 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Skeleton Meta-Prototype Contrastive Learning with Hard Skeleton Mining for Unsupervised Person Re-Identification
Jul 26, 2023With rapid advancements in depth sensors and deep learning, skeleton-based person re-identification (re-ID) models have recently achieved remarkable progress with many advantages. Most existing solutions learn single-level skeleton features from body joints with the assumption of equal skeleton importance, while they typically lack the ability to exploit more informative skeleton features from various levels such as limb level with more global body patterns. The label dependency of these methods also limits their flexibility in learning more general skeleton representations. This paper proposes a generic unsupervised Hierarchical skeleton Meta-Prototype Contrastive learning (Hi-MPC) approach with Hard Skeleton Mining (HSM) for person re-ID with unlabeled 3D skeletons. Firstly, we construct hierarchical representations of skeletons to model coarse-to-fine body and motion features from the levels of body joints, components, and limbs. Then a hierarchical meta-prototype contrastive learning model is proposed to cluster and contrast the most typical skeleton features ("prototypes") from different-level skeletons. By converting original prototypes into meta-prototypes with multiple homogeneous transformations, we induce the model to learn the inherent consistency of prototypes to capture more effective skeleton features for person re-ID. Furthermore, we devise a hard skeleton mining mechanism to adaptively infer the informative importance of each skeleton, so as to focus on harder skeletons to learn more discriminative skeleton representations. Extensive evaluations on five datasets demonstrate that our approach outperforms a wide variety of state-of-the-art skeleton-based methods. We further show the general applicability of our method to cross-view person re-ID and RGB-based scenarios with estimated skeletons.
Can ChatGPT Assess Human Personalities? A General Evaluation Framework
Mar 07, 2023Large Language Models (LLMs) especially ChatGPT have produced impressive results in various areas, but their potential human-like psychology is still largely unexplored. Existing works study the virtual personalities of LLMs but rarely explore the possibility of analyzing human personalities via LLMs. This paper presents a generic evaluation framework for LLMs to assess human personalities based on Myers Briggs Type Indicator (MBTI) tests. Specifically, we first devise unbiased prompts by randomly permuting options in MBTI questions and adopt the average testing result to encourage more impartial answer generation. Then, we propose to replace the subject in question statements to enable flexible queries and assessments on different subjects from LLMs. Finally, we re-formulate the question instructions in a manner of correctness evaluation to facilitate LLMs to generate clearer responses. The proposed framework enables LLMs to flexibly assess personalities of different groups of people. We further propose three evaluation metrics to measure the consistency, robustness, and fairness of assessment results from state-of-the-art LLMs including ChatGPT and InstructGPT. Our experiments reveal ChatGPT's ability to assess human personalities, and the average results demonstrate that it can achieve more consistent and fairer assessments in spite of lower robustness against prompt biases compared with InstructGPT.
Inductive Graph Transformer for Delivery Time Estimation
Nov 05, 2022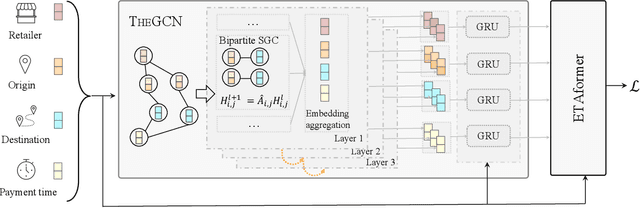
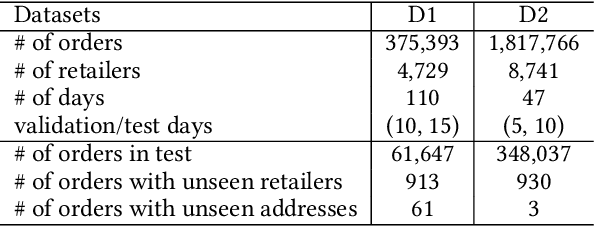
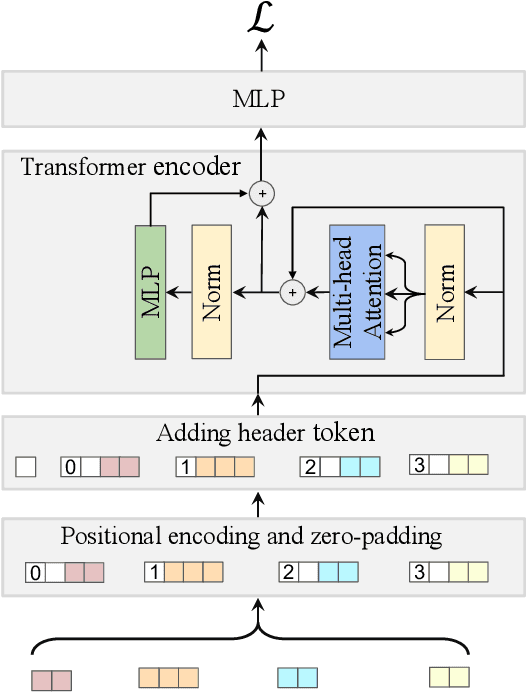

Providing accurate estimated time of package delivery on users' purchasing pages for e-commerce platforms is of great importance to their purchasing decisions and post-purchase experiences. Although this problem shares some common issues with the conventional estimated time of arrival (ETA), it is more challenging with the following aspects: 1) Inductive inference. Models are required to predict ETA for orders with unseen retailers and addresses; 2) High-order interaction of order semantic information. Apart from the spatio-temporal features, the estimated time also varies greatly with other factors, such as the packaging efficiency of retailers, as well as the high-order interaction of these factors. In this paper, we propose an inductive graph transformer (IGT) that leverages raw feature information and structural graph data to estimate package delivery time. Different from previous graph transformer architectures, IGT adopts a decoupled pipeline and trains transformer as a regression function that can capture the multiplex information from both raw feature and dense embeddings encoded by a graph neural network (GNN). In addition, we further simplify the GNN structure by removing its non-linear activation and the learnable linear transformation matrix. The reduced parameter search space and linear information propagation in the simplified GNN enable the IGT to be applied in large-scale industrial scenarios. Experiments on real-world logistics datasets show that our proposed model can significantly outperform the state-of-the-art methods on estimation of delivery time. The source code is available at: https://github.com/enoche/IGT-WSDM23.
A Survey of Computer Vision Technologies In Urban and Controlled-environment Agriculture
Oct 20, 2022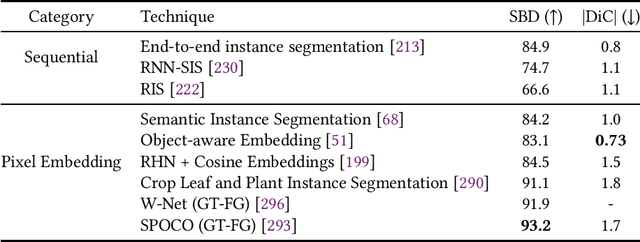
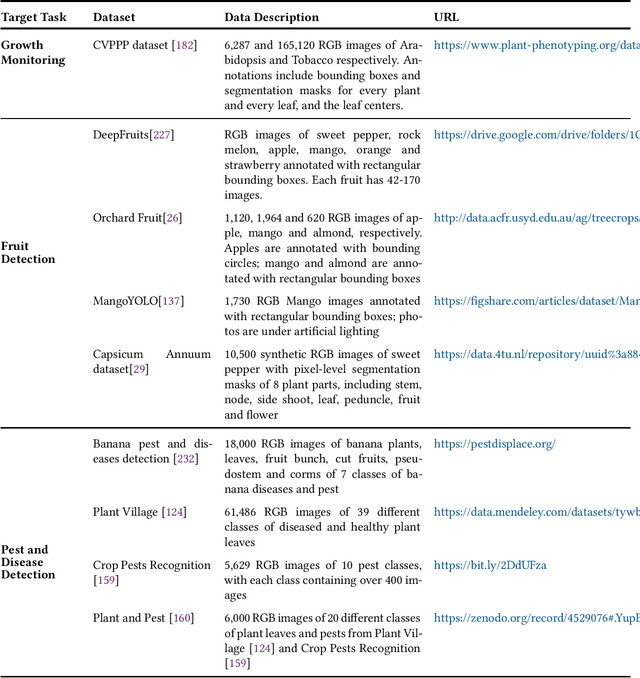
In the evolution of agriculture to its next stage, Agriculture 5.0, artificial intelligence will play a central role. Controlled-environment agriculture, or CEA, is a special form of urban and suburban agricultural practice that offers numerous economic, environmental, and social benefits, including shorter transportation routes to population centers, reduced environmental impact, and increased productivity. Due to its ability to control environmental factors, CEA couples well with computer vision (CV) in the adoption of real-time monitoring of the plant conditions and autonomous cultivation and harvesting. The objective of this paper is to familiarize CV researchers with agricultural applications and agricultural practitioners with the solutions offered by CV. We identify five major CV applications in CEA, analyze their requirements and motivation, and survey the state of the art as reflected in 68 technical papers using deep learning methods. In addition, we discuss five key subareas of computer vision and how they related to these CEA problems, as well as nine vision-based CEA datasets. We hope the survey will help researchers quickly gain a bird-eye view of the striving research area and will spark inspiration for new research and development.
A Survey of Fairness-Aware Federated Learning
Nov 02, 2021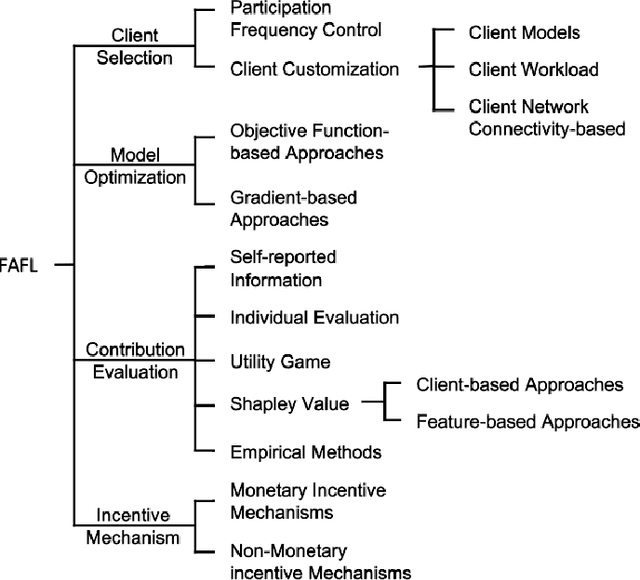
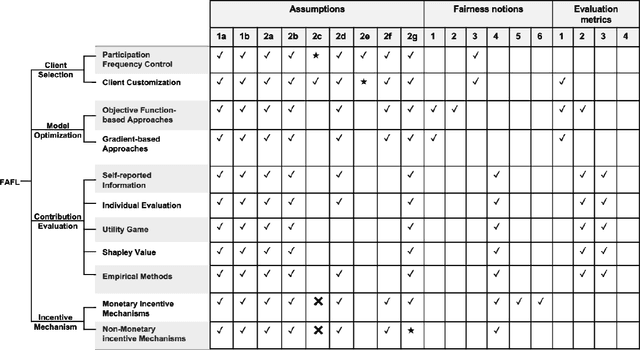
Recent advances in Federated Learning (FL) have brought large-scale machine learning opportunities for massive distributed clients with performance and data privacy guarantees. However, most current works only focus on the interest of the central controller in FL, and ignore the interests of clients. This may result in unfairness which discourages clients from actively participating in the learning process and damages the sustainability of the whole FL system. Therefore, the topic of ensuring fairness in an FL is attracting a great deal of research interest. In recent years, diverse Fairness-Aware FL (FAFL) approaches have been proposed in an effort to achieve fairness in FL from different viewpoints. However, there is no comprehensive survey which helps readers gain insight into this interdisciplinary field. This paper aims to provide such a survey. By examining the fundamental and simplifying assumptions, as well as the notions of fairness adopted by existing literature in this field, we propose a taxonomy of FAFL approaches covering major steps in FL, including client selection, optimization, contribution evaluation and incentive distribution. In addition, we discuss the main metrics for experimentally evaluating the performance of FAFL approaches, and suggest some promising future research directions.
A Contract Theory based Incentive Mechanism for Federated Learning
Aug 12, 2021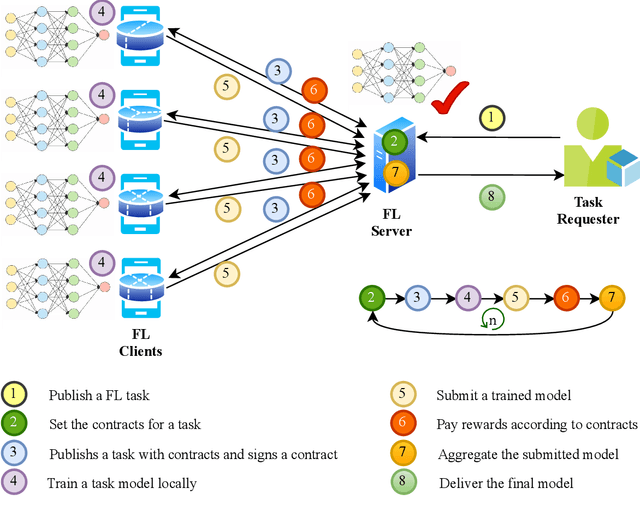

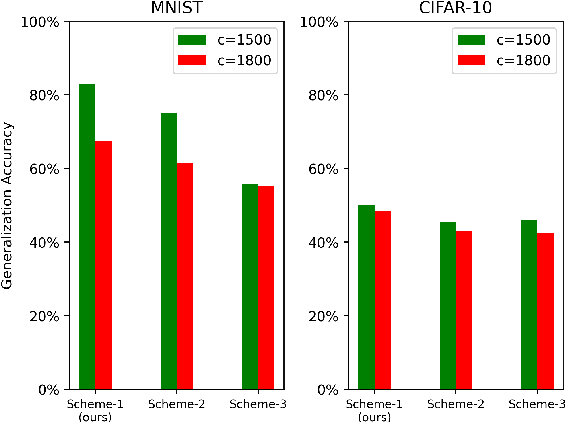
Federated learning (FL) serves as a data privacy-preserved machine learning paradigm, and realizes the collaborative model trained by distributed clients. To accomplish an FL task, the task publisher needs to pay financial incentives to the FL server and FL server offloads the task to the contributing FL clients. It is challenging to design proper incentives for the FL clients due to the fact that the task is privately trained by the clients. This paper aims to propose a contract theory based FL task training model towards minimizing incentive budget subject to clients being individually rational (IR) and incentive compatible (IC) in each FL training round. We design a two-dimensional contract model by formally defining two private types of clients, namely data quality and computation effort. To effectively aggregate the trained models, a contract-based aggregator is proposed. We analyze the feasible and optimal contract solutions to the proposed contract model. %Experimental results demonstrate that the proposed framework and contract model can effective improve the generation accuracy of FL tasks. Experimental results show that the generalization accuracy of the FL tasks can be improved by the proposed incentive mechanism where contract-based aggregation is applied.
Incentive Mechanism Design for Resource Sharing in Collaborative Edge Learning
May 31, 2020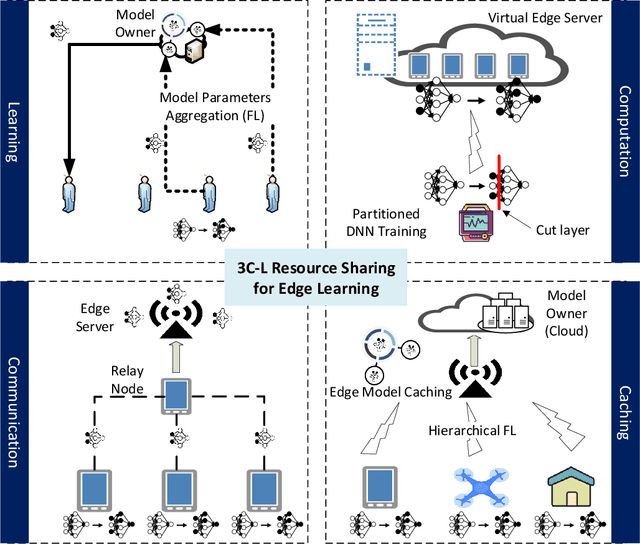
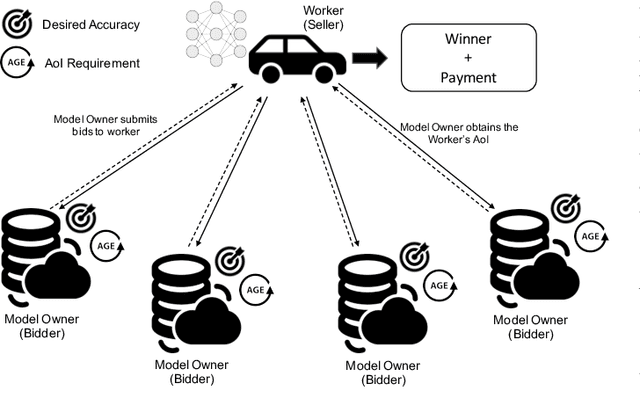
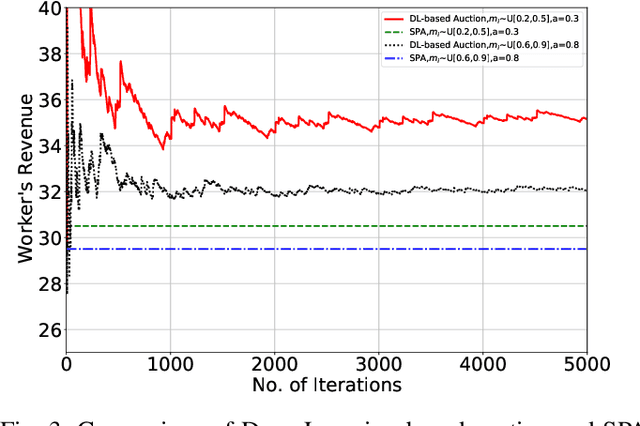
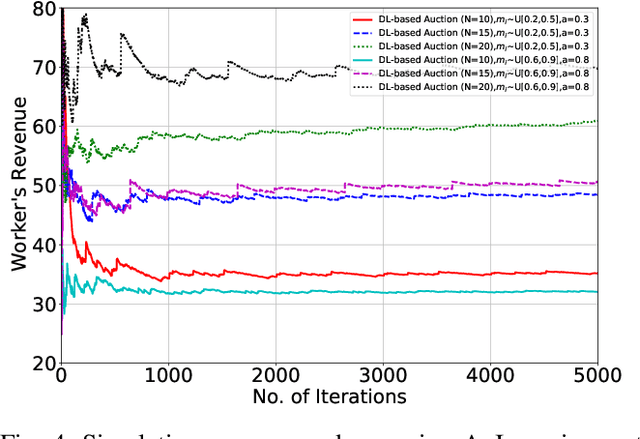
In 5G and Beyond networks, Artificial Intelligence applications are expected to be increasingly ubiquitous. This necessitates a paradigm shift from the current cloud-centric model training approach to the Edge Computing based collaborative learning scheme known as edge learning, in which model training is executed at the edge of the network. In this article, we first introduce the principles and technologies of collaborative edge learning. Then, we establish that a successful, scalable implementation of edge learning requires the communication, caching, computation, and learning resources (3C-L) of end devices and edge servers to be leveraged jointly in an efficient manner. However, users may not consent to contribute their resources without receiving adequate compensation. In consideration of the heterogeneity of edge nodes, e.g., in terms of available computation resources, we discuss the challenges of incentive mechanism design to facilitate resource sharing for edge learning. Furthermore, we present a case study involving optimal auction design using Deep Learning to price fresh data contributed for edge learning. The performance evaluation shows the revenue maximizing properties of our proposed auction over the benchmark schemes.
Ethically Aligned Opportunistic Scheduling for Productive Laziness
Jan 02, 2019
In artificial intelligence (AI) mediated workforce management systems (e.g., crowdsourcing), long-term success depends on workers accomplishing tasks productively and resting well. This dual objective can be summarized by the concept of productive laziness. Existing scheduling approaches mostly focus on efficiency but overlook worker wellbeing through proper rest. In order to enable workforce management systems to follow the IEEE Ethically Aligned Design guidelines to prioritize worker wellbeing, we propose a distributed Computational Productive Laziness (CPL) approach in this paper. It intelligently recommends personalized work-rest schedules based on local data concerning a worker's capabilities and situational factors to incorporate opportunistic resting and achieve superlinear collective productivity without the need for explicit coordination messages. Extensive experiments based on a real-world dataset of over 5,000 workers demonstrate that CPL enables workers to spend 70% of the effort to complete 90% of the tasks on average, providing more ethically aligned scheduling than existing approaches.
Building Ethics into Artificial Intelligence
Dec 07, 2018
As artificial intelligence (AI) systems become increasingly ubiquitous, the topic of AI governance for ethical decision-making by AI has captured public imagination. Within the AI research community, this topic remains less familiar to many researchers. In this paper, we complement existing surveys, which largely focused on the psychological, social and legal discussions of the topic, with an analysis of recent advances in technical solutions for AI governance. By reviewing publications in leading AI conferences including AAAI, AAMAS, ECAI and IJCAI, we propose a taxonomy which divides the field into four areas: 1) exploring ethical dilemmas; 2) individual ethical decision frameworks; 3) collective ethical decision frameworks; and 4) ethics in human-AI interactions. We highlight the intuitions and key techniques used in each approach, and discuss promising future research directions towards successful integration of ethical AI systems into human societies.
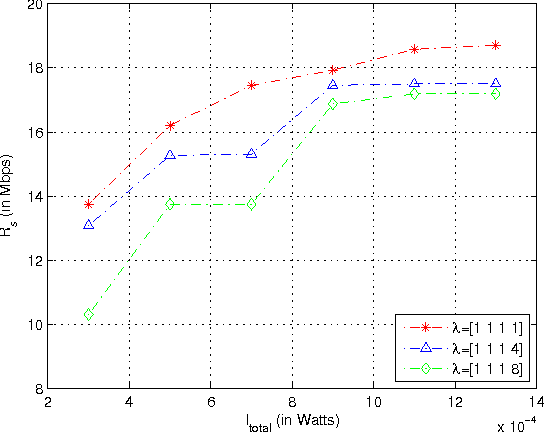
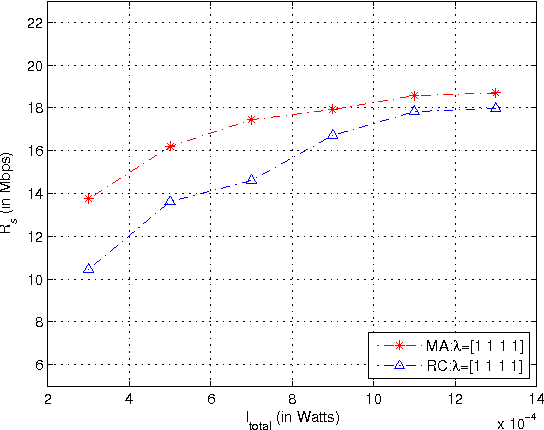
Fitness Landscape Analysis for Dynamic Resource Allocation in Multiuser OFDM Based Cognitive Radio Systems
Mar 07, 2010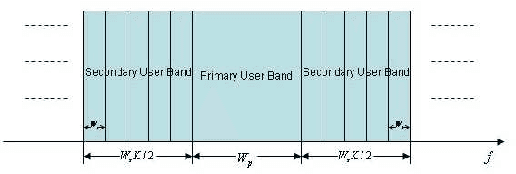
This paper has been withdrawn.