 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Model is Secretly a Training-free Open Vocabulary Semantic Segmenter
Paper and Code
Sep 06, 2023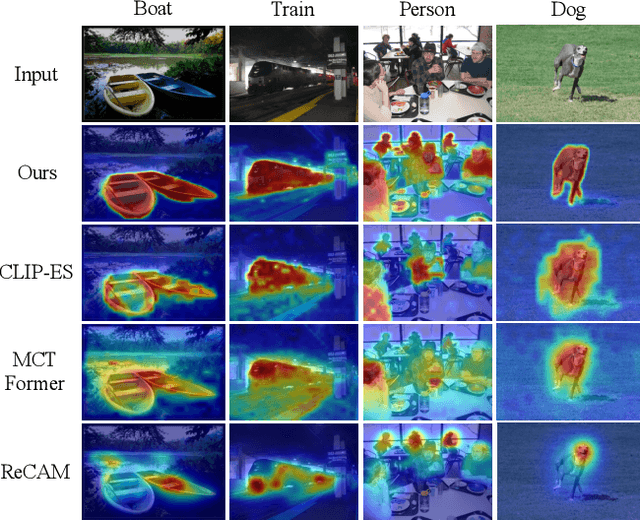
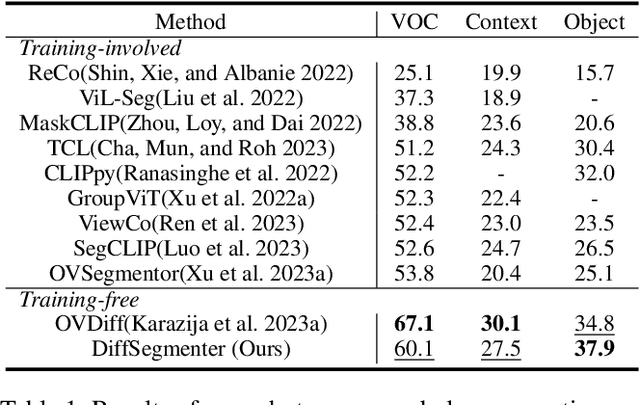
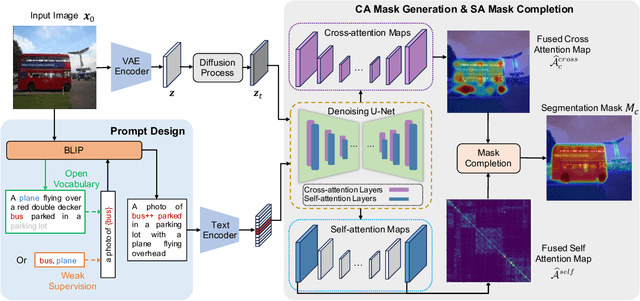
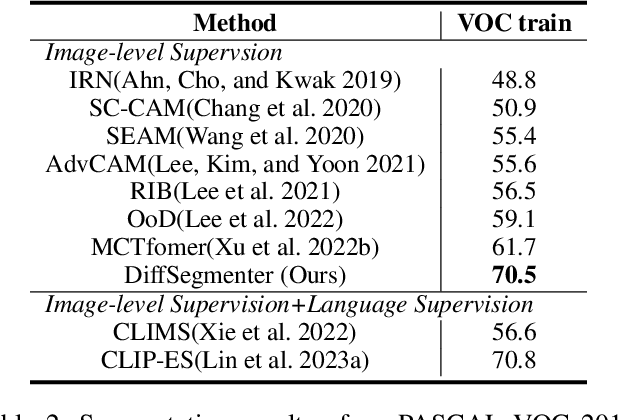
Recent research has explored the utilization of pre-trained text-image discriminative models, such as CLIP, to tackle the challenges associated with open-vocabulary semantic segmentation. However, it is worth noting that the alignment process based on contrastive learning employed by these models may unintentionally result in the loss of crucial localization information and object completeness, which are essential for achieving accurate semantic segmentation. More recently, there has been an emerging interest in extending the application of diffusion models beyond text-to-image generation tasks, particularly in the domain of semantic segmentation. These approaches utilize diffusion models either for generating annotated data or for extracting features to facilitate semantic segmentation. This typically involves training segmentation models by generating a considerable amount of synthetic data or incorporating additional mask annotations. To this end, we uncover the potential of generative text-to-image conditional diffusion models as highly efficient open-vocabulary semantic segmenters, and introduce a novel training-free approach named DiffSegmenter. Specifically, by feeding an input image and candidate classes into an off-the-shelf pre-trained conditional latent diffusion model, the cross-attention maps produced by the denoising U-Net are directly used as segmentation scores, which are further refined and completed by the followed self-attention maps. Additionally, we carefully design effective textual prompts and a category filtering mechanism to further enhance the segmentation results. Extensive experiments on three benchmark datasets show that the proposed DiffSegmenter achieves impressive results for open-vocabulary semantic segmentation.