 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Legal Judgment Prediction: Datasets, Metrics, Models and Challenges
Paper and Code

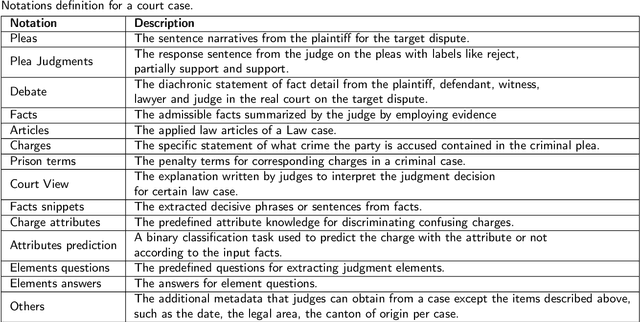
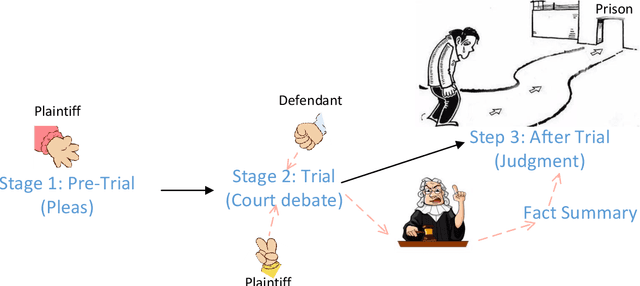
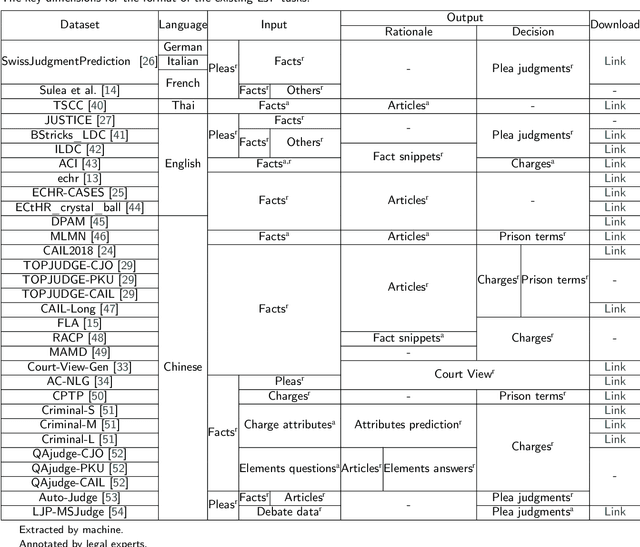
Legal judgment prediction (LJP) applies Natural Language Processing (NLP) techniques to predict judgment results based on fact descriptions automatically. Recently, large-scale public datasets and advances in NLP research have led to increasing interest in LJP. Despite a clear gap between machine and human performance, impressive results have been achieved in various benchmark datasets. In this paper, to address the current lack of comprehensive survey of existing LJP tasks, datasets, models and evaluations, (1) we analyze 31 LJP datasets in 6 languages, present their construction process and define a classification method of LJP with 3 different attributes; (2) we summarize 14 evaluation metrics under four categories for different outputs of LJP tasks; (3) we review 12 legal-domain pretrained models in 3 languages and highlight 3 major research directions for LJP; (4) we show the state-of-art results for 8 representative datasets from different court cases and discuss the open challenges. This paper can provide up-to-date and comprehensive reviews to help readers understand the status of LJP. We hope to facilitate both NLP researchers and legal professionals for further joint efforts in this problem.