 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Attention-Enhanced Fusion for RGB-Thermal Perception Tasks
Mar 28, 2023
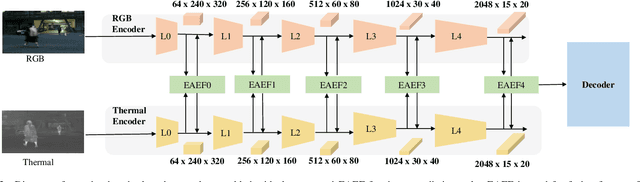
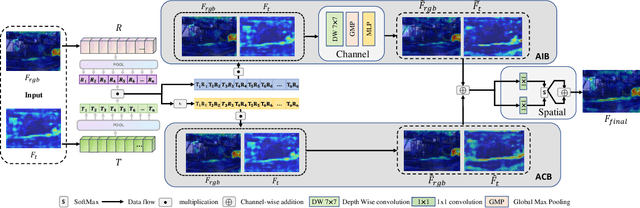

Recently, RGB-Thermal based perception has shown significant advances. Thermal information provides useful clues when visual cameras suffer from poor lighting conditions, such as low light and fog. However, how to effectively fuse RGB images and thermal data remains an open challenge. Previous works involve naive fusion strategies such as merging them at the input, concatenating multi-modality features inside models, or applying attention to each data modality. These fusion strategies are straightforward yet insufficient. In this paper, we propose a novel fusion method named Explicit Attention-Enhanced Fusion (EAEF) that fully takes advantage of each type of data. Specifically, we consider the following cases: i) both RGB data and thermal data, ii) only one of the types of data, and iii) none of them generate discriminative features. EAEF uses one branch to enhance feature extraction for i) and iii) and the other branch to remedy insufficient representations for ii). The outputs of two branches are fused to form complementary features. As a result, the proposed fusion method outperforms state-of-the-art by 1.6\% in mIoU on semantic segmentation, 3.1\% in MAE on salient object detection, 2.3\% in mAP on object detection, and 8.1\% in MAE on crowd counting. The code is available at https://github.com/FreeformRobotics/EAEFNet.
MultiRoboLearn: An open-source Framework for Multi-robot Deep Reinforcement Learning
Sep 28, 2022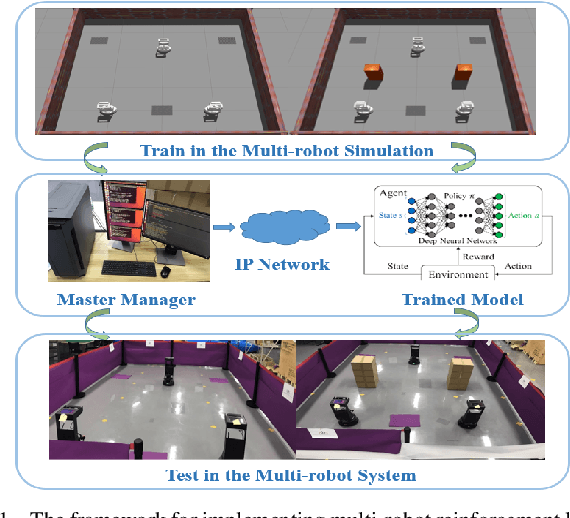
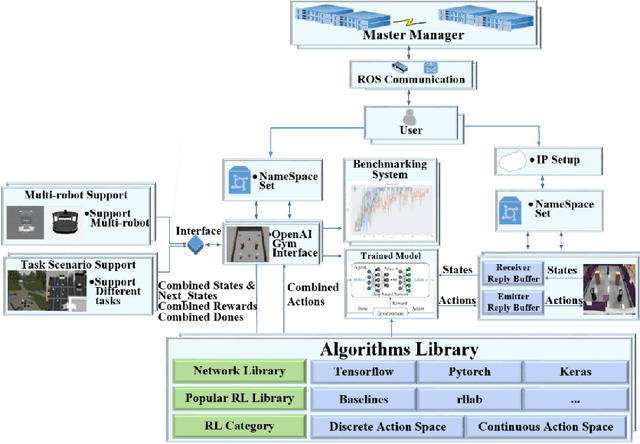
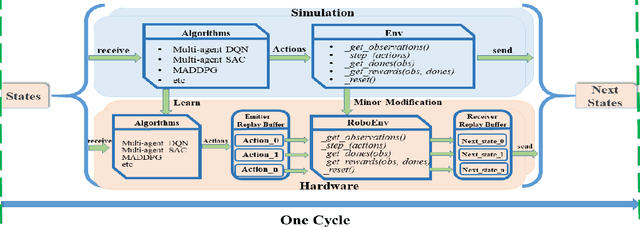
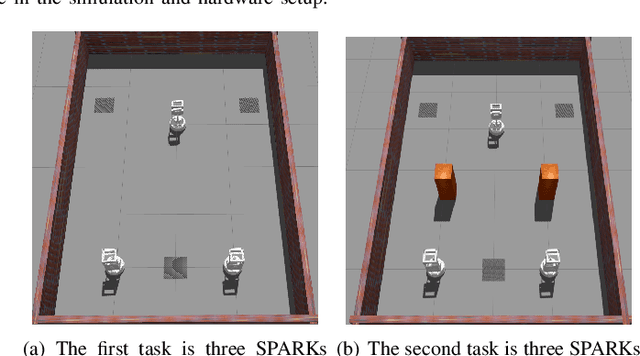
It is well known that it is difficult to have a reliable and robust framework to link multi-agent deep reinforcement learning algorithms with practical multi-robot applications. To fill this gap, we propose and build an open-source framework for multi-robot systems called MultiRoboLearn1. This framework builds a unified setup of simulation and real-world applications. It aims to provide standard, easy-to-use simulated scenarios that can also be easily deployed to real-world multi-robot environments. Also, the framework provides researchers with a benchmark system for comparing the performance of different reinforcement learning algorithms. We demonstrate the generality, scalability, and capability of the framework with two real-world scenarios2 using different types of multi-agent deep reinforcement learning algorithms in discrete and continuous action spaces.
Abnormal Occupancy Grid Map Recognition using Attention Network
Oct 18, 2021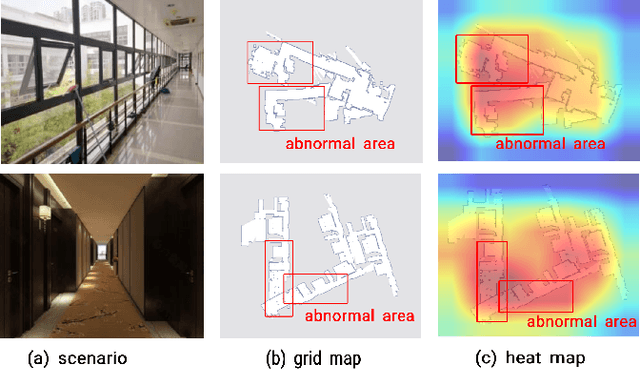
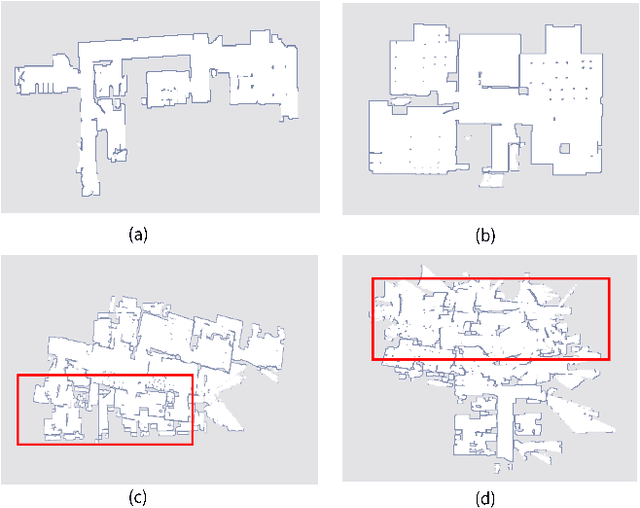
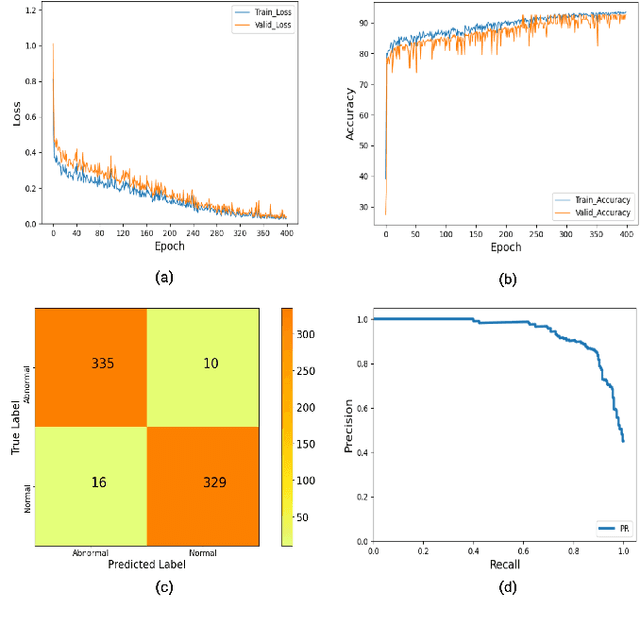
The occupancy grid map is a critical component of autonomous positioning and navigation in the mobile robotic system, as many other systems' performance depends heavily on it. To guarantee the quality of the occupancy grid maps, researchers previously had to perform tedious manual recognition for a long time. This work focuses on automatic abnormal occupancy grid map recognition using the residual neural networks and a novel attention mechanism module. We propose an effective channel and spatial Residual SE(csRSE) attention module, which contains a residual block for producing hierarchical features, followed by both channel SE (cSE) block and spatial SE (sSE) block for the sufficient information extraction along the channel and spatial pathways. To further summarize the occupancy grid map characteristics and experiment with our csRSE attention modules, we constructed a dataset called occupancy grid map dataset (OGMD) for our experiments. On this OGMD test dataset, we tested few variants of our proposed structure and compared them with other attention mechanisms. Our experimental results show that the proposed attention network can infer the abnormal map with state-of-the-art (SOTA) accuracy of 96.23% for abnormal occupancy grid map recognition.
FEANet: Feature-Enhanced Attention Network for RGB-Thermal Real-time Semantic Segmentation
Oct 18, 2021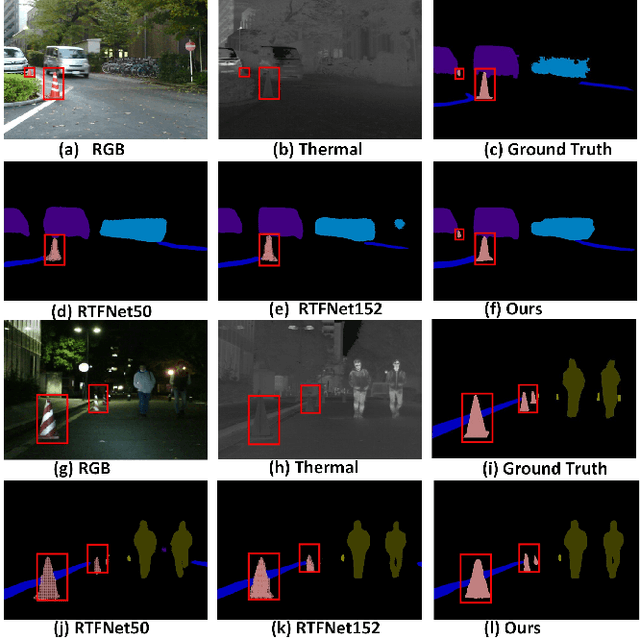
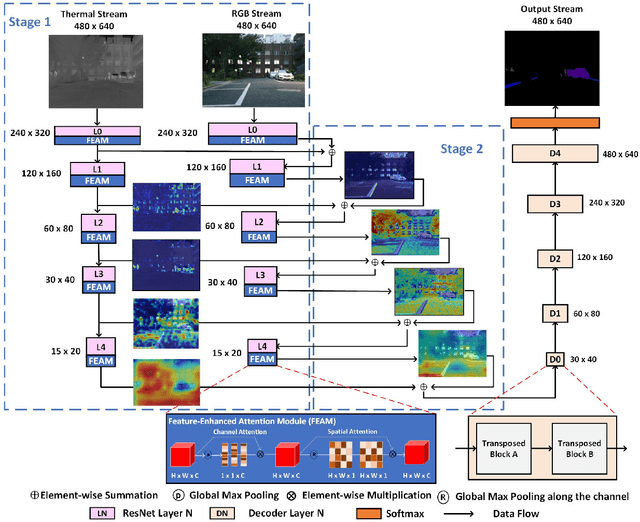
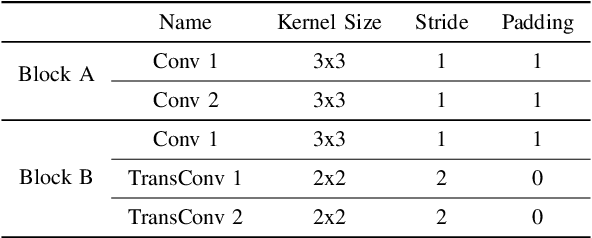
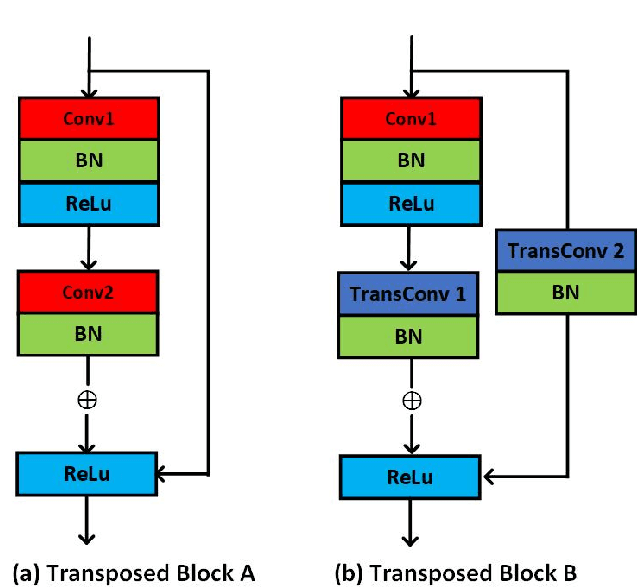
The RGB-Thermal (RGB-T) information for semantic segmentation has been extensively explored in recent years. However, most existing RGB-T semantic segmentation usually compromises spatial resolution to achieve real-time inference speed, which leads to poor performance. To better extract detail spatial information, we propose a two-stage Feature-Enhanced Attention Network (FEANet) for the RGB-T semantic segmentation task. Specifically, we introduce a Feature-Enhanced Attention Module (FEAM) to excavate and enhance multi-level features from both the channel and spatial views. Benefited from the proposed FEAM module, our FEANet can preserve the spatial information and shift more attention to high-resolution features from the fused RGB-T images. Extensive experiments on the urban scene dataset demonstrate that our FEANet outperforms other state-of-the-art (SOTA) RGB-T methods in terms of objective metrics and subjective visual comparison (+2.6% in global mAcc and +0.8% in global mIoU). For the 480 x 640 RGB-T test images, our FEANet can run with a real-time speed on an NVIDIA GeForce RTX 2080 Ti card.
AB-Mapper: Attention and BicNet Based Multi-agent Path Finding for Dynamic Crowded Environment
Oct 02, 2021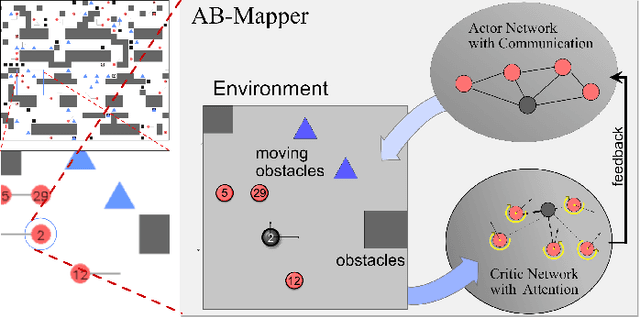
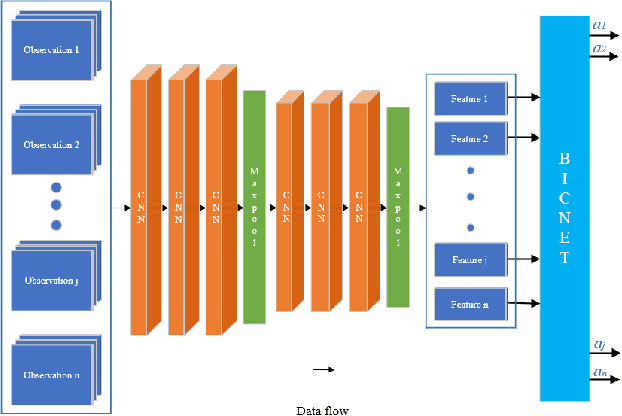
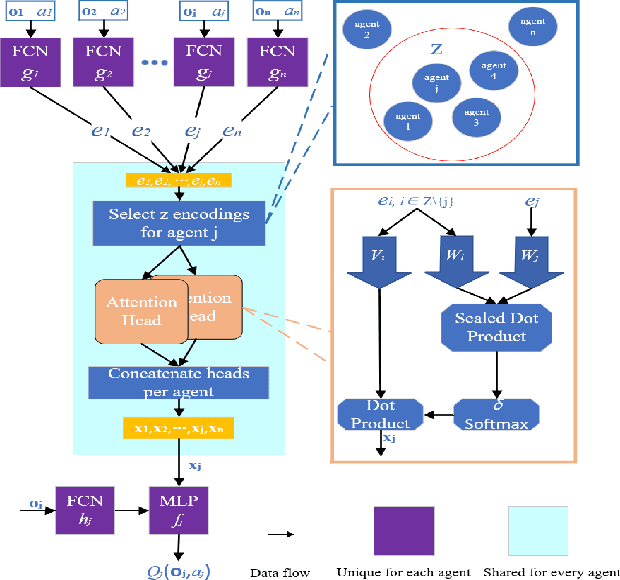
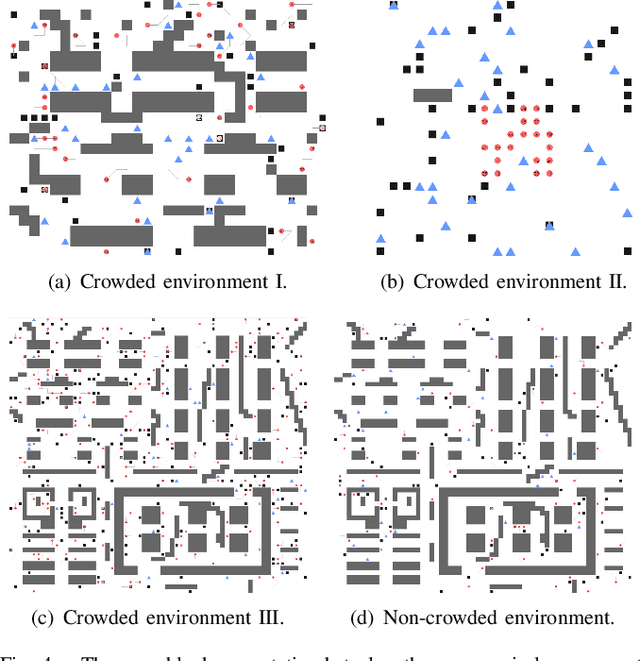
Multi-agent path finding in dynamic crowded environments is of great academic and practical value for multi-robot systems in the real world. To improve the effectiveness and efficiency of communication and learning process during path planning in dynamic crowded environments, we introduce an algorithm called Attention and BicNet based Multi-agent path planning with effective reinforcement (AB-Mapper)under the actor-critic reinforcement learning framework. In this framework, on the one hand, we utilize the BicNet with communication function in the actor-network to achieve intra team coordination. On the other hand, we propose a centralized critic network that can selectively allocate attention weights to surrounding agents. This attention mechanism allows an individual agent to automatically learn a better evaluation of actions by also considering the behaviours of its surrounding agents. Compared with the state-of-the-art method Mapper,our AB-Mapper is more effective (85.86% vs. 81.56% in terms of success rate) in solving the general path finding problems with dynamic obstacles. In addition, in crowded scenarios, our method outperforms the Mapper method by a large margin,reaching a stunning gap of more than 40% for each experiment.
Meta Reinforcement Learning Based Sensor Scanning in 3D Uncertain Environments for Heterogeneous Multi-Robot Systems
Sep 28, 2021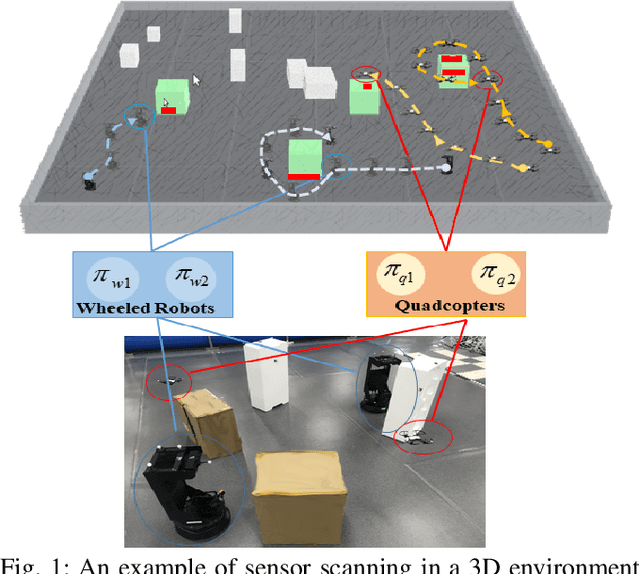
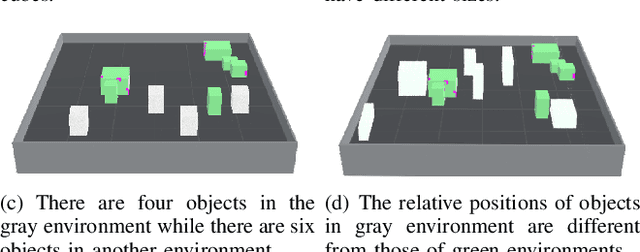
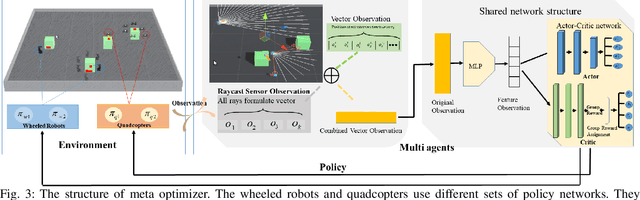
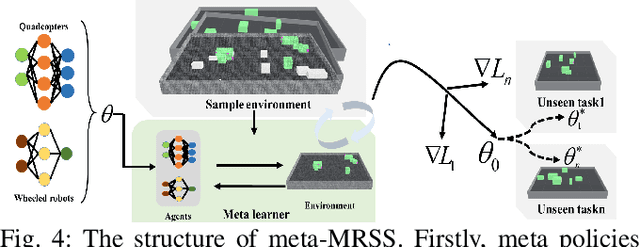
We study a novel problem that tackles learning based sensor scanning in 3D and uncertain environments with heterogeneous multi-robot systems. Our motivation is two-fold: first, 3D environments are complex, the use of heterogeneous multi-robot systems intuitively can facilitate sensor scanning by fully taking advantage of sensors with different capabilities. Second, in uncertain environments (e.g. rescue), time is of great significance. Since the learning process normally takes time to train and adapt to a new environment, we need to find an effective way to explore and adapt quickly. To this end, in this paper, we present a meta-learning approach to improve the exploration and adaptation capabilities. The experimental results demonstrate our method can outperform other methods by approximately 15%-27% on success rate and 70%-75% on adaptation speed.
A Two-stage Unsupervised Approach for Low light Image Enhancement
Oct 20, 2020



As vision based perception methods are usually built on the normal light assumption, there will be a serious safety issue when deploying them into low light environments. Recently, deep learning based methods have been proposed to enhance low light images by penalizing the pixel-wise loss of low light and normal light images. However, most of them suffer from the following problems: 1) the need of pairs of low light and normal light images for training, 2) the poor performance for dark images, 3) the amplification of noise. To alleviate these problems, in this paper, we propose a two-stage unsupervised method that decomposes the low light image enhancement into a pre-enhancement and a post-refinement problem. In the first stage, we pre-enhance a low light image with a conventional Retinex based method. In the second stage, we use a refinement network learned with adversarial training for further improvement of the image quality. The experimental results show that our method outperforms previous methods on four benchmark datasets. In addition, we show that our method can significantly improve feature points matching and simultaneous localization and mapping in low light conditions.
Semantic Histogram Based Graph Matching for Real-Time Multi-Robot Global Localization in Large Scale Environment
Oct 19, 2020
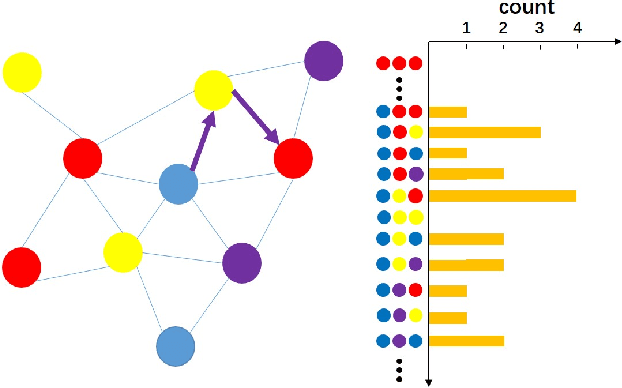
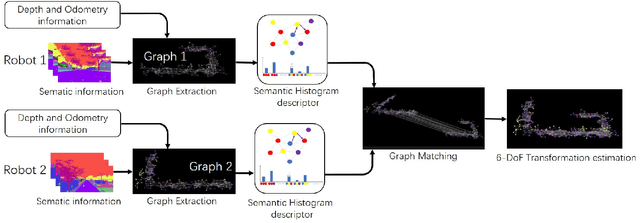

The core problem of visual multi-robot simultaneous localization and mapping (MR-SLAM) is how to efficiently and accurately perform multi-robot global localization (MR-GL). The difficulties are two-fold. The first is the difficulty of global localization for significant viewpoint difference. Appearance-based localization methods tend to fail under large viewpoint changes. Recently, semantic graphs have been utilized to overcome the viewpoint variation problem. However, the methods are highly time-consuming, especially in large-scale environments. This leads to the second difficulty, which is how to perform real-time global localization. In this paper, we propose a semantic histogram-based graph matching method that is robust to viewpoint variation and can achieve real-time global localization. Based on that, we develop a system that can accurately and efficiently perform MR-GL for both homogeneous and heterogeneous robots. The experimental results show that our approach is about 30 times faster than Random Walk based semantic descriptors. Moreover, it achieves an accuracy of 95% for global localization, while the accuracy of the state-of-the-art method is 85%.