 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriple Spectral Fusion for Sensor-based Human Activity Recognition
May 04, 2026The field of sensor-based human activity recognition (HAR) mainly uses posture, motion and context data of Inertial Measurement Units (IMUs) to identify daily activities. Despite the advancements in learning-based methods, it is challenging to perform information fusion from the temporal perspective due to the complexities in fusing heterogeneous sensor data and establishing long-term context correlations. This paper proposes a novel triple spectral fusion framework tailored for HAR. First, we develop an adaptive complementary filtering technique for noise suppression and organize each IMU's sensors into posture and motion modality nodes. Given that IMU nodes form a dynamic heterogeneous graph, we then apply adaptive filtering within the graph Fourier domain to merge both homogeneous and heterogeneous node information. Furthermore, an adaptive wavelet frequency selection approach is implemented to suppress context redundancy and shorten the length of features. This approach enhances both timestamp-based graph aggregation and the correlation of long-term contexts. Our framework uses adaptive filtering in the Fourier, graph Fourier, and wavelet domains, enabling effective multi-sensor fusion and context correlation. Extensive experiments on ten benchmark datasets demonstrate the superior performance of our framework. Project page: https://github.com/crocodilegogogo/TSF-TPAMI2026.
MagicAgent: Towards Generalized Agent Planning
Feb 22, 2026The evolution of Large Language Models (LLMs) from passive text processors to autonomous agents has established planning as a core component of modern intelligence. However, achieving generalized planning remains elusive, not only by the scarcity of high-quality interaction data but also by inherent conflicts across heterogeneous planning tasks. These challenges result in models that excel at isolated tasks yet struggle to generalize, while existing multi-task training attempts suffer from gradient interference. In this paper, we present \textbf{MagicAgent}, a series of foundation models specifically designed for generalized agent planning. We introduce a lightweight and scalable synthetic data framework that generates high-quality trajectories across diverse planning tasks, including hierarchical task decomposition, tool-augmented planning, multi-constraint scheduling, procedural logic orchestration, and long-horizon tool execution. To mitigate training conflicts, we propose a two-stage training paradigm comprising supervised fine-tuning followed by multi-objective reinforcement learning over both static datasets and dynamic environments. Empirical results demonstrate that MagicAgent-32B and MagicAgent-30B-A3B deliver superior performance, achieving accuracies of $75.1\%$ on Worfbench, $55.9\%$ on NaturalPlan, $57.5\%$ on $τ^2$-Bench, $86.9\%$ on BFCL-v3, and $81.2\%$ on ACEBench, as well as strong results on our in-house MagicEval benchmarks. These results substantially outperform existing sub-100B models and even surpass leading closed-source models.
DScheLLM: Enabling Dynamic Scheduling through a Fine-Tuned Dual-System Large language Model
Jan 15, 2026Production scheduling is highly susceptible to dynamic disruptions, such as variations in processing times, machine availability, and unexpected task insertions. Conventional approaches typically rely on event-specific models and explicit analytical formulations, which limits their adaptability and generalization across previously unseen disturbances. To overcome these limitations, this paper proposes DScheLLM, a dynamic scheduling approach that leverages fine-tuned large language models within a dual-system (fast-slow) reasoning architecture to address disturbances of different scales. A unified large language model-based framework is constructed to handle dynamic events, where training datasets for both fast and slow reasoning modes are generated using exact schedules obtained from an operations research solver. The Huawei OpenPangu Embedded-7B model is subsequently fine-tuned under the hybrid reasoning paradigms using LoRA. Experimental evaluations on standard job shop scheduling benchmarks demonstrate that the fast-thinking mode can efficiently generate high-quality schedules and the slow-thinking mode can produce solver-compatible and well-formatted decision inputs. To the best of our knowledge, this work represents one of the earliest studies applying large language models to job shop scheduling in dynamic environments, highlighting their considerable potential for intelligent and adaptive scheduling optimization.
A Powered Prosthetic Hand with Vision System for Enhancing the Anthropopathic Grasp
Dec 10, 2024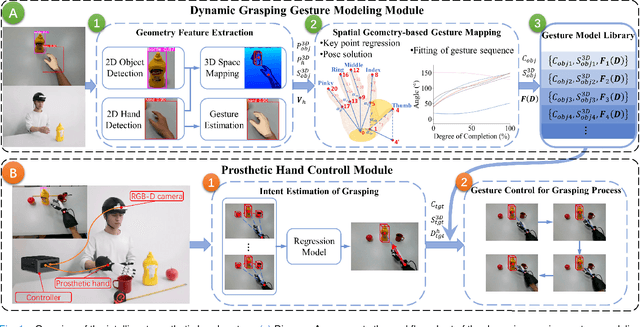
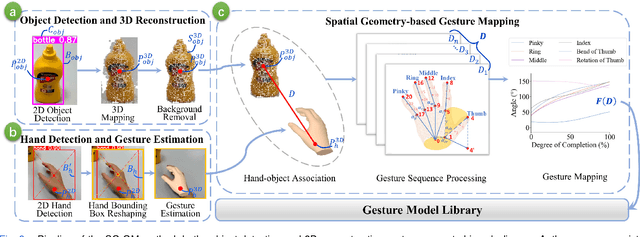
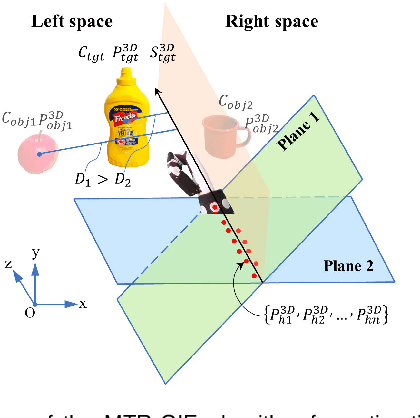

The anthropomorphism of grasping process significantly benefits the experience and grasping efficiency of prosthetic hand wearers. Currently, prosthetic hands controlled by signals such as brain-computer interfaces (BCI) and electromyography (EMG) face difficulties in precisely recognizing the amputees' grasping gestures and executing anthropomorphic grasp processes. Although prosthetic hands equipped with vision systems enables the objects' feature recognition, they lack perception of human grasping intention. Therefore, this paper explores the estimation of grasping gestures solely through visual data to accomplish anthropopathic grasping control and the determination of grasping intention within a multi-object environment. To address this, we propose the Spatial Geometry-based Gesture Mapping (SG-GM) method, which constructs gesture functions based on the geometric features of the human hand grasping processes. It's subsequently implemented on the prosthetic hand. Furthermore, we propose the Motion Trajectory Regression-based Grasping Intent Estimation (MTR-GIE) algorithm. This algorithm predicts pre-grasping object utilizing regression prediction and prior spatial segmentation estimation derived from the prosthetic hand's position and trajectory. The experiments were conducted to grasp 8 common daily objects including cup, fork, etc. The experimental results presented a similarity coefficient $R^{2}$ of grasping process of 0.911, a Root Mean Squared Error ($RMSE$) of 2.47\degree, a success rate of grasping of 95.43$\%$, and an average duration of grasping process of 3.07$\pm$0.41 s. Furthermore, grasping experiments in a multi-object environment were conducted. The average accuracy of intent estimation reached 94.35$\%$. Our methodologies offer a groundbreaking approach to enhance the prosthetic hand's functionality and provides valuable insights for future research.
D3PRefiner: A Diffusion-based Denoise Method for 3D Human Pose Refinement
Jan 08, 2024Three-dimensional (3D) human pose estimation using a monocular camera has gained increasing attention due to its ease of implementation and the abundance of data available from daily life. However, owing to the inherent depth ambiguity in images, the accuracy of existing monocular camera-based 3D pose estimation methods remains unsatisfactory, and the estimated 3D poses usually include much noise. By observing the histogram of this noise, we find each dimension of the noise follows a certain distribution, which indicates the possibility for a neural network to learn the mapping between noisy poses and ground truth poses. In this work, in order to obtain more accurate 3D poses, a Diffusion-based 3D Pose Refiner (D3PRefiner) is proposed to refine the output of any existing 3D pose estimator. We first introduce a conditional multivariate Gaussian distribution to model the distribution of noisy 3D poses, using paired 2D poses and noisy 3D poses as conditions to achieve greater accuracy. Additionally, we leverage the architecture of current diffusion models to convert the distribution of noisy 3D poses into ground truth 3D poses. To evaluate the effectiveness of the proposed method, two state-of-the-art sequence-to-sequence 3D pose estimators are used as basic 3D pose estimation models, and the proposed method is evaluated on different types of 2D poses and different lengths of the input sequence. Experimental results demonstrate the proposed architecture can significantly improve the performance of current sequence-to-sequence 3D pose estimators, with a reduction of at least 10.3% in the mean per joint position error (MPJPE) and at least 11.0% in the Procrustes MPJPE (P-MPJPE).
Lifelong-MonoDepth: Lifelong Learning for Multi-Domain Monocular Metric Depth Estimation
Mar 09, 2023



In recent years, monocular depth estimation (MDE) has gained significant progress in a data-driven learning fashion. Previous methods can infer depth maps for specific domains based on the paradigm of single-domain or joint-domain training with mixed data. However, they suffer from low scalability to new domains. In reality, target domains often dynamically change or increase, raising the requirement of incremental multi-domain/task learning. In this paper, we seek to enable lifelong learning for MDE, which performs cross-domain depth learning sequentially, to achieve high plasticity on a new domain and maintain good stability on original domains. To overcome significant domain gaps and enable scale-aware depth prediction, we design a lightweight multi-head framework that consists of a domain-shared encoder for feature extraction and domain-specific predictors for metric depth estimation. Moreover, given an input image, we propose an efficient predictor selection approach that automatically identifies the corresponding predictor for depth inference. Through extensive numerical studies, we show that the proposed method can achieve good efficiency, stability, and plasticity, leading the benchmarks by 8% to 15%.
Deep Depth Completion: A Survey
May 17, 2022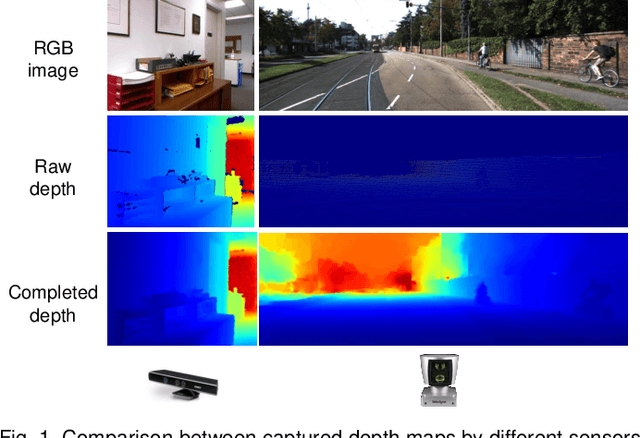
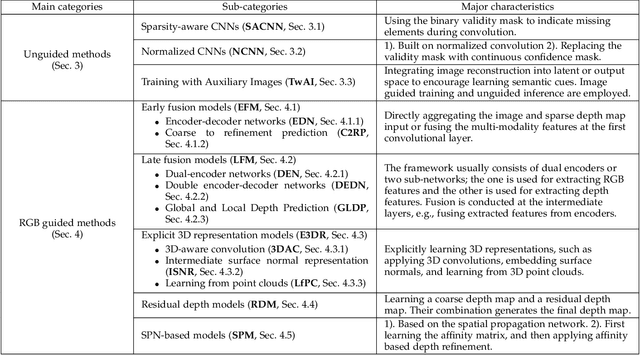
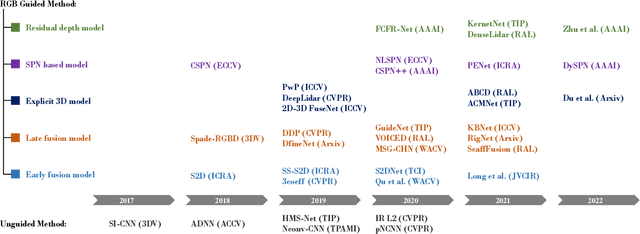
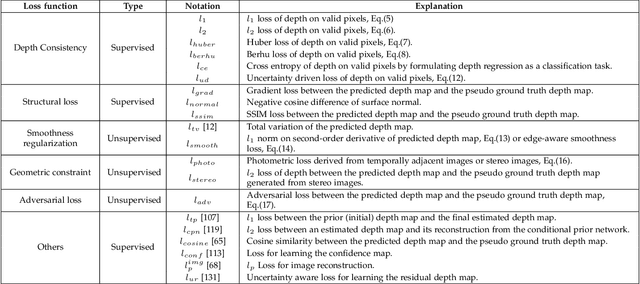
Depth completion aims at predicting dense pixel-wise depth from a sparse map captured from a depth sensor. It plays an essential role in various applications such as autonomous driving, 3D reconstruction, augmented reality, and robot navigation. Recent successes on the task have been demonstrated and dominated by deep learning based solutions. In this article, for the first time, we provide a comprehensive literature review that helps readers better grasp the research trends and clearly understand the current advances. We investigate the related studies from the design aspects of network architectures, loss functions, benchmark datasets, and learning strategies with a proposal of a novel taxonomy that categorizes existing methods. Besides, we present a quantitative comparison of model performance on two widely used benchmark datasets, including an indoor and an outdoor dataset. Finally, we discuss the challenges of prior works and provide readers with some insights for future research directions.
Quantum Graph Convolutional Neural Networks
Jul 07, 2021
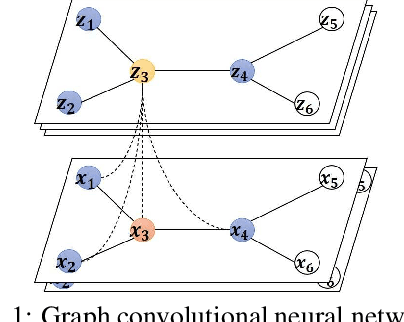
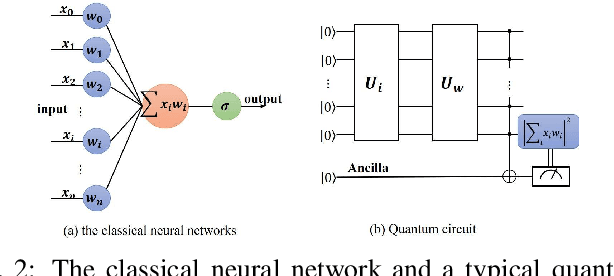
At present, there are a large number of quantum neural network models to deal with Euclidean spatial data, while little research have been conducted on non-Euclidean spatial data. In this paper, we propose a novel quantum graph convolutional neural network (QGCN) model based on quantum parametric circuits and utilize the computing power of quantum systems to accomplish graph classification tasks in traditional machine learning. The proposed QGCN model has a similar architecture as the classical graph convolutional neural networks, which can illustrate the topology of the graph type data and efficiently learn the hidden layer representation of node features as well. Numerical simulation results on a graph dataset demonstrate that the proposed model can be effectively trained and has good performance in graph level classification tasks.
Design and Control of a Highly Redundant Rigid-Flexible Coupling Robot to Assist the COVID-19 Oropharyngeal-Swab Sampling
Feb 25, 2021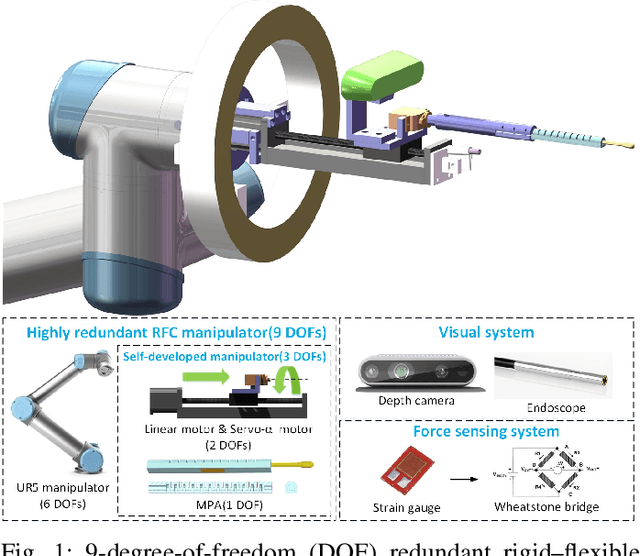
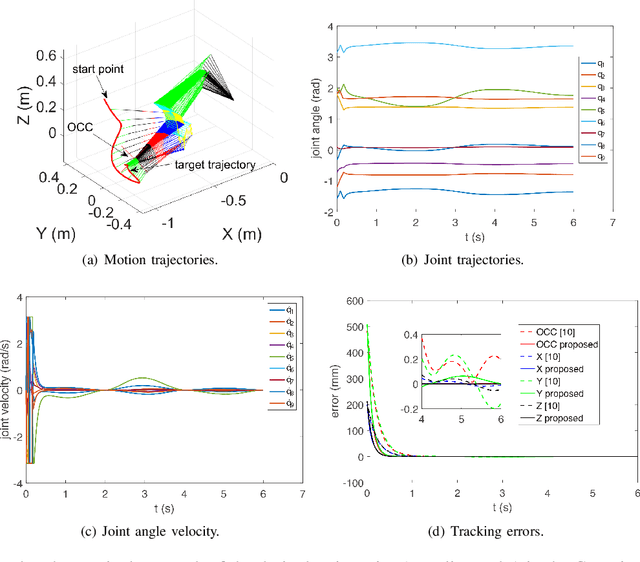
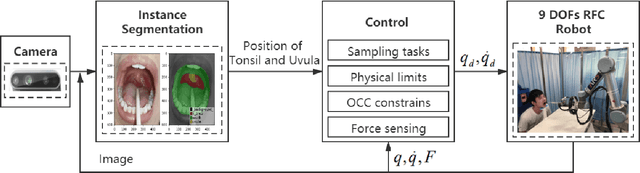
The outbreak of novel coronavirus pneumonia (COVID-19) has caused mortality and morbidity worldwide. Oropharyngeal-swab (OP-swab) sampling is widely used for the diagnosis of COVID-19 in the world. To avoid the clinical staff from being affected by the virus, we developed a 9-degree-of-freedom (DOF) rigid-flexible coupling (RFC) robot to assist the COVID-19 OP-swab sampling. This robot is composed of a visual system, UR5 robot arm, micro-pneumatic actuator and force-sensing system. The robot is expected to reduce risk and free up the clinical staff from the long-term repetitive sampling work. Compared with a rigid sampling robot, the developed force-sensing RFC robot can facilitate OP-swab sampling procedures in a safer and softer way. In addition, a varying-parameter zeroing neural network-based optimization method is also proposed for motion planning of the 9-DOF redundant manipulator. The developed robot system is validated by OP-swab sampling on both oral cavity phantoms and volunteers.
Do You Live a Healthy Life? Analyzing Lifestyle by Visual Life Logging
Nov 24, 2020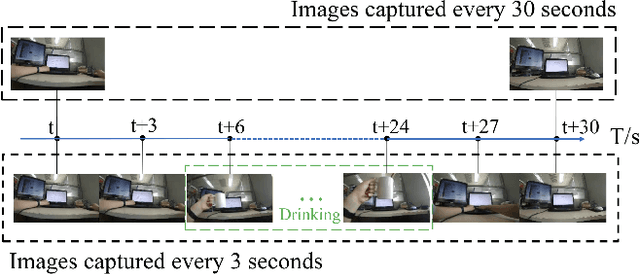

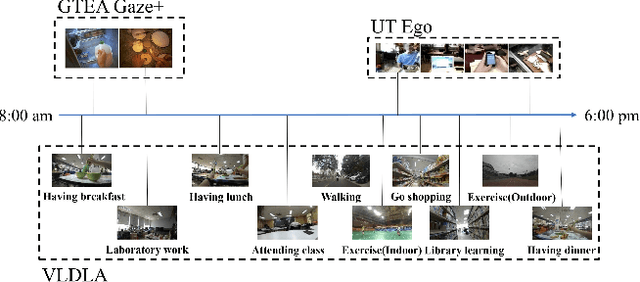

A healthy lifestyle is the key to better health and happiness and has a considerable effect on quality of life and disease prevention. Current lifelogging/egocentric datasets are not suitable for lifestyle analysis; consequently, there is no research on lifestyle analysis in the field of computer vision. In this work, we investigate the problem of lifestyle analysis and build a visual lifelogging dataset for lifestyle analysis (VLDLA). The VLDLA contains images captured by a wearable camera every 3 seconds from 8:00 am to 6:00 pm for seven days. In contrast to current lifelogging/egocentric datasets, our dataset is suitable for lifestyle analysis as images are taken with short intervals to capture activities of short duration; moreover, images are taken continuously from morning to evening to record all the activities performed by a user. Based on our dataset, we classify the user activities in each frame and use three latent fluents of the user, which change over time and are associated with activities, to measure the healthy degree of the user's lifestyle. The scores for the three latent fluents are computed based on recognized activities, and the healthy degree of the lifestyle for the day is determined based on the scores for the latent fluents. Experimental results show that our method can be used to analyze the healthiness of users' lifestyles.