 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRhombot: Rhombus-shaped Modular Robots for Stable, Medium-Independent Reconfiguration Motion
Jan 27, 2026In this paper, we present Rhombot, a novel deformable planar lattice modular self-reconfigurable robot (MSRR) with a rhombus shaped module. Each module consists of a parallelogram skeleton with a single centrally mounted actuator that enables folding and unfolding along its diagonal. The core design philosophy is to achieve essential MSRR functionalities such as morphing, docking, and locomotion with minimal control complexity. This enables a continuous and stable reconfiguration process that is independent of the surrounding medium, allowing the system to reliably form various configurations in diverse environments. To leverage the unique kinematics of Rhombot, we introduce morphpivoting, a novel motion primitive for reconfiguration that differs from advanced MSRR systems, and propose a strategy for its continuous execution. Finally, a series of physical experiments validate the module's stable reconfiguration ability, as well as its positional and docking accuracy.
Relative Localization System Design for SnailBot: A Modular Self-reconfigurable Robot
Dec 24, 2025This paper presents the design and implementation of a relative localization system for SnailBot, a modular self reconfigurable robot. The system integrates ArUco marker recognition, optical flow analysis, and IMU data processing into a unified fusion framework, enabling robust and accurate relative positioning for collaborative robotic tasks. Experimental validation demonstrates the effectiveness of the system in realtime operation, with a rule based fusion strategy ensuring reliability across dynamic scenarios. The results highlight the potential for scalable deployment in modular robotic systems.
Real-Time Polygonal Semantic Mapping for Humanoid Robot Stair Climbing
Nov 04, 2024We present a novel algorithm for real-time planar semantic mapping tailored for humanoid robots navigating complex terrains such as staircases. Our method is adaptable to any odometry input and leverages GPU-accelerated processes for planar extraction, enabling the rapid generation of globally consistent semantic maps. We utilize an anisotropic diffusion filter on depth images to effectively minimize noise from gradient jumps while preserving essential edge details, enhancing normal vector images' accuracy and smoothness. Both the anisotropic diffusion and the RANSAC-based plane extraction processes are optimized for parallel processing on GPUs, significantly enhancing computational efficiency. Our approach achieves real-time performance, processing single frames at rates exceeding $30~Hz$, which facilitates detailed plane extraction and map management swiftly and efficiently. Extensive testing underscores the algorithm's capabilities in real-time scenarios and demonstrates its practical application in humanoid robot gait planning, significantly improving its ability to navigate dynamic environments.
Vision-Language Model-based Physical Reasoning for Robot Liquid Perception
Apr 10, 2024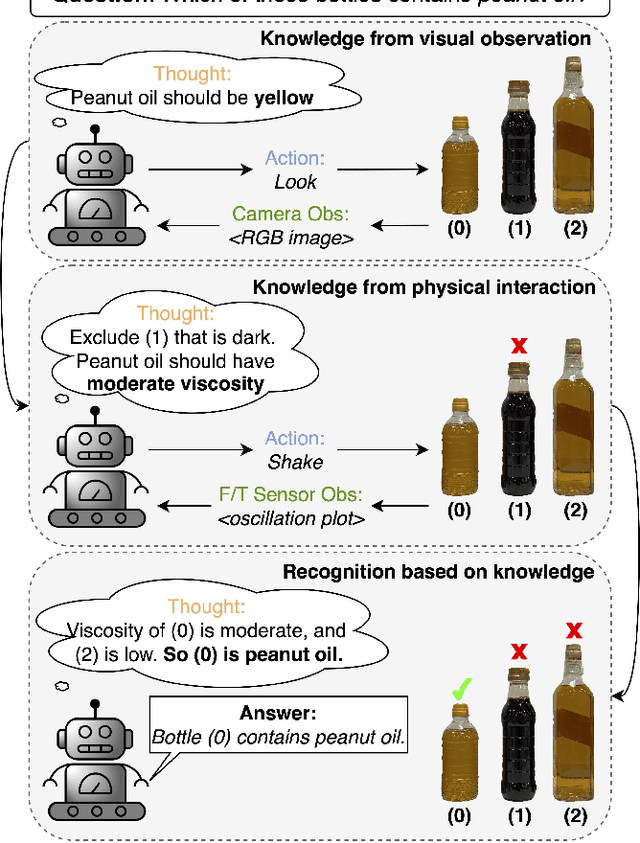
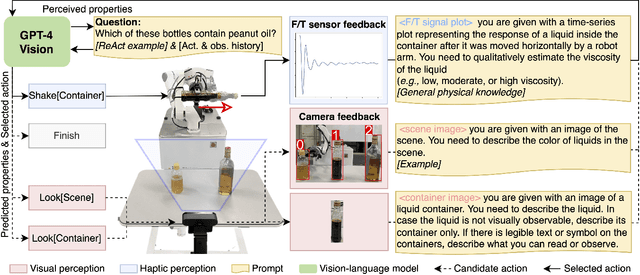

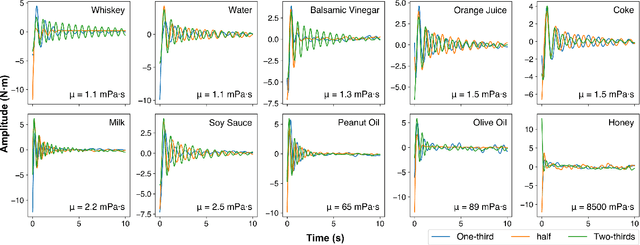
There is a growing interest in applying large language models (LLMs) in robotic tasks, due to their remarkable reasoning ability and extensive knowledge learned from vast training corpora. Grounding LLMs in the physical world remains an open challenge as they can only process textual input. Recent advancements in large vision-language models (LVLMs) have enabled a more comprehensive understanding of the physical world by incorporating visual input, which provides richer contextual information than language alone. In this work, we proposed a novel paradigm that leveraged GPT-4V(ision), the state-of-the-art LVLM by OpenAI, to enable embodied agents to perceive liquid objects via image-based environmental feedback. Specifically, we exploited the physical understanding of GPT-4V to interpret the visual representation (e.g., time-series plot) of non-visual feedback (e.g., F/T sensor data), indirectly enabling multimodal perception beyond vision and language using images as proxies. We evaluated our method using 10 common household liquids with containers of various geometry and material. Without any training or fine-tuning, we demonstrated that our method can enable the robot to indirectly perceive the physical response of liquids and estimate their viscosity. We also showed that by jointly reasoning over the visual and physical attributes learned through interactions, our method could recognize liquid objects in the absence of strong visual cues (e.g., container labels with legible text or symbols), increasing the accuracy from 69.0% -- achieved by the best-performing vision-only variant -- to 86.0%.
Decoding Modular Reconfigurable Robots: A Survey on Mechanisms and Design
Oct 15, 2023



The intrinsic modularity and reconfigurability of modular reconfigurable robots (MRR) confer advantages such as versatility, fault tolerance, and economic efficacy, thereby showcasing considerable potential across diverse applications. The continuous evolution of the technology landscape and the emergence of diverse conceptual designs have generated multiple MRR categories, each described by its respective morphology or capability characteristics, leading to some ambiguity in the taxonomy. This paper conducts a comprehensive survey encompassing the entirety of MRR hardware and design, spanning from the inception in 1985 to 2023. This paper introduces an innovative, unified conceptual framework for understanding MRR hardware, which encompasses three pivotal elements: connectors, actuators, and homogeneity. Through the utilization of this trilateral framework, this paper provide an intuitive understanding of the diverse spectrum of MRR hardware iterations while systematically deciphering and classifying the entire range, offering a more structured perspective. This survey elucidates the fundamental attributes characterizing MRRs and their compositional aspects, providinig insights into their design, technology, functionality, and categorization. Augmented by the proposed trilateral framework, this paper also elaborates on the trajectory of evolution, prevailing trends, principal challenges, and potential prospects within the field of MRRs.
Explicit Attention-Enhanced Fusion for RGB-Thermal Perception Tasks
Mar 28, 2023
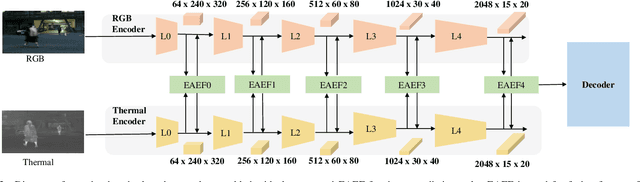
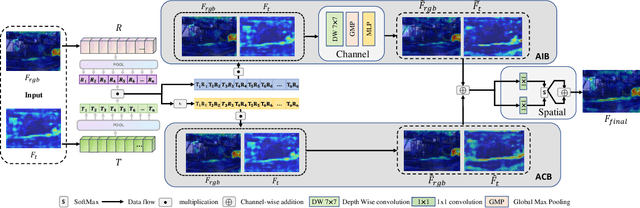

Recently, RGB-Thermal based perception has shown significant advances. Thermal information provides useful clues when visual cameras suffer from poor lighting conditions, such as low light and fog. However, how to effectively fuse RGB images and thermal data remains an open challenge. Previous works involve naive fusion strategies such as merging them at the input, concatenating multi-modality features inside models, or applying attention to each data modality. These fusion strategies are straightforward yet insufficient. In this paper, we propose a novel fusion method named Explicit Attention-Enhanced Fusion (EAEF) that fully takes advantage of each type of data. Specifically, we consider the following cases: i) both RGB data and thermal data, ii) only one of the types of data, and iii) none of them generate discriminative features. EAEF uses one branch to enhance feature extraction for i) and iii) and the other branch to remedy insufficient representations for ii). The outputs of two branches are fused to form complementary features. As a result, the proposed fusion method outperforms state-of-the-art by 1.6\% in mIoU on semantic segmentation, 3.1\% in MAE on salient object detection, 2.3\% in mAP on object detection, and 8.1\% in MAE on crowd counting. The code is available at https://github.com/FreeformRobotics/EAEFNet.
RGB-D-Inertial SLAM in Indoor Dynamic Environments with Long-term Large Occlusion
Mar 23, 2023This work presents a novel RGB-D-inertial dynamic SLAM method that can enable accurate localisation when the majority of the camera view is occluded by multiple dynamic objects over a long period of time. Most dynamic SLAM approaches either remove dynamic objects as outliers when they account for a minor proportion of the visual input, or detect dynamic objects using semantic segmentation before camera tracking. Therefore, dynamic objects that cause large occlusions are difficult to detect without prior information. The remaining visual information from the static background is also not enough to support localisation when large occlusion lasts for a long period. To overcome these problems, our framework presents a robust visual-inertial bundle adjustment that simultaneously tracks camera, estimates cluster-wise dense segmentation of dynamic objects and maintains a static sparse map by combining dense and sparse features. The experiment results demonstrate that our method achieves promising localisation and object segmentation performance compared to other state-of-the-art methods in the scenario of long-term large occlusion.
Lifelong-MonoDepth: Lifelong Learning for Multi-Domain Monocular Metric Depth Estimation
Mar 09, 2023



In recent years, monocular depth estimation (MDE) has gained significant progress in a data-driven learning fashion. Previous methods can infer depth maps for specific domains based on the paradigm of single-domain or joint-domain training with mixed data. However, they suffer from low scalability to new domains. In reality, target domains often dynamically change or increase, raising the requirement of incremental multi-domain/task learning. In this paper, we seek to enable lifelong learning for MDE, which performs cross-domain depth learning sequentially, to achieve high plasticity on a new domain and maintain good stability on original domains. To overcome significant domain gaps and enable scale-aware depth prediction, we design a lightweight multi-head framework that consists of a domain-shared encoder for feature extraction and domain-specific predictors for metric depth estimation. Moreover, given an input image, we propose an efficient predictor selection approach that automatically identifies the corresponding predictor for depth inference. Through extensive numerical studies, we show that the proposed method can achieve good efficiency, stability, and plasticity, leading the benchmarks by 8% to 15%.
Attentional Graph Convolutional Network for Structure-aware Audio-Visual Scene Classification
Dec 31, 2022
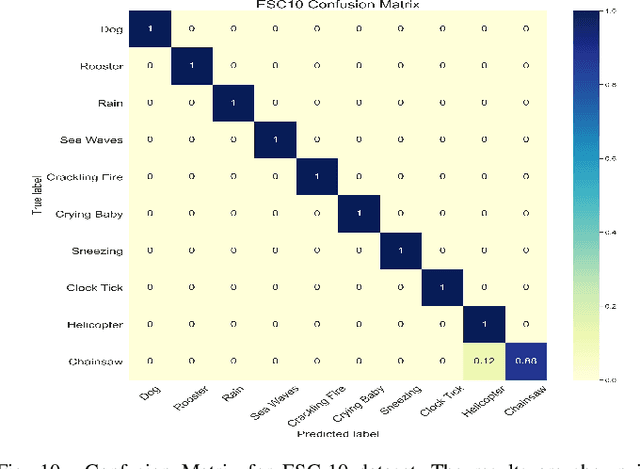
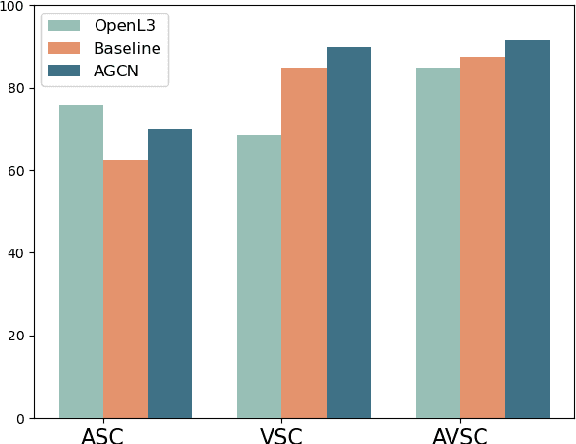
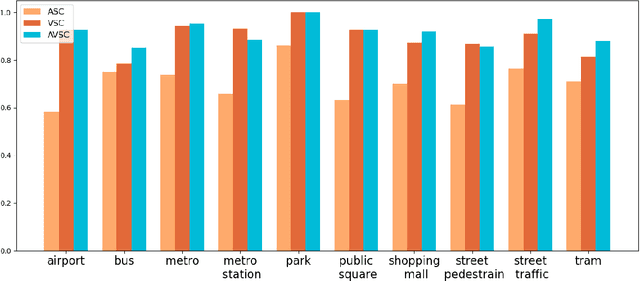
Audio-Visual scene understanding is a challenging problem due to the unstructured spatial-temporal relations that exist in the audio signals and spatial layouts of different objects and various texture patterns in the visual images. Recently, many studies have focused on abstracting features from convolutional neural networks while the learning of explicit semantically relevant frames of sound signals and visual images has been overlooked. To this end, we present an end-to-end framework, namely attentional graph convolutional network (AGCN), for structure-aware audio-visual scene representation. First, the spectrogram of sound and input image is processed by a backbone network for feature extraction. Then, to build multi-scale hierarchical information of input features, we utilize an attention fusion mechanism to aggregate features from multiple layers of the backbone network. Notably, to well represent the salient regions and contextual information of audio-visual inputs, the salient acoustic graph (SAG) and contextual acoustic graph (CAG), salient visual graph (SVG), and contextual visual graph (CVG) are constructed for the audio-visual scene representation. Finally, the constructed graphs pass through a graph convolutional network for structure-aware audio-visual scene recognition. Extensive experimental results on the audio, visual and audio-visual scene recognition datasets show that promising results have been achieved by the AGCN methods. Visualizing graphs on the spectrograms and images have been presented to show the effectiveness of proposed CAG/SAG and CVG/SVG that could focus on the salient and semantic relevant regions.
Peer Learning for Unbiased Scene Graph Generation
Dec 31, 2022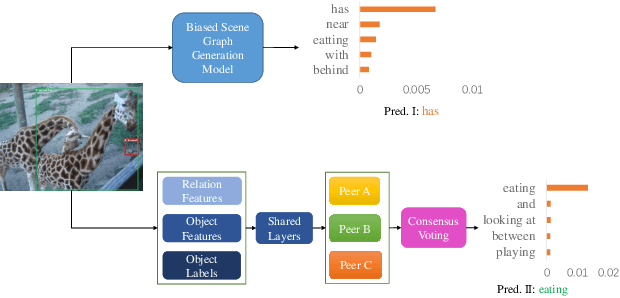
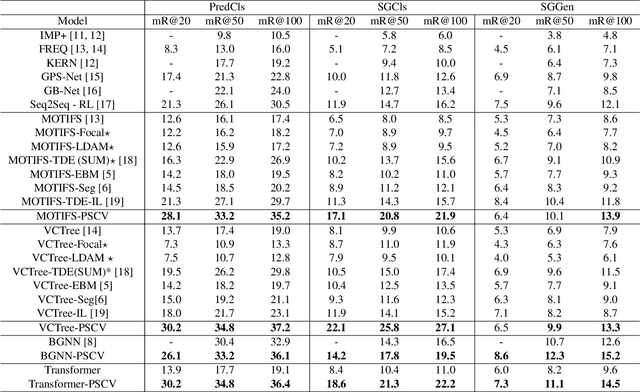
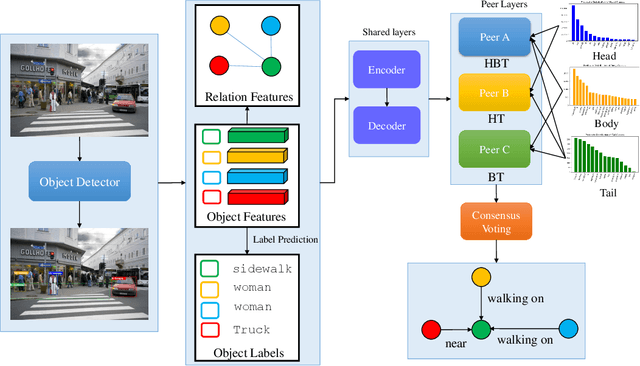
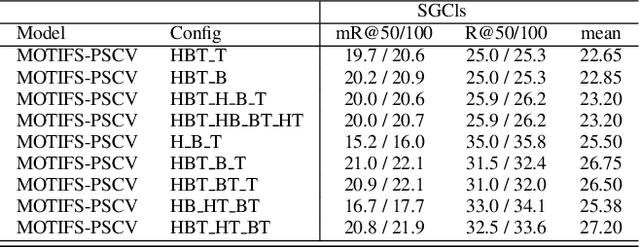
In this paper, we propose a novel framework dubbed peer learning to deal with the problem of biased scene graph generation (SGG). This framework uses predicate sampling and consensus voting (PSCV) to encourage different peers to learn from each other, improving model diversity and mitigating bias in SGG. To address the heavily long-tailed distribution of predicate classes, we propose to use predicate sampling to divide and conquer this issue. As a result, the model is less biased and makes more balanced predicate predictions. Specifically, one peer may not be sufficiently diverse to discriminate between different levels of predicate distributions. Therefore, we sample the data distribution based on frequency of predicates into sub-distributions, selecting head, body, and tail classes to combine and feed to different peers as complementary predicate knowledge during the training process. The complementary predicate knowledge of these peers is then ensembled utilizing a consensus voting strategy, which simulates a civilized voting process in our society that emphasizes the majority opinion and diminishes the minority opinion. This approach ensures that the learned representations of each peer are optimally adapted to the various data distributions. Extensive experiments on the Visual Genome dataset demonstrate that PSCV outperforms previous methods. We have established a new state-of-the-art (SOTA) on the SGCls task by achieving a mean of \textbf{31.6}.