 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Improving UMAP with Geometric and Topological Priors: The JORC-UMAP Algorithm
Jan 23, 2026Nonlinear dimensionality reduction techniques, particularly UMAP, are widely used for visualizing high-dimensional data. However, UMAP's local Euclidean distance assumption often fails to capture intrinsic manifold geometry, leading to topological tearing and structural collapse. We identify UMAP's sensitivity to the k-nearest neighbor graph as a key cause. To address this, we introduce Ollivier-Ricci curvature as a geometric prior, reinforcing edges at geometric bottlenecks and reducing redundant links. Since curvature estimation is noise-sensitive, we also incorporate a topological prior using Jaccard similarity to ensure neighborhood consistency. The resulting method, JORC-UMAP, better distinguishes true manifold structure from spurious connections. Experiments on synthetic and real-world datasets show that JORC-UMAP reduces tearing and collapse more effectively than standard UMAP and other DR methods, as measured by SVM accuracy and triplet preservation scores, while maintaining computational efficiency. This work offers a geometry-aware enhancement to UMAP for more faithful data visualization.
ELBO-T2IAlign: A Generic ELBO-Based Method for Calibrating Pixel-level Text-Image Alignment in Diffusion Models
Jun 11, 2025Diffusion models excel at image generation. Recent studies have shown that these models not only generate high-quality images but also encode text-image alignment information through attention maps or loss functions. This information is valuable for various downstream tasks, including segmentation, text-guided image editing, and compositional image generation. However, current methods heavily rely on the assumption of perfect text-image alignment in diffusion models, which is not the case. In this paper, we propose using zero-shot referring image segmentation as a proxy task to evaluate the pixel-level image and class-level text alignment of popular diffusion models. We conduct an in-depth analysis of pixel-text misalignment in diffusion models from the perspective of training data bias. We find that misalignment occurs in images with small sized, occluded, or rare object classes. Therefore, we propose ELBO-T2IAlign, a simple yet effective method to calibrate pixel-text alignment in diffusion models based on the evidence lower bound (ELBO) of likelihood. Our method is training-free and generic, eliminating the need to identify the specific cause of misalignment and works well across various diffusion model architectures. Extensive experiments on commonly used benchmark datasets on image segmentation and generation have verified the effectiveness of our proposed calibration approach.
GLHF: General Learned Evolutionary Algorithm Via Hyper Functions
May 06, 2024Pretrained Optimization Models (POMs) leverage knowledge gained from optimizing various tasks, providing efficient solutions for new optimization challenges through direct usage or fine-tuning. Despite the inefficiencies and limited generalization abilities observed in current POMs, our proposed model, the general pre-trained optimization model (GPOM), addresses these shortcomings. GPOM constructs a population-based pretrained Black-Box Optimization (BBO) model tailored for continuous optimization. Evaluation on the BBOB benchmark and two robot control tasks demonstrates that GPOM outperforms other pretrained BBO models significantly, especially for high-dimensional tasks. Its direct optimization performance exceeds that of state-of-the-art evolutionary algorithms and POMs. Furthermore, GPOM exhibits robust generalization capabilities across diverse task distributions, dimensions, population sizes, and optimization horizons.
B2Opt: Learning to Optimize Black-box Optimization with Little Budget
Apr 24, 2023Learning to optimize (L2O) has emerged as a powerful framework for black-box optimization (BBO). L2O learns the optimization strategies from the target task automatically without human intervention. This paper focuses on obtaining better performance when handling high-dimensional and expensive BBO with little function evaluation cost, which is the core challenge of black-box optimization. However, current L2O-based methods are weak for this due to a large number of evaluations on expensive black-box functions during training and poor representation of optimization strategy. To achieve this, 1) we utilize the cheap surrogate functions of the target task to guide the design of the optimization strategies; 2) drawing on the mechanism of evolutionary algorithm (EA), we propose a novel framework called B2Opt, which has a stronger representation of optimization strategies. Compared to the BBO baselines, B2Opt can achieve 3 to $10^6$ times performance improvement with less function evaluation cost. We test our proposal in high-dimensional synthetic functions and two real-world applications. We also find that deep B2Opt performs better than shallow ones.
Robustness-aware 2-bit quantization with real-time performance for neural network
Oct 19, 2020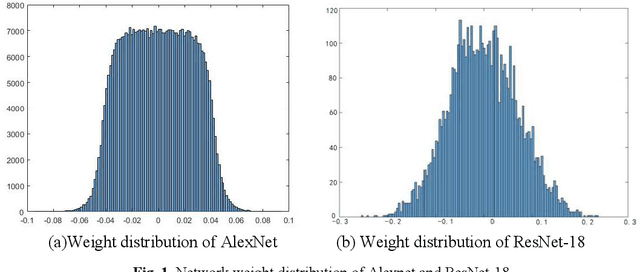
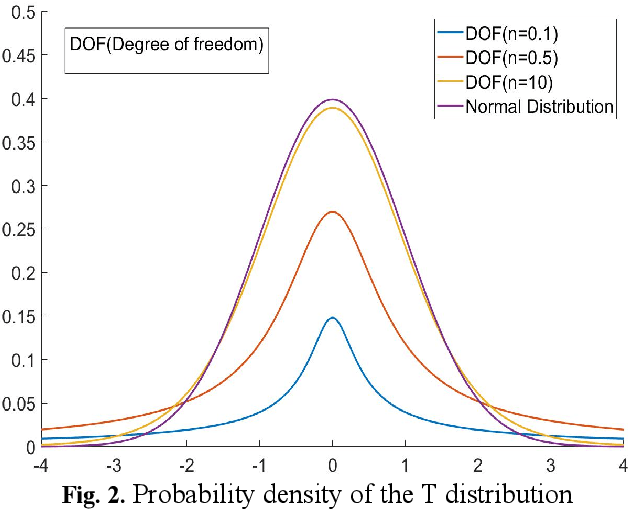
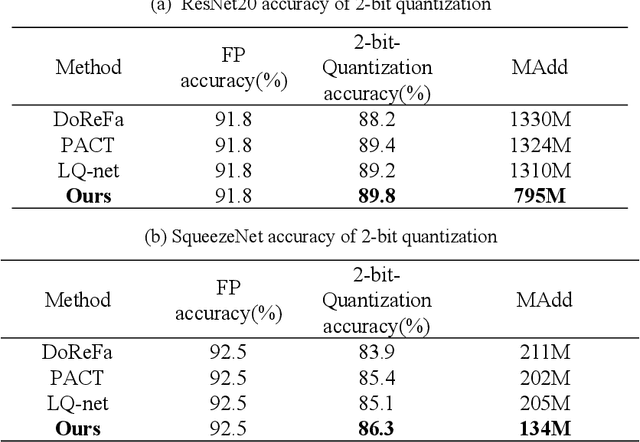
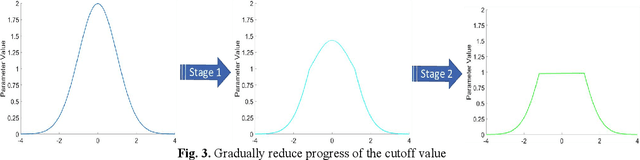
Quantized neural network (NN) with a reduced bit precision is an effective solution to reduces the computational and memory resource requirements and plays a vital role in machine learning. However, it is still challenging to avoid the significant accuracy degradation due to its numerical approximation and lower redundancy. In this paper, a novel robustness-aware 2-bit quantization scheme is proposed for NN base on binary NN and generative adversarial network(GAN), witch improves the performance by enriching the information of binary NN, efficiently extract the structural information and considering the robustness of the quantized NN. Specifically, using shift addition operation to replace the multiply-accumulate in the quantization process witch can effectively speed the NN. Meanwhile, a structural loss between the original NN and quantized NN is proposed to such that the structural information of data is preserved after quantization. The structural information learned from NN not only plays an important role in improving the performance but also allows for further fine tuning of the quantization network by applying the Lipschitz constraint to the structural loss. In addition, we also for the first time take the robustness of the quantized NN into consideration and propose a non-sensitive perturbation loss function by introducing an extraneous term of spectral norm. The experiments are conducted on CIFAR-10 and ImageNet datasets with popular NN( such as MoblieNetV2, SqueezeNet, ResNet20, etc). The experimental results show that the proposed algorithm is more competitive under 2-bit-precision than the state-of-the-art quantization methods. Meanwhile, the experimental results also demonstrate that the proposed method is robust under the FGSM adversarial samples attack.