed integers for privacy. For this task, the keys of network-based methods might be type-wise feature extraction and information fusion across different fields. Multi-layer perceptrons (MLPs) are able to extract field feature, but could not efficiently fuse features. Motivated by the natural fusion characteristic of cross attention and the efficiency of transformer-based structures, we propose simple plug-in mixers for field/type-wise feature fusion, and thus construct an field&type-wise ensemble model, namely EMOFM (Ensemble MLP mOdel with Feature-based Mixers). In the experiments, the proposed model is evaluated on the dataset, the optimization process is visualized and ablation studies are explored. It is shown that EMOFM outperforms compared baselines. In the end, we discuss on future work. WARNING: The comparison might not be fair enough since the proposed method is designed for this data in particular while compared methods are not. For example, EMOFM especially takes different types of interactions into consideration while others do not. Anyway, we do hope that the ideas inside our method could help other developers/learners/researchers/thinkers and so on.
SPELL: Semantic Prompt Evolution based on a LLM
Oct 02, 2023Prompt engineering is a new paradigm for enhancing the performance of trained neural network models. For optimizing text-style prompts, existing methods usually individually operate small portions of a text step by step, which either breaks the fluency or could not globally adjust a prompt. Since large language models (LLMs) have powerful ability of generating coherent texts token by token, can we utilize LLMs for improving prompts? Based on this motivation, in this paper, considering a trained LLM as a text generator, we attempt to design a black-box evolution algorithm for automatically optimizing texts, namely SPELL (Semantic Prompt Evolution based on a LLM). The proposed method is evaluated with different LLMs and evolution parameters in different text tasks. Experimental results show that SPELL could rapidly improve the prompts indeed. We further explore the evolution process and discuss on the limitations, potential possibilities and future work.
Pre-trained transformer for adversarial purification
May 27, 2023With more and more deep neural networks being deployed as various daily services, their reliability is essential. It's frightening that deep neural networks are vulnerable and sensitive to adversarial attacks, the most common one of which for the services is evasion-based. Recent works usually strengthen the robustness by adversarial training or leveraging the knowledge of an amount of clean data. However, in practical terms, retraining and redeploying the model need a large computational budget, leading to heavy losses to the online service. In addition, when adversarial examples of a certain attack are detected, only limited adversarial examples are available for the service provider, while much clean data may not be accessible. Given the mentioned problems, we propose a new scenario, RaPiD (Rapid Plug-in Defender), which is to rapidly defend against a certain attack for the frozen original service model with limitations of few clean and adversarial examples. Motivated by the generalization and the universal computation ability of pre-trained transformer models, we come up with a new defender method, CeTaD, which stands for Considering Pre-trained Transformers as Defenders. In particular, we evaluate the effectiveness and the transferability of CeTaD in the case of one-shot adversarial examples and explore the impact of different parts of CeTaD as well as training data conditions. CeTaD is flexible, able to be embedded into an arbitrary differentiable model, and suitable for various types of attacks.