 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Modular Reconfigurable Robots: A Survey on Mechanisms and Design
Oct 15, 2023



The intrinsic modularity and reconfigurability of modular reconfigurable robots (MRR) confer advantages such as versatility, fault tolerance, and economic efficacy, thereby showcasing considerable potential across diverse applications. The continuous evolution of the technology landscape and the emergence of diverse conceptual designs have generated multiple MRR categories, each described by its respective morphology or capability characteristics, leading to some ambiguity in the taxonomy. This paper conducts a comprehensive survey encompassing the entirety of MRR hardware and design, spanning from the inception in 1985 to 2023. This paper introduces an innovative, unified conceptual framework for understanding MRR hardware, which encompasses three pivotal elements: connectors, actuators, and homogeneity. Through the utilization of this trilateral framework, this paper provide an intuitive understanding of the diverse spectrum of MRR hardware iterations while systematically deciphering and classifying the entire range, offering a more structured perspective. This survey elucidates the fundamental attributes characterizing MRRs and their compositional aspects, providinig insights into their design, technology, functionality, and categorization. Augmented by the proposed trilateral framework, this paper also elaborates on the trajectory of evolution, prevailing trends, principal challenges, and potential prospects within the field of MRRs.
MultiRoboLearn: An open-source Framework for Multi-robot Deep Reinforcement Learning
Sep 28, 2022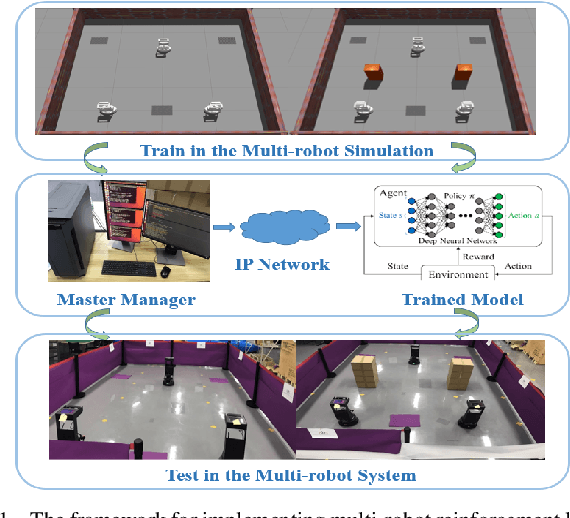
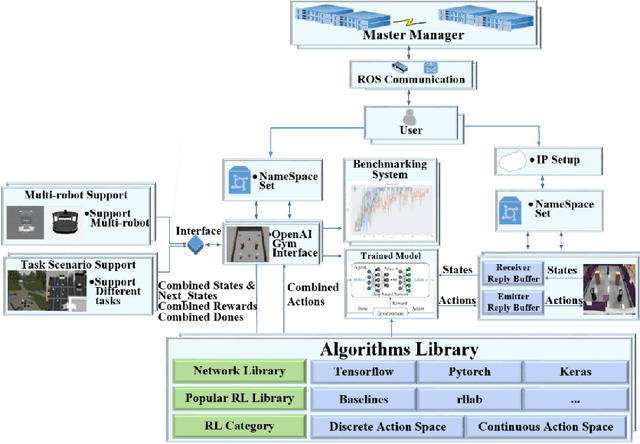
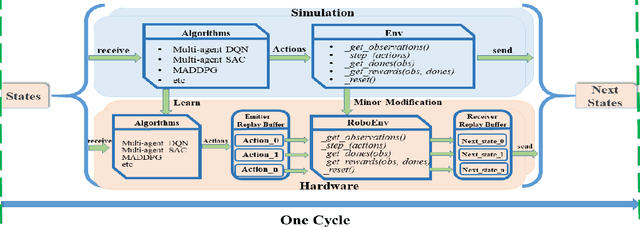
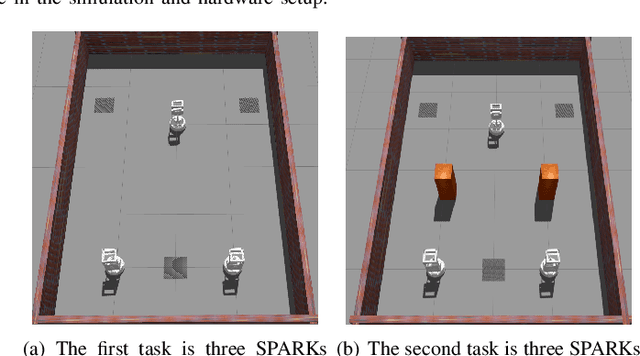
It is well known that it is difficult to have a reliable and robust framework to link multi-agent deep reinforcement learning algorithms with practical multi-robot applications. To fill this gap, we propose and build an open-source framework for multi-robot systems called MultiRoboLearn1. This framework builds a unified setup of simulation and real-world applications. It aims to provide standard, easy-to-use simulated scenarios that can also be easily deployed to real-world multi-robot environments. Also, the framework provides researchers with a benchmark system for comparing the performance of different reinforcement learning algorithms. We demonstrate the generality, scalability, and capability of the framework with two real-world scenarios2 using different types of multi-agent deep reinforcement learning algorithms in discrete and continuous action spaces.
A Two-stage Unsupervised Approach for Low light Image Enhancement
Oct 20, 2020



As vision based perception methods are usually built on the normal light assumption, there will be a serious safety issue when deploying them into low light environments. Recently, deep learning based methods have been proposed to enhance low light images by penalizing the pixel-wise loss of low light and normal light images. However, most of them suffer from the following problems: 1) the need of pairs of low light and normal light images for training, 2) the poor performance for dark images, 3) the amplification of noise. To alleviate these problems, in this paper, we propose a two-stage unsupervised method that decomposes the low light image enhancement into a pre-enhancement and a post-refinement problem. In the first stage, we pre-enhance a low light image with a conventional Retinex based method. In the second stage, we use a refinement network learned with adversarial training for further improvement of the image quality. The experimental results show that our method outperforms previous methods on four benchmark datasets. In addition, we show that our method can significantly improve feature points matching and simultaneous localization and mapping in low light conditions.