 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Multimodal Learning Framework For Intake Gesture Detection Using Contactless Radar and Wearable IMU Sensors
Jul 09, 2025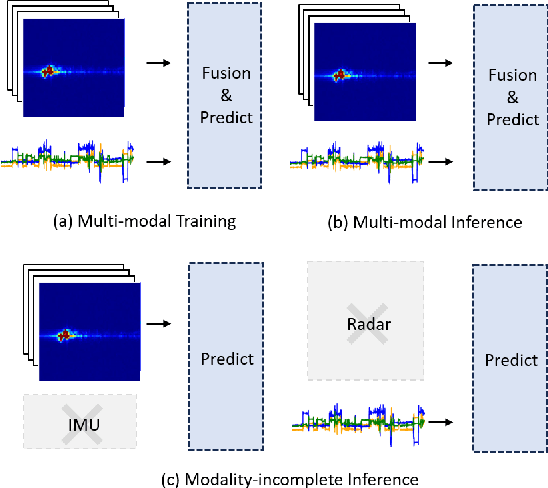


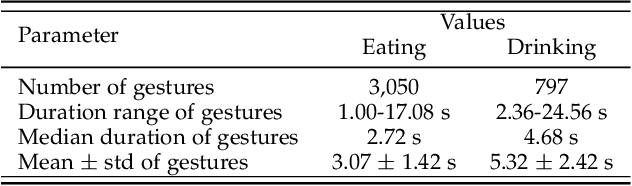
Automated food intake gesture detection plays a vital role in dietary monitoring, enabling objective and continuous tracking of eating behaviors to support better health outcomes. Wrist-worn inertial measurement units (IMUs) have been widely used for this task with promising results. More recently, contactless radar sensors have also shown potential. This study explores whether combining wearable and contactless sensing modalities through multimodal learning can further improve detection performance. We also address a major challenge in multimodal learning: reduced robustness when one modality is missing. To this end, we propose a robust multimodal temporal convolutional network with cross-modal attention (MM-TCN-CMA), designed to integrate IMU and radar data, enhance gesture detection, and maintain performance under missing modality conditions. A new dataset comprising 52 meal sessions (3,050 eating gestures and 797 drinking gestures) from 52 participants is developed and made publicly available. Experimental results show that the proposed framework improves the segmental F1-score by 4.3% and 5.2% over unimodal Radar and IMU models, respectively. Under missing modality scenarios, the framework still achieves gains of 1.3% and 2.4% for missing radar and missing IMU inputs. This is the first study to demonstrate a robust multimodal learning framework that effectively fuses IMU and radar data for food intake gesture detection.
AI-assisted Automatic Jump Detection and Height Estimation in Volleyball Using a Waist-worn IMU
May 09, 2025The physical load of jumps plays a critical role in injury prevention for volleyball players. However, manual video analysis of jump activities is time-intensive and costly, requiring significant effort and expensive hardware setups. The advent of the inertial measurement unit (IMU) and machine learning algorithms offers a convenient and efficient alternative. Despite this, previous research has largely focused on either jump classification or physical load estimation, leaving a gap in integrated solutions. This study aims to present a pipeline to automatically detect jumps and predict heights using data from a waist-worn IMU. The pipeline leverages a Multi-Stage Temporal Convolutional Network (MS-TCN) to detect jump segments in time-series data and classify the specific jump category. Subsequently, jump heights are estimated using three downstream regression machine learning models based on the identified segments. Our method is verified on a dataset comprising 10 players and 337 jumps. Compared to the result of VERT in height estimation (R-squared=-1.53), a commercial device commonly used in jump landing tasks, our method not only accurately identifies jump activities and their specific types (F1-score=0.90) but also demonstrates superior performance in height prediction (R-squared=0.50). This integrated solution offers a promising tool for monitoring physical load and mitigating injury risk in volleyball players.
Skeleton-Based Intake Gesture Detection With Spatial-Temporal Graph Convolutional Networks
Apr 14, 2025



Overweight and obesity have emerged as widespread societal challenges, frequently linked to unhealthy eating patterns. A promising approach to enhance dietary monitoring in everyday life involves automated detection of food intake gestures. This study introduces a skeleton based approach using a model that combines a dilated spatial-temporal graph convolutional network (ST-GCN) with a bidirectional long-short-term memory (BiLSTM) framework, as called ST-GCN-BiLSTM, to detect intake gestures. The skeleton-based method provides key benefits, including environmental robustness, reduced data dependency, and enhanced privacy preservation. Two datasets were employed for model validation. The OREBA dataset, which consists of laboratory-recorded videos, achieved segmental F1-scores of 86.18% and 74.84% for identifying eating and drinking gestures. Additionally, a self-collected dataset using smartphone recordings in more adaptable experimental conditions was evaluated with the model trained on OREBA, yielding F1-scores of 85.40% and 67.80% for detecting eating and drinking gestures. The results not only confirm the feasibility of utilizing skeleton data for intake gesture detection but also highlight the robustness of the proposed approach in cross-dataset validation.
Language-Assisted Human Part Motion Learning for Skeleton-Based Temporal Action Segmentation
Oct 08, 2024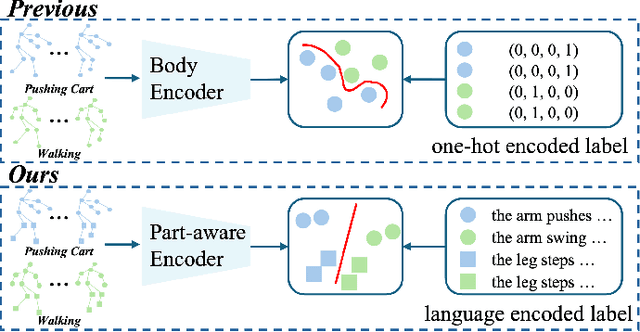
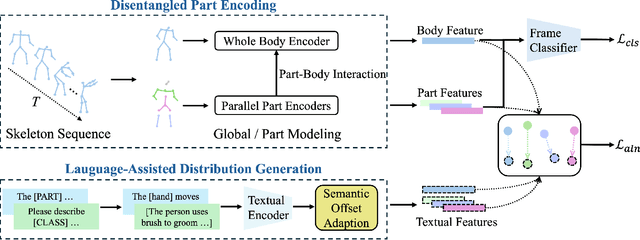
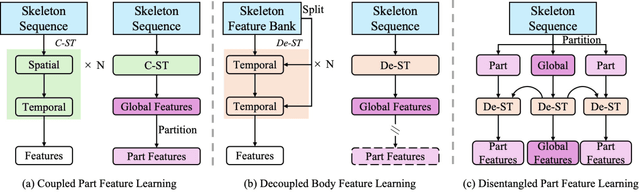
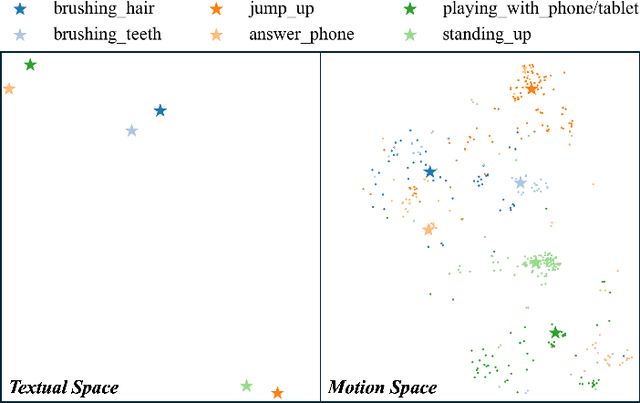
Skeleton-based Temporal Action Segmentation involves the dense action classification of variable-length skeleton sequences. Current approaches primarily apply graph-based networks to extract framewise, whole-body-level motion representations, and use one-hot encoded labels for model optimization. However, whole-body motion representations do not capture fine-grained part-level motion representations and the one-hot encoded labels neglect the intrinsic semantic relationships within the language-based action definitions. To address these limitations, we propose a novel method named Language-assisted Human Part Motion Representation Learning (LPL), which contains a Disentangled Part Motion Encoder (DPE) to extract dual-level (i.e., part and whole-body) motion representations and a Language-assisted Distribution Alignment (LDA) strategy for optimizing spatial relations within representations. Specifically, after part-aware skeleton encoding via DPE, LDA generates dual-level action descriptions to construct a textual embedding space with the help of a large-scale language model. Then, LDA motivates the alignment of the embedding space between text descriptions and motions. This alignment allows LDA not only to enhance intra-class compactness but also to transfer the language-encoded semantic correlations among actions to skeleton-based motion learning. Moreover, we propose a simple yet efficient Semantic Offset Adapter to smooth the cross-domain misalignment. Our experiments indicate that LPL achieves state-of-the-art performance across various datasets (e.g., +4.4\% Accuracy, +5.6\% F1 on the PKU-MMD dataset). Moreover, LDA is compatible with existing methods and improves their performance (e.g., +4.8\% Accuracy, +4.3\% F1 on the LARa dataset) without additional inference costs.
A Masked Semi-Supervised Learning Approach for Otago Micro Labels Recognition
May 22, 2024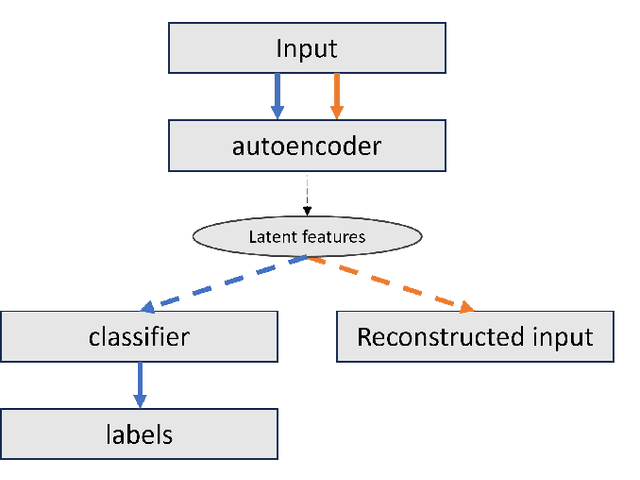

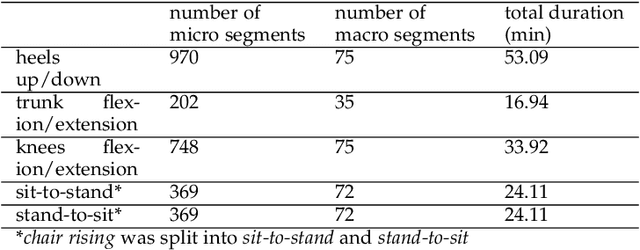

The Otago Exercise Program (OEP) serves as a vital rehabilitation initiative for older adults, aiming to enhance their strength and balance, and consequently prevent falls. While Human Activity Recognition (HAR) systems have been widely employed in recognizing the activities of individuals, existing systems focus on the duration of macro activities (i.e. a sequence of repetitions of the same exercise), neglecting the ability to discern micro activities (i.e. the individual repetitions of the exercises), in the case of OEP. This study presents a novel semi-supervised machine learning approach aimed at bridging this gap in recognizing the micro activities of OEP. To manage the limited dataset size, our model utilizes a Transformer encoder for feature extraction, subsequently classified by a Temporal Convolutional Network (TCN). Simultaneously, the Transformer encoder is employed for masked unsupervised learning to reconstruct input signals. Results indicate that the masked unsupervised learning task enhances the performance of the supervised learning (classification task), as evidenced by f1-scores surpassing the clinically applicable threshold of 0.8. From the micro activities, two clinically relevant outcomes emerge: counting the number of repetitions of each exercise and calculating the velocity during chair rising. These outcomes enable the automatic monitoring of exercise intensity and difficulty in the daily lives of older adults.
DS-MS-TCN: Otago Exercises Recognition with a Dual-Scale Multi-Stage Temporal Convolutional Network
Feb 07, 2024



The Otago Exercise Program (OEP) represents a crucial rehabilitation initiative tailored for older adults, aimed at enhancing balance and strength. Despite previous efforts utilizing wearable sensors for OEP recognition, existing studies have exhibited limitations in terms of accuracy and robustness. This study addresses these limitations by employing a single waist-mounted Inertial Measurement Unit (IMU) to recognize OEP exercises among community-dwelling older adults in their daily lives. A cohort of 36 older adults participated in laboratory settings, supplemented by an additional 7 older adults recruited for at-home assessments. The study proposes a Dual-Scale Multi-Stage Temporal Convolutional Network (DS-MS-TCN) designed for two-level sequence-to-sequence classification, incorporating them in one loss function. In the first stage, the model focuses on recognizing each repetition of the exercises (micro labels). Subsequent stages extend the recognition to encompass the complete range of exercises (macro labels). The DS-MS-TCN model surpasses existing state-of-the-art deep learning models, achieving f1-scores exceeding 80% and Intersection over Union (IoU) f1-scores surpassing 60% for all four exercises evaluated. Notably, the model outperforms the prior study utilizing the sliding window technique, eliminating the need for post-processing stages and window size tuning. To our knowledge, we are the first to present a novel perspective on enhancing Human Activity Recognition (HAR) systems through the recognition of each repetition of activities.
A Multi-Stage Temporal Convolutional Network for Volleyball Jumps Classification Using a Waist-Mounted IMU
Oct 19, 2023



Monitoring the number of jumps for volleyball players during training or a match can be crucial to prevent injuries, yet the measurement requires considerable workload and cost using traditional methods such as video analysis. Also, existing methods do not provide accurate differentiation between different types of jumps. In this study, an unobtrusive system with a single inertial measurement unit (IMU) on the waist was proposed to recognize the types of volleyball jumps. A Multi-Layer Temporal Convolutional Network (MS-TCN) was applied for sample-wise classification. The model was evaluated on ten volleyball players and twenty-six volleyball players, during a lab session with a fixed protocol of jumping and landing tasks, and during four volleyball training sessions, respectively. The MS-TCN model achieved better performance than a state-of-the-art deep learning model but with lower computational cost. In the lab sessions, most jump counts showed small differences between the predicted jumps and video-annotated jumps, with an overall count showing a Limit of Agreement (LoA) of 0.1+-3.40 (r=0.884). For comparison, the proposed algorithm showed slightly worse results than VERT (a commercial jumping assessment device) with a LoA of 0.1+-2.08 (r=0.955) but the differences were still within a comparable range. In the training sessions, the recognition of three types of jumps exhibited a mean difference from observation of less than 10 jumps: block, smash, and overhead serve. These results showed the potential of using a single IMU to recognize the types of volleyball jumps. The sample-wise architecture provided high resolution of recognition and the MS-TCN required fewer parameters to train compared with state-of-the-art models.
Otago Exercises Monitoring for Older Adults by a Single IMU and Hierarchical Machine Learning Models
Oct 05, 2023Otago Exercise Program (OEP) is a rehabilitation program for older adults to improve frailty, sarcopenia, and balance. Accurate monitoring of patient involvement in OEP is challenging, as self-reports (diaries) are often unreliable. With the development of wearable sensors, Human Activity Recognition (HAR) systems using wearable sensors have revolutionized healthcare. However, their usage for OEP still shows limited performance. The objective of this study is to build an unobtrusive and accurate system to monitor OEP for older adults. Data was collected from older adults wearing a single waist-mounted Inertial Measurement Unit (IMU). Two datasets were collected, one in a laboratory setting, and one at the homes of the patients. A hierarchical system is proposed with two stages: 1) using a deep learning model to recognize whether the patients are performing OEP or activities of daily life (ADLs) using a 10-minute sliding window; 2) based on stage 1, using a 6-second sliding window to recognize the OEP sub-classes performed. The results showed that in stage 1, OEP could be recognized with window-wise f1-scores over 0.95 and Intersection-over-Union (IoU) f1-scores over 0.85 for both datasets. In stage 2, for the home scenario, four activities could be recognized with f1-scores over 0.8: ankle plantarflexors, abdominal muscles, knee bends, and sit-to-stand. The results showed the potential of monitoring the compliance of OEP using a single IMU in daily life. Also, some OEP sub-classes are possible to be recognized for further analysis.
Eat-Radar: Continuous Fine-Grained Eating Gesture Detection Using FMCW Radar and 3D Temporal Convolutional Network
Nov 08, 2022


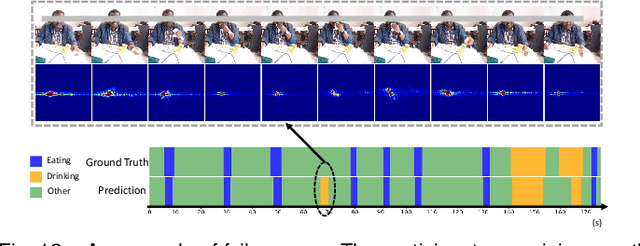
Unhealthy dietary habits are considered as the primary cause of multiple chronic diseases such as obesity and diabetes. The automatic food intake monitoring system has the potential to improve the quality of life (QoF) of people with dietary related diseases through dietary assessment. In this work, we propose a novel contact-less radar-based food intake monitoring approach. Specifically, a Frequency Modulated Continuous Wave (FMCW) radar sensor is employed to recognize fine-grained eating and drinking gestures. The fine-grained eating/drinking gesture contains a series of movement from raising the hand to the mouth until putting away the hand from the mouth. A 3D temporal convolutional network (3D-TCN) is developed to detect and segment eating and drinking gestures in meal sessions by processing the Range-Doppler Cube (RD Cube). Unlike previous radar-based research, this work collects data in continuous meal sessions. We create a public dataset that contains 48 meal sessions (3121 eating gestures and 608 drinking gestures) from 48 participants with a total duration of 783 minutes. Four eating styles (fork & knife, chopsticks, spoon, hand) are included in this dataset. To validate the performance of the proposed approach, 8-fold cross validation method is applied. Experimental results show that our proposed 3D-TCN outperforms the model that combines a convolutional neural network and a long-short-term-memory network (CNN-LSTM), and also the CNN-Bidirectional LSTM model (CNN-BiLSTM) in eating and drinking gesture detection. The 3D-TCN model achieves a segmental F1-score of 0.887 and 0.844 for eating and drinking gestures, respectively. The results of the proposed approach indicate the feasibility of using radar for fine-grained eating and drinking gesture detection and segmentation in meal sessions.
Skeleton-Based Action Segmentation with Multi-Stage Spatial-Temporal Graph Convolutional Neural Networks
Feb 03, 2022
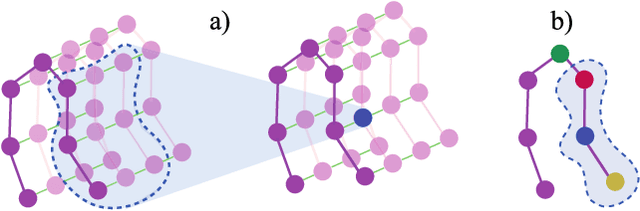

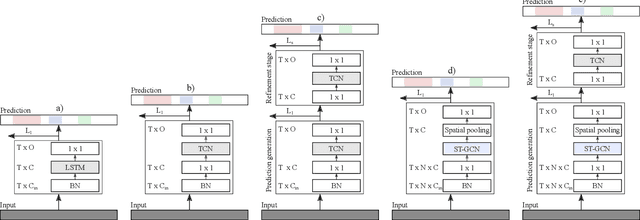
The ability to identify and temporally segment fine-grained actions in motion capture sequences is crucial for applications in human movement analysis. Motion capture is typically performed with optical or inertial measurement systems, which encode human movement as a time series of human joint locations and orientations or their higher-order representations. State-of-the-art action segmentation approaches use multiple stages of temporal convolutions. The main idea is to generate an initial prediction with several layers of temporal convolutions and refine these predictions over multiple stages, also with temporal convolutions. Although these approaches capture long-term temporal patterns, the initial predictions do not adequately consider the spatial hierarchy among the human joints. To address this limitation, we present multi-stage spatial-temporal graph convolutional neural networks (MS-GCN). Our framework decouples the architecture of the initial prediction generation stage from the refinement stages. Specifically, we replace the initial stage of temporal convolutions with spatial-temporal graph convolutions, which better exploit the spatial configuration of the joints and their temporal dynamics. Our framework was compared to four strong baselines on five tasks. Experimental results demonstrate that our framework achieves state-of-the-art performance.