 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe conditional-mean barrier: From deterministic regression to conditional distribution learning
May 27, 2026Many problems in computational science and engineering become one-to-many after coarse graining, partial observation, or inverse reconstruction: a resolved state may not determine a unique subgrid forcing, a structural descriptor may not determine a unique effective response, and a low-resolution observation may correspond to many plausible high-resolution fields. In such settings, deterministic surrogates may learn a well-defined mathematical object while still missing application-relevant uncertainty. This tutorial develops a self-contained module centered on the conditional-mean barrier: the point at which a squared-loss predictor has reached the conditional mean and the remaining error is irreducible aleatoric variance. We give two diagnostics for locating this barrier, residual-feature orthogonality and the coefficient of determination against its explained-variance ceiling, and prove that adding latent randomness to a squared-loss predictor collapses it back to the conditional mean. Crossing the barrier therefore requires a loss that scores distributions rather than point predictions. We briefly organize common distributional objectives, including negative log-likelihood, moment and observable matching, variational objectives, adversarial divergences, and score matching, by the feature of the conditional law each targets. The emphasis is the boundary itself and a finite-data procedure for recognizing it, rather than a survey of methods beyond it. CPU-based demonstrations on a two-branch law and a two-scale Lorenz-96 closure problem show how the diagnostics distinguish deterministic underfitting from residual distributional variability.
CoCoPlan: Adaptive Coordination and Communication for Multi-robot Systems in Dynamic and Unknown Environments
Jan 15, 2026Multi-robot systems can greatly enhance efficiency through coordination and collaboration, yet in practice, full-time communication is rarely available and interactions are constrained to close-range exchanges. Existing methods either maintain all-time connectivity, rely on fixed schedules, or adopt pairwise protocols, but none adapt effectively to dynamic spatio-temporal task distributions under limited communication, resulting in suboptimal coordination. To address this gap, we propose CoCoPlan, a unified framework that co-optimizes collaborative task planning and team-wise intermittent communication. Our approach integrates a branch-and-bound architecture that jointly encodes task assignments and communication events, an adaptive objective function that balances task efficiency against communication latency, and a communication event optimization module that strategically determines when, where and how the global connectivity should be re-established. Extensive experiments demonstrate that it outperforms state-of-the-art methods by achieving a 22.4% higher task completion rate, reducing communication overhead by 58.6%, and improving the scalability by supporting up to 100 robots in dynamic environments. Hardware experiments include the complex 2D office environment and large-scale 3D disaster-response scenario.
SLEI3D: Simultaneous Exploration and Inspection via Heterogeneous Fleets under Limited Communication
Jan 01, 2026Robotic fleets such as unmanned aerial and ground vehicles have been widely used for routine inspections of static environments, where the areas of interest are known and planned in advance. However, in many applications, such areas of interest are unknown and should be identified online during exploration. Thus, this paper considers the problem of simultaneous exploration, inspection of unknown environments and then real-time communication to a mobile ground control station to report the findings. The heterogeneous robots are equipped with different sensors, e.g., long-range lidars for fast exploration and close-range cameras for detailed inspection. Furthermore, global communication is often unavailable in such environments, where the robots can only communicate with each other via ad-hoc wireless networks when they are in close proximity and free of obstruction. This work proposes a novel planning and coordination framework (SLEI3D) that integrates the online strategies for collaborative 3D exploration, adaptive inspection and timely communication (via the intermit-tent or proactive protocols). To account for uncertainties w.r.t. the number and location of features, a multi-layer and multi-rate planning mechanism is developed for inter-and-intra robot subgroups, to actively meet and coordinate their local plans. The proposed framework is validated extensively via high-fidelity simulations of numerous large-scale missions with up to 48 robots and 384 thousand cubic meters. Hardware experiments of 7 robots are also conducted. Project website is available at https://junfengchen-robotics.github.io/SLEI3D/.
DEXTER-LLM: Dynamic and Explainable Coordination of Multi-Robot Systems in Unknown Environments via Large Language Models
Aug 20, 2025



Online coordination of multi-robot systems in open and unknown environments faces significant challenges, particularly when semantic features detected during operation dynamically trigger new tasks. Recent large language model (LLMs)-based approaches for scene reasoning and planning primarily focus on one-shot, end-to-end solutions in known environments, lacking both dynamic adaptation capabilities for online operation and explainability in the processes of planning. To address these issues, a novel framework (DEXTER-LLM) for dynamic task planning in unknown environments, integrates four modules: (i) a mission comprehension module that resolves partial ordering of tasks specified by natural languages or linear temporal logic formulas (LTL); (ii) an online subtask generator based on LLMs that improves the accuracy and explainability of task decomposition via multi-stage reasoning; (iii) an optimal subtask assigner and scheduler that allocates subtasks to robots via search-based optimization; and (iv) a dynamic adaptation and human-in-the-loop verification module that implements multi-rate, event-based updates for both subtasks and their assignments, to cope with new features and tasks detected online. The framework effectively combines LLMs' open-world reasoning capabilities with the optimality of model-based assignment methods, simultaneously addressing the critical issue of online adaptability and explainability. Experimental evaluations demonstrate exceptional performances, with 100% success rates across all scenarios, 160 tasks and 480 subtasks completed on average (3 times the baselines), 62% less queries to LLMs during adaptation, and superior plan quality (2 times higher) for compound tasks. Project page at https://tcxm.github.io/DEXTER-LLM/
DUE: A Deep Learning Framework and Library for Modeling Unknown Equations
Apr 14, 2025



Equations, particularly differential equations, are fundamental for understanding natural phenomena and predicting complex dynamics across various scientific and engineering disciplines. However, the governing equations for many complex systems remain unknown due to intricate underlying mechanisms. Recent advancements in machine learning and data science offer a new paradigm for modeling unknown equations from measurement or simulation data. This paradigm shift, known as data-driven discovery or modeling, stands at the forefront of AI for science, with significant progress made in recent years. In this paper, we introduce a systematic framework for data-driven modeling of unknown equations using deep learning. This versatile framework is capable of learning unknown ODEs, PDEs, DAEs, IDEs, SDEs, reduced or partially observed systems, and non-autonomous differential equations. Based on this framework, we have developed Deep Unknown Equations (DUE), an open-source software package designed to facilitate the data-driven modeling of unknown equations using modern deep learning techniques. DUE serves as an educational tool for classroom instruction, enabling students and newcomers to gain hands-on experience with differential equations, data-driven modeling, and contemporary deep learning approaches such as FNN, ResNet, generalized ResNet, operator semigroup networks (OSG-Net), and Transformers. Additionally, DUE is a versatile and accessible toolkit for researchers across various scientific and engineering fields. It is applicable not only for learning unknown equations from data but also for surrogate modeling of known, yet complex, equations that are costly to solve using traditional numerical methods. We provide detailed descriptions of DUE and demonstrate its capabilities through diverse examples, which serve as templates that can be easily adapted for other applications.
IU4Rec: Interest Unit-Based Product Organization and Recommendation for E-Commerce Platform
Feb 11, 2025Most recommendation systems typically follow a product-based paradigm utilizing user-product interactions to identify the most engaging items for users. However, this product-based paradigm has notable drawbacks for Xianyu~\footnote{Xianyu is China's largest online C2C e-commerce platform where a large portion of the product are post by individual sellers}. Most of the product on Xianyu posted from individual sellers often have limited stock available for distribution, and once the product is sold, it's no longer available for distribution. This result in most items distributed product on Xianyu having relatively few interactions, affecting the effectiveness of traditional recommendation depending on accumulating user-item interactions. To address these issues, we introduce \textbf{IU4Rec}, an \textbf{I}nterest \textbf{U}nit-based two-stage \textbf{Rec}ommendation system framework. We first group products into clusters based on attributes such as category, image, and semantics. These IUs are then integrated into the Recommendation system, delivering both product and technological innovations. IU4Rec begins by grouping products into clusters based on attributes such as category, image, and semantics, forming Interest Units (IUs). Then we redesign the recommendation process into two stages. In the first stage, the focus is on recommend these Interest Units, capturing broad-level interests. In the second stage, it guides users to find the best option among similar products within the selected Interest Unit. User-IU interactions are incorporated into our ranking models, offering the advantage of more persistent IU behaviors compared to item-specific interactions. Experimental results on the production dataset and online A/B testing demonstrate the effectiveness and superiority of our proposed IU-centric recommendation approach.
Positional Knowledge is All You Need: Position-induced Transformer for Operator Learning
May 15, 2024Operator learning for Partial Differential Equations (PDEs) is rapidly emerging as a promising approach for surrogate modeling of intricate systems. Transformers with the self-attention mechanism$\unicode{x2013}$a powerful tool originally designed for natural language processing$\unicode{x2013}$have recently been adapted for operator learning. However, they confront challenges, including high computational demands and limited interpretability. This raises a critical question: Is there a more efficient attention mechanism for Transformer-based operator learning? This paper proposes the Position-induced Transformer (PiT), built on an innovative position-attention mechanism, which demonstrates significant advantages over the classical self-attention in operator learning. Position-attention draws inspiration from numerical methods for PDEs. Different from self-attention, position-attention is induced by only the spatial interrelations of sampling positions for input functions of the operators, and does not rely on the input function values themselves, thereby greatly boosting efficiency. PiT exhibits superior performance over current state-of-the-art neural operators in a variety of complex operator learning tasks across diverse PDE benchmarks. Additionally, PiT possesses an enhanced discretization convergence feature, compared to the widely-used Fourier neural operator.
Accelerated K-Serial Stable Coalition for Dynamic Capture and Resource Defense
May 25, 2023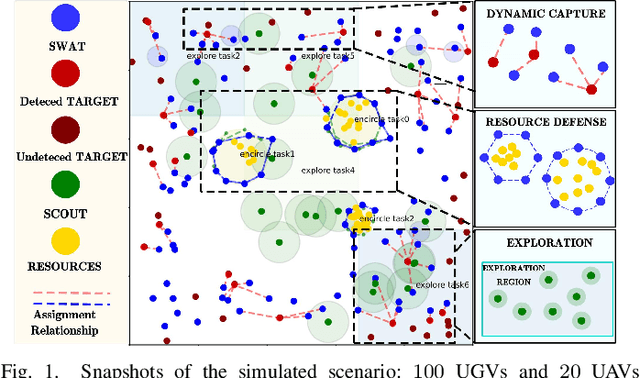
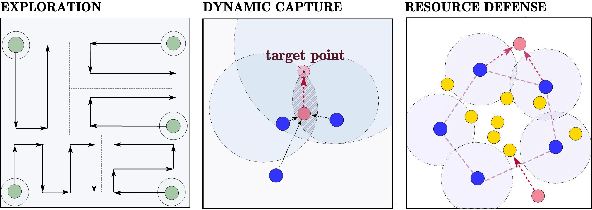
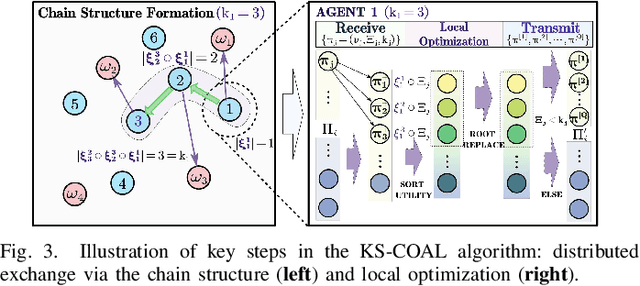
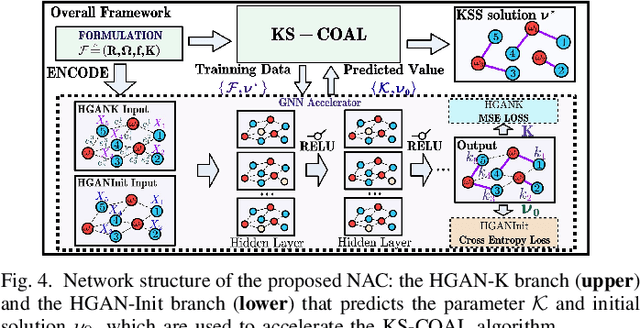
Coalition is an important mean of multi-robot systems to collaborate on common tasks. An effective and adaptive coalition strategy is essential for the online performance in dynamic and unknown environments. In this work, the problem of territory defense by large-scale heterogeneous robotic teams is considered. The tasks include surveillance, capture of dynamic targets, and perimeter defense over valuable resources. Since each robot can choose among many tasks, it remains a challenging problem to coordinate jointly these robots such that the overall utility is maximized. This work proposes a generic coalition strategy called K-serial stable coalition algorithm (KS-COAL). Different from centralized approaches, it is distributed and anytime, meaning that only local communication is required and a K-serial Nash-stable solution is ensured. Furthermore, to accelerate adaptation to dynamic targets and resource distribution that are only perceived online, a heterogeneous graph attention network (HGAN)-based heuristic is learned to select more appropriate parameters and promising initial solutions during local optimization. Compared with manual heuristics or end-to-end predictors, it is shown to both improve online adaptability and retain the quality guarantee. The proposed methods are validated rigorously via large-scale simulations with hundreds of robots, against several strong baselines including GreedyNE and FastMaxSum.
Combinatorial-hybrid Optimization for Multi-agent Systems under Collaborative Tasks
May 22, 2023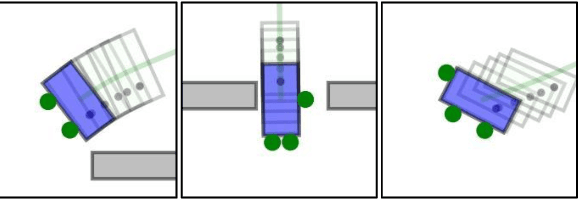
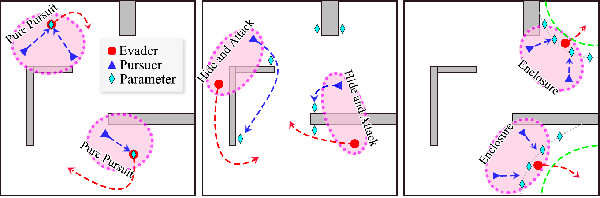
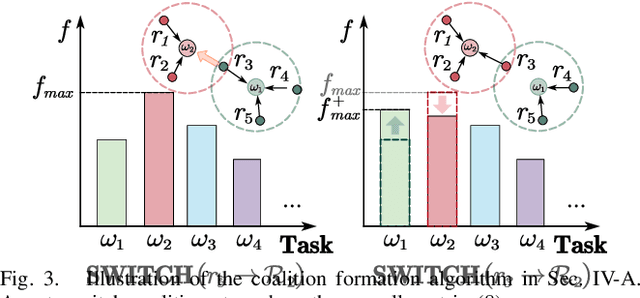

Multi-agent systems can be extremely efficient when working concurrently and collaboratively, e.g., for transportation, maintenance, search and rescue. Coordination of such teams often involves two aspects: (i) selecting appropriate sub-teams for different tasks; (ii) designing collaborative control strategies to execute these tasks. The former aspect can be combinatorial w.r.t. the team size, while the latter requires optimization over joint state-spaces under geometric and dynamic constraints. Existing work often tackles one aspect by assuming the other is given, while ignoring their close dependency. This work formulates such problems as combinatorial-hybrid optimizations (CHO), where both the discrete modes of collaboration and the continuous control parameters are optimized simultaneously and iteratively. The proposed framework consists of two interleaved layers: the dynamic formation of task coalitions and the hybrid optimization of collaborative behaviors. Overall feasibility and costs of different coalitions performing various tasks are approximated at different granularities to improve the computational efficiency. At last, a Nash-stable strategy for both task assignment and execution is derived with provable guarantee on the feasibility and quality. Two non-trivial applications of collaborative transportation and dynamic capture are studied against several baselines.
Deep-OSG: A deep learning approach for approximating a family of operators in semigroup to model unknown autonomous systems
Feb 07, 2023This paper proposes a novel deep learning approach for approximating evolution operators and modeling unknown autonomous dynamical systems using time series data collected at varied time lags. It is a sequel to the previous works [T. Qin, K. Wu, and D. Xiu, J. Comput. Phys., 395:620--635, 2019], [K. Wu and D. Xiu, J. Comput. Phys., 408:109307, 2020], and [Z. Chen, V. Churchill, K. Wu, and D. Xiu, J. Comput. Phys., 449:110782, 2022], which focused on learning single evolution operator with a fixed time step. This paper aims to learn a family of evolution operators with variable time steps, which constitute a semigroup for an autonomous system. The semigroup property is very crucial and links the system's evolutionary behaviors across varying time scales, but it was not considered in the previous works. We propose for the first time a framework of embedding the semigroup property into the data-driven learning process, through a novel neural network architecture and new loss functions. The framework is very feasible, can be combined with any suitable neural networks, and is applicable to learning general autonomous ODEs and PDEs. We present the rigorous error estimates and variance analysis to understand the prediction accuracy and robustness of our approach, showing the remarkable advantages of semigroup awareness in our model. Moreover, our approach allows one to arbitrarily choose the time steps for prediction and ensures that the predicted results are well self-matched and consistent. Extensive numerical experiments demonstrate that embedding the semigroup property notably reduces the data dependency of deep learning models and greatly improves the accuracy, robustness, and stability for long-time prediction.