 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Low-light Enhancement and Deblurring for 3D Dark Scenes
Mar 09, 2026Novel view synthesis from low-light, noisy, and motion-blurred imagery remains a valuable and challenging task. Current volumetric rendering methods struggle with compound degradation, and sequential 2D preprocessing introduces artifacts due to interdependencies. In this work, we introduce FLED-GS, a fast low-light enhancement and deblurring framework that reformulates 3D scene restoration as an alternating cycle of enhancement and reconstruction. Specifically, FLED-GS inserts several intermediate brightness anchors to enable progressive recovery, preventing noise blow-up from harming deblurring or geometry. Each iteration sharpens inputs with an off-the-shelf 2D deblurrer and then performs noise-aware 3DGS reconstruction that estimates and suppresses noise while producing clean priors for the next level. Experiments show FLED-GS outperforms state-of-the-art LuSh-NeRF, achieving 21$\times$ faster training and 11$\times$ faster rendering.
ELBO-T2IAlign: A Generic ELBO-Based Method for Calibrating Pixel-level Text-Image Alignment in Diffusion Models
Jun 11, 2025Diffusion models excel at image generation. Recent studies have shown that these models not only generate high-quality images but also encode text-image alignment information through attention maps or loss functions. This information is valuable for various downstream tasks, including segmentation, text-guided image editing, and compositional image generation. However, current methods heavily rely on the assumption of perfect text-image alignment in diffusion models, which is not the case. In this paper, we propose using zero-shot referring image segmentation as a proxy task to evaluate the pixel-level image and class-level text alignment of popular diffusion models. We conduct an in-depth analysis of pixel-text misalignment in diffusion models from the perspective of training data bias. We find that misalignment occurs in images with small sized, occluded, or rare object classes. Therefore, we propose ELBO-T2IAlign, a simple yet effective method to calibrate pixel-text alignment in diffusion models based on the evidence lower bound (ELBO) of likelihood. Our method is training-free and generic, eliminating the need to identify the specific cause of misalignment and works well across various diffusion model architectures. Extensive experiments on commonly used benchmark datasets on image segmentation and generation have verified the effectiveness of our proposed calibration approach.
Diffusion Model is Secretly a Training-free Open Vocabulary Semantic Segmenter
Sep 06, 2023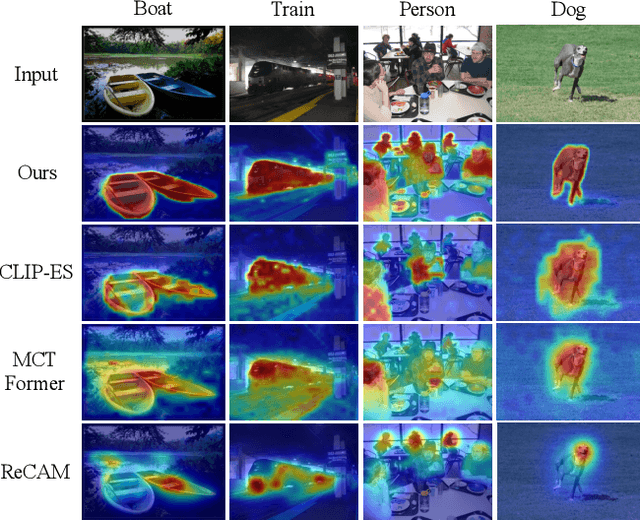
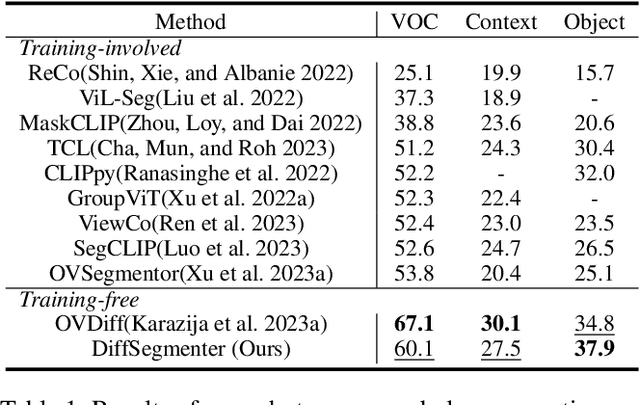
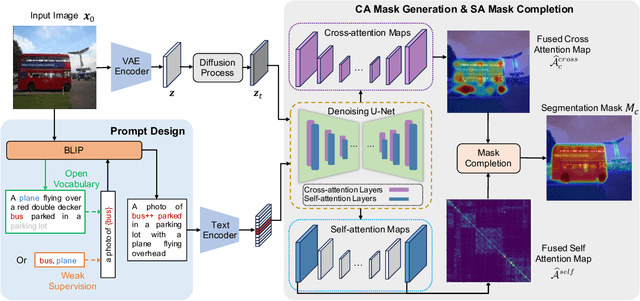
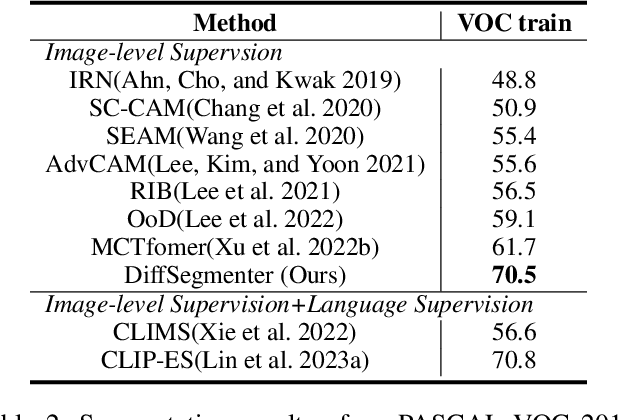
Recent research has explored the utilization of pre-trained text-image discriminative models, such as CLIP, to tackle the challenges associated with open-vocabulary semantic segmentation. However, it is worth noting that the alignment process based on contrastive learning employed by these models may unintentionally result in the loss of crucial localization information and object completeness, which are essential for achieving accurate semantic segmentation. More recently, there has been an emerging interest in extending the application of diffusion models beyond text-to-image generation tasks, particularly in the domain of semantic segmentation. These approaches utilize diffusion models either for generating annotated data or for extracting features to facilitate semantic segmentation. This typically involves training segmentation models by generating a considerable amount of synthetic data or incorporating additional mask annotations. To this end, we uncover the potential of generative text-to-image conditional diffusion models as highly efficient open-vocabulary semantic segmenters, and introduce a novel training-free approach named DiffSegmenter. Specifically, by feeding an input image and candidate classes into an off-the-shelf pre-trained conditional latent diffusion model, the cross-attention maps produced by the denoising U-Net are directly used as segmentation scores, which are further refined and completed by the followed self-attention maps. Additionally, we carefully design effective textual prompts and a category filtering mechanism to further enhance the segmentation results. Extensive experiments on three benchmark datasets show that the proposed DiffSegmenter achieves impressive results for open-vocabulary semantic segmentation.
Inductive Graph Transformer for Delivery Time Estimation
Nov 05, 2022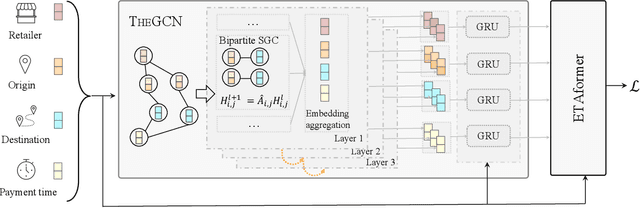
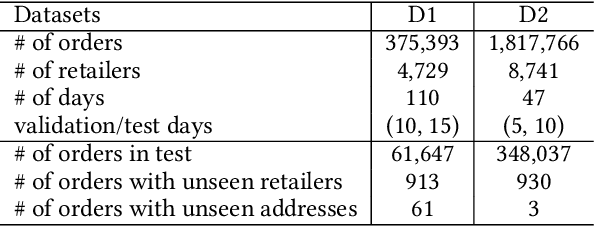
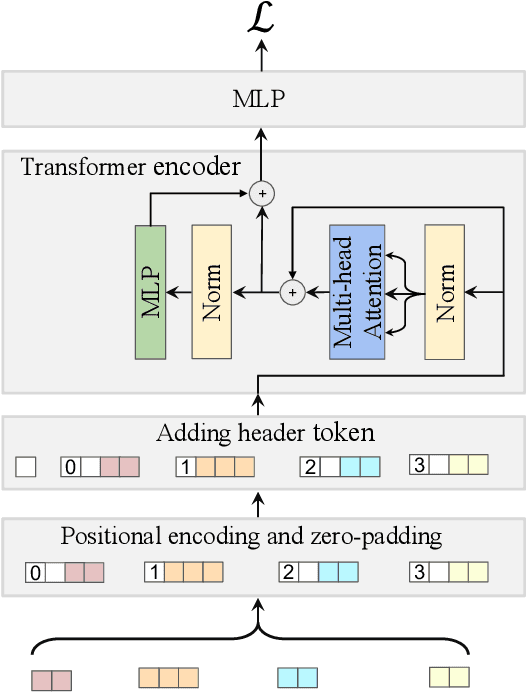

Providing accurate estimated time of package delivery on users' purchasing pages for e-commerce platforms is of great importance to their purchasing decisions and post-purchase experiences. Although this problem shares some common issues with the conventional estimated time of arrival (ETA), it is more challenging with the following aspects: 1) Inductive inference. Models are required to predict ETA for orders with unseen retailers and addresses; 2) High-order interaction of order semantic information. Apart from the spatio-temporal features, the estimated time also varies greatly with other factors, such as the packaging efficiency of retailers, as well as the high-order interaction of these factors. In this paper, we propose an inductive graph transformer (IGT) that leverages raw feature information and structural graph data to estimate package delivery time. Different from previous graph transformer architectures, IGT adopts a decoupled pipeline and trains transformer as a regression function that can capture the multiplex information from both raw feature and dense embeddings encoded by a graph neural network (GNN). In addition, we further simplify the GNN structure by removing its non-linear activation and the learnable linear transformation matrix. The reduced parameter search space and linear information propagation in the simplified GNN enable the IGT to be applied in large-scale industrial scenarios. Experiments on real-world logistics datasets show that our proposed model can significantly outperform the state-of-the-art methods on estimation of delivery time. The source code is available at: https://github.com/enoche/IGT-WSDM23.
A Survey on Legal Judgment Prediction: Datasets, Metrics, Models and Challenges
Apr 11, 2022
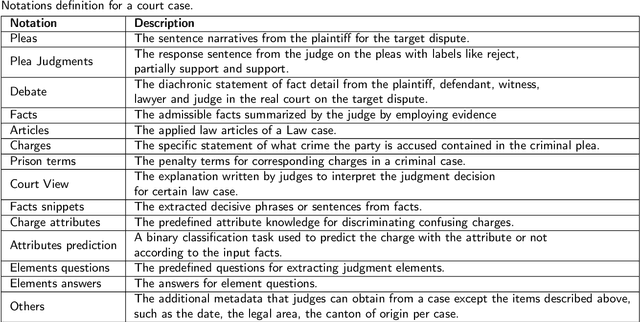
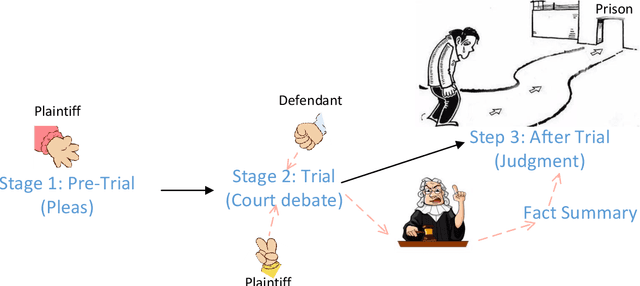
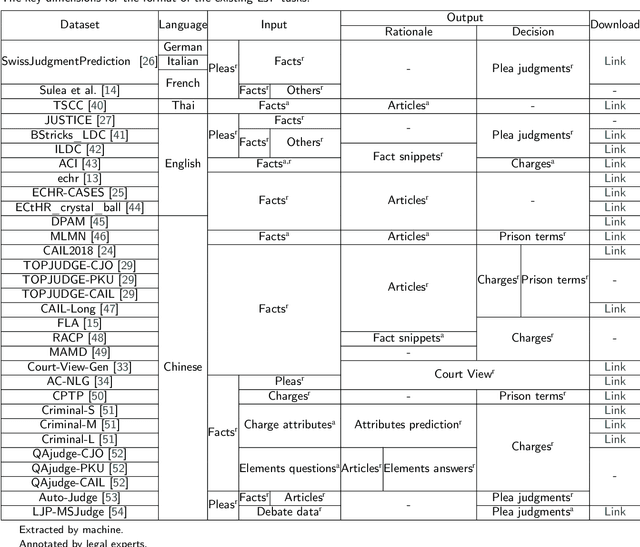
Legal judgment prediction (LJP) applies Natural Language Processing (NLP) techniques to predict judgment results based on fact descriptions automatically. Recently, large-scale public datasets and advances in NLP research have led to increasing interest in LJP. Despite a clear gap between machine and human performance, impressive results have been achieved in various benchmark datasets. In this paper, to address the current lack of comprehensive survey of existing LJP tasks, datasets, models and evaluations, (1) we analyze 31 LJP datasets in 6 languages, present their construction process and define a classification method of LJP with 3 different attributes; (2) we summarize 14 evaluation metrics under four categories for different outputs of LJP tasks; (3) we review 12 legal-domain pretrained models in 3 languages and highlight 3 major research directions for LJP; (4) we show the state-of-art results for 8 representative datasets from different court cases and discuss the open challenges. This paper can provide up-to-date and comprehensive reviews to help readers understand the status of LJP. We hope to facilitate both NLP researchers and legal professionals for further joint efforts in this problem.