 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigDocs: An Open and Permissively-Licensed Dataset for Training Multimodal Models on Document and Code Tasks
Dec 05, 2024



Multimodal AI has the potential to significantly enhance document-understanding tasks, such as processing receipts, understanding workflows, extracting data from documents, and summarizing reports. Code generation tasks that require long-structured outputs can also be enhanced by multimodality. Despite this, their use in commercial applications is often limited due to limited access to training data and restrictive licensing, which hinders open access. To address these limitations, we introduce BigDocs-7.5M, a high-quality, open-access dataset comprising 7.5 million multimodal documents across 30 tasks. We use an efficient data curation process to ensure our data is high-quality and license-permissive. Our process emphasizes accountability, responsibility, and transparency through filtering rules, traceable metadata, and careful content analysis. Additionally, we introduce BigDocs-Bench, a benchmark suite with 10 novel tasks where we create datasets that reflect real-world use cases involving reasoning over Graphical User Interfaces (GUI) and code generation from images. Our experiments show that training with BigDocs-Bench improves average performance up to 25.8% over closed-source GPT-4o in document reasoning and structured output tasks such as Screenshot2HTML or Image2Latex generation. Finally, human evaluations showed a preference for outputs from models trained on BigDocs over GPT-4o. This suggests that BigDocs can help both academics and the open-source community utilize and improve AI tools to enhance multimodal capabilities and document reasoning. The project is hosted at https://bigdocs.github.io .
Ethically Aligned Opportunistic Scheduling for Productive Laziness
Jan 02, 2019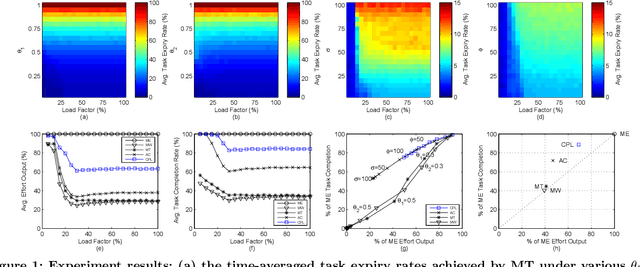
In artificial intelligence (AI) mediated workforce management systems (e.g., crowdsourcing), long-term success depends on workers accomplishing tasks productively and resting well. This dual objective can be summarized by the concept of productive laziness. Existing scheduling approaches mostly focus on efficiency but overlook worker wellbeing through proper rest. In order to enable workforce management systems to follow the IEEE Ethically Aligned Design guidelines to prioritize worker wellbeing, we propose a distributed Computational Productive Laziness (CPL) approach in this paper. It intelligently recommends personalized work-rest schedules based on local data concerning a worker's capabilities and situational factors to incorporate opportunistic resting and achieve superlinear collective productivity without the need for explicit coordination messages. Extensive experiments based on a real-world dataset of over 5,000 workers demonstrate that CPL enables workers to spend 70% of the effort to complete 90% of the tasks on average, providing more ethically aligned scheduling than existing approaches.
A Survey on Artificial Intelligence and Data Mining for MOOCs
Jan 26, 2016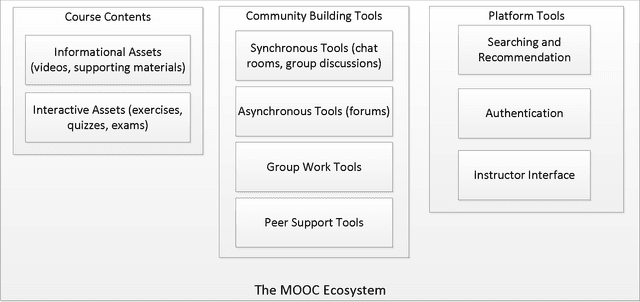
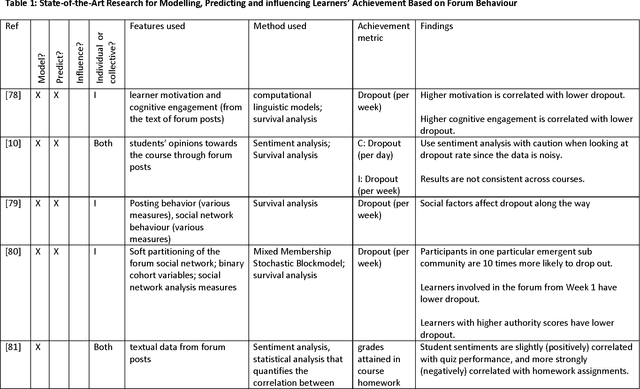
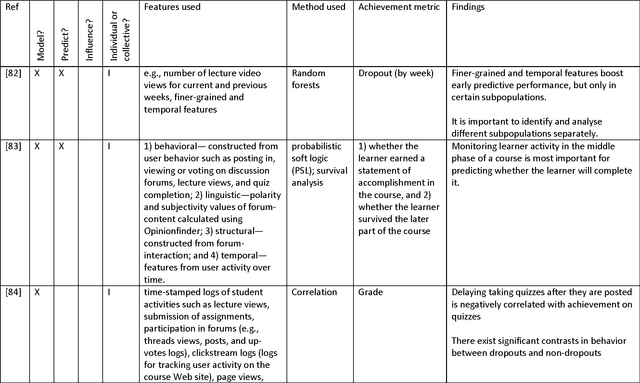
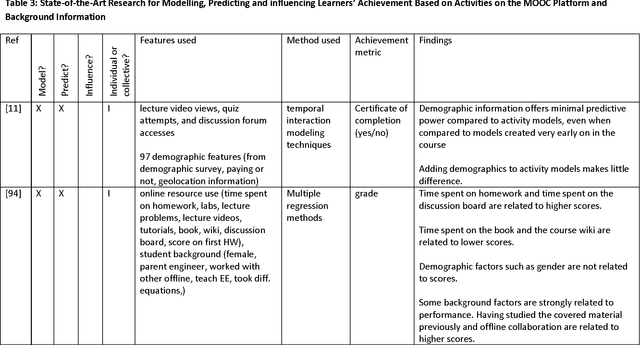
Massive Open Online Courses (MOOCs) have gained tremendous popularity in the last few years. Thanks to MOOCs, millions of learners from all over the world have taken thousands of high-quality courses for free. Putting together an excellent MOOC ecosystem is a multidisciplinary endeavour that requires contributions from many different fields. Artificial intelligence (AI) and data mining (DM) are two such fields that have played a significant role in making MOOCs what they are today. By exploiting the vast amount of data generated by learners engaging in MOOCs, DM improves our understanding of the MOOC ecosystem and enables MOOC practitioners to deliver better courses. Similarly, AI, supported by DM, can greatly improve student experience and learning outcomes. In this survey paper, we first review the state-of-the-art artificial intelligence and data mining research applied to MOOCs, emphasising the use of AI and DM tools and techniques to improve student engagement, learning outcomes, and our understanding of the MOOC ecosystem. We then offer an overview of key trends and important research to carry out in the fields of AI and DM so that MOOCs can reach their full potential.
Decentralized, Adaptive, Look-Ahead Particle Filtering
Mar 12, 2012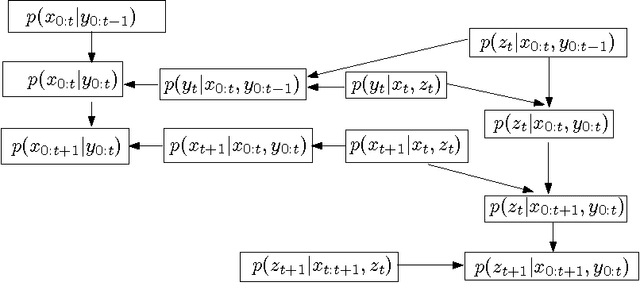



The decentralized particle filter (DPF) was proposed recently to increase the level of parallelism of particle filtering. Given a decomposition of the state space into two nested sets of variables, the DPF uses a particle filter to sample the first set and then conditions on this sample to generate a set of samples for the second set of variables. The DPF can be understood as a variant of the popular Rao-Blackwellized particle filter (RBPF), where the second step is carried out using Monte Carlo approximations instead of analytical inference. As a result, the range of applications of the DPF is broader than the one for the RBPF. In this paper, we improve the DPF in two ways. First, we derive a Monte Carlo approximation of the optimal proposal distribution and, consequently, design and implement a more efficient look-ahead DPF. Although the decentralized filters were initially designed to capitalize on parallel implementation, we show that the look-ahead DPF can outperform the standard particle filter even on a single machine. Second, we propose the use of bandit algorithms to automatically configure the state space decomposition of the DPF.