 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeer Learning for Unbiased Scene Graph Generation
Paper and Code
Dec 31, 2022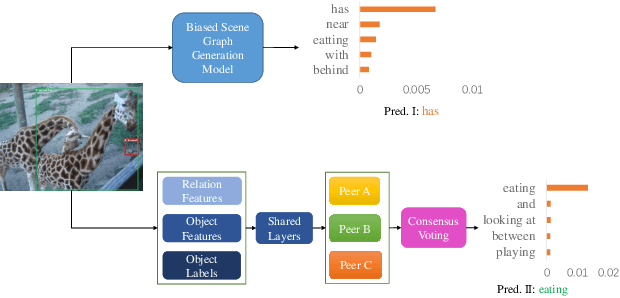
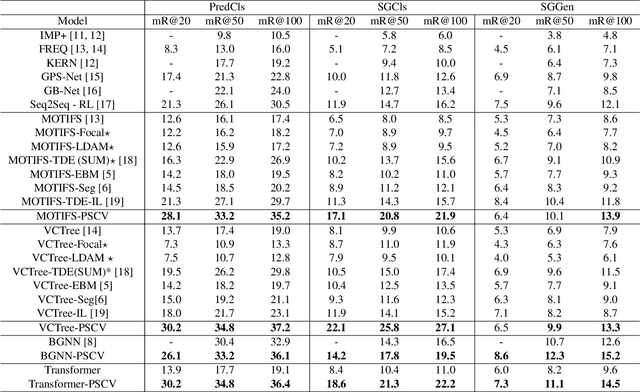
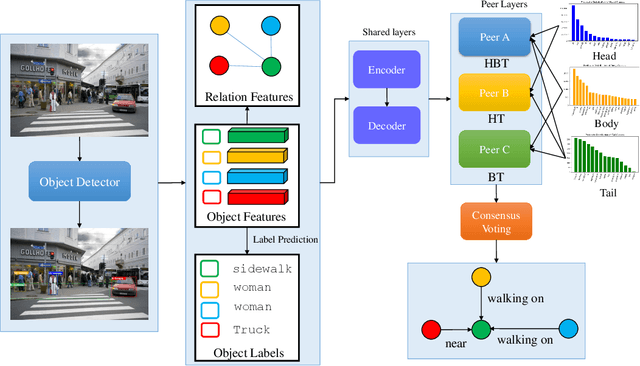
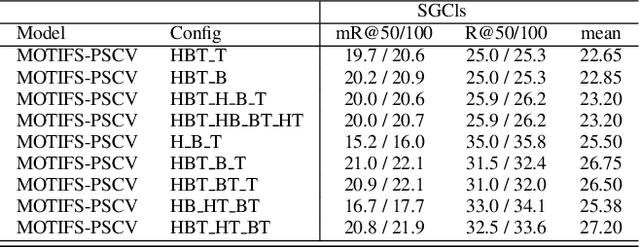
In this paper, we propose a novel framework dubbed peer learning to deal with the problem of biased scene graph generation (SGG). This framework uses predicate sampling and consensus voting (PSCV) to encourage different peers to learn from each other, improving model diversity and mitigating bias in SGG. To address the heavily long-tailed distribution of predicate classes, we propose to use predicate sampling to divide and conquer this issue. As a result, the model is less biased and makes more balanced predicate predictions. Specifically, one peer may not be sufficiently diverse to discriminate between different levels of predicate distributions. Therefore, we sample the data distribution based on frequency of predicates into sub-distributions, selecting head, body, and tail classes to combine and feed to different peers as complementary predicate knowledge during the training process. The complementary predicate knowledge of these peers is then ensembled utilizing a consensus voting strategy, which simulates a civilized voting process in our society that emphasizes the majority opinion and diminishes the minority opinion. This approach ensures that the learned representations of each peer are optimally adapted to the various data distributions. Extensive experiments on the Visual Genome dataset demonstrate that PSCV outperforms previous methods. We have established a new state-of-the-art (SOTA) on the SGCls task by achieving a mean of \textbf{31.6}.