 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeer Learning for Unbiased Scene Graph Generation
Dec 31, 2022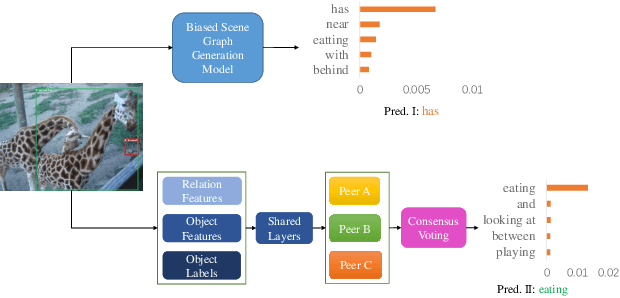
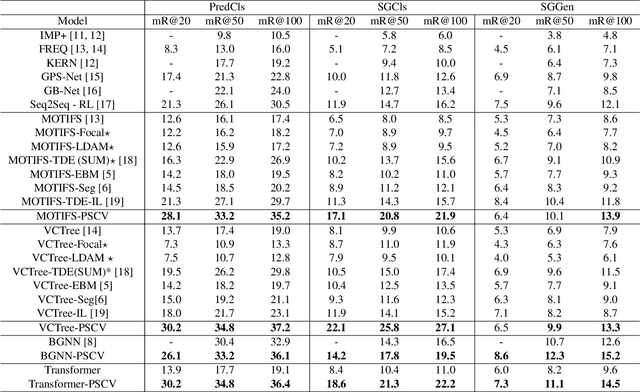
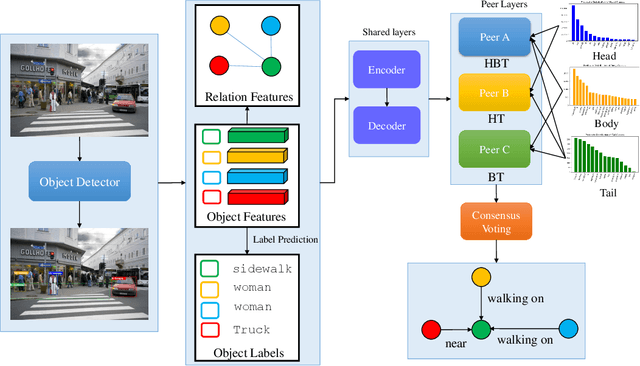
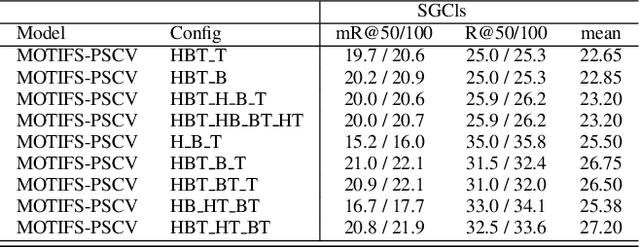
In this paper, we propose a novel framework dubbed peer learning to deal with the problem of biased scene graph generation (SGG). This framework uses predicate sampling and consensus voting (PSCV) to encourage different peers to learn from each other, improving model diversity and mitigating bias in SGG. To address the heavily long-tailed distribution of predicate classes, we propose to use predicate sampling to divide and conquer this issue. As a result, the model is less biased and makes more balanced predicate predictions. Specifically, one peer may not be sufficiently diverse to discriminate between different levels of predicate distributions. Therefore, we sample the data distribution based on frequency of predicates into sub-distributions, selecting head, body, and tail classes to combine and feed to different peers as complementary predicate knowledge during the training process. The complementary predicate knowledge of these peers is then ensembled utilizing a consensus voting strategy, which simulates a civilized voting process in our society that emphasizes the majority opinion and diminishes the minority opinion. This approach ensures that the learned representations of each peer are optimally adapted to the various data distributions. Extensive experiments on the Visual Genome dataset demonstrate that PSCV outperforms previous methods. We have established a new state-of-the-art (SOTA) on the SGCls task by achieving a mean of \textbf{31.6}.
Attentional Graph Convolutional Network for Structure-aware Audio-Visual Scene Classification
Dec 31, 2022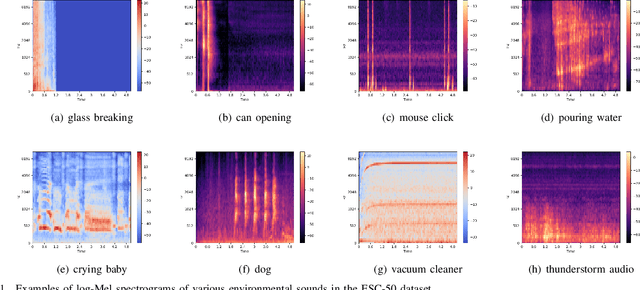
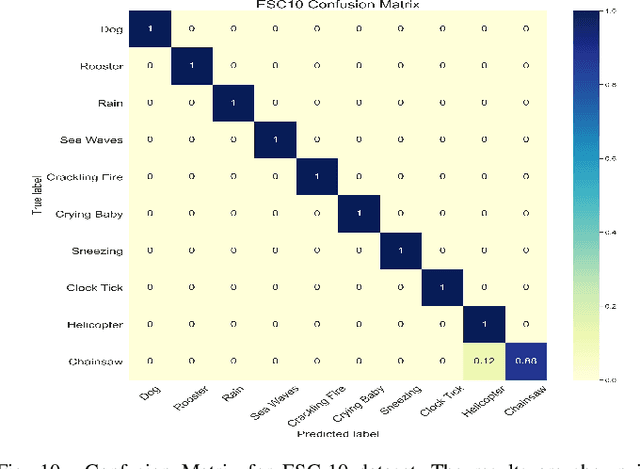
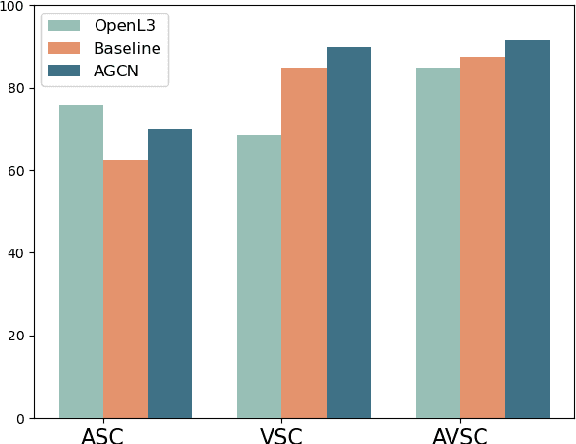
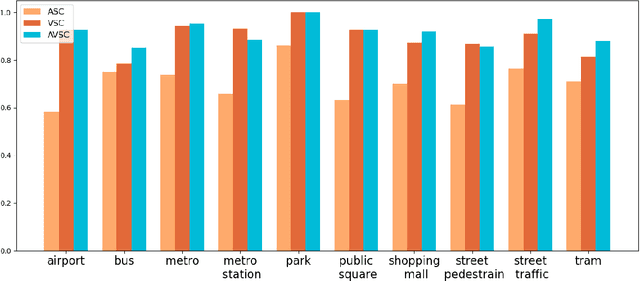
Audio-Visual scene understanding is a challenging problem due to the unstructured spatial-temporal relations that exist in the audio signals and spatial layouts of different objects and various texture patterns in the visual images. Recently, many studies have focused on abstracting features from convolutional neural networks while the learning of explicit semantically relevant frames of sound signals and visual images has been overlooked. To this end, we present an end-to-end framework, namely attentional graph convolutional network (AGCN), for structure-aware audio-visual scene representation. First, the spectrogram of sound and input image is processed by a backbone network for feature extraction. Then, to build multi-scale hierarchical information of input features, we utilize an attention fusion mechanism to aggregate features from multiple layers of the backbone network. Notably, to well represent the salient regions and contextual information of audio-visual inputs, the salient acoustic graph (SAG) and contextual acoustic graph (CAG), salient visual graph (SVG), and contextual visual graph (CVG) are constructed for the audio-visual scene representation. Finally, the constructed graphs pass through a graph convolutional network for structure-aware audio-visual scene recognition. Extensive experimental results on the audio, visual and audio-visual scene recognition datasets show that promising results have been achieved by the AGCN methods. Visualizing graphs on the spectrograms and images have been presented to show the effectiveness of proposed CAG/SAG and CVG/SVG that could focus on the salient and semantic relevant regions.
Context-aware Mixture-of-Experts for Unbiased Scene Graph Generation
Aug 21, 2022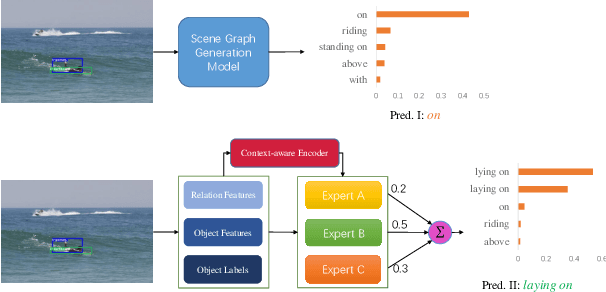
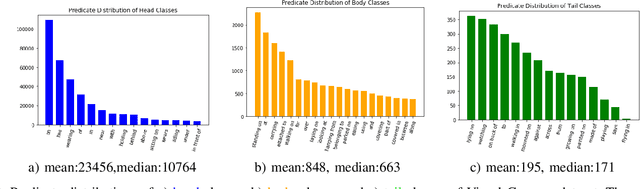
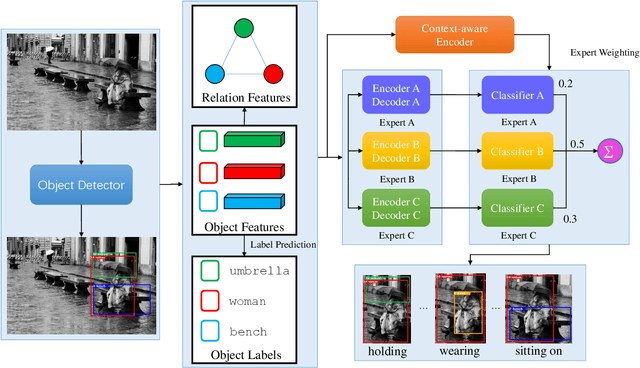
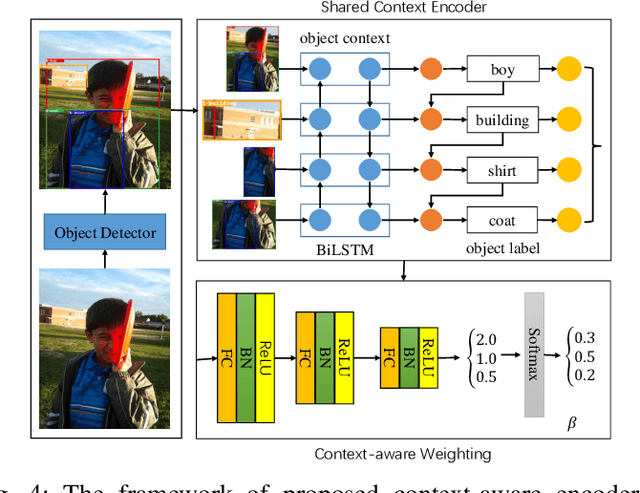
The scene graph generation has gained tremendous progress in recent years. However, its intrinsic long-tailed distribution of predicate classes is a challenging problem. Almost all existing scene graph generation (SGG) methods follow the same framework where they use a similar backbone network for object detection and a customized network for scene graph generation. These methods often design the sophisticated context-encoder to extract the inherent relevance of scene context w.r.t the intrinsic predicates and complicated networks to improve the learning capabilities of the network model for highly imbalanced data distributions. To address the unbiased SGG problem, we present a simple yet effective method called Context-Aware Mixture-of-Experts (CAME) to improve the model diversity and alleviate the biased SGG without a sophisticated design. Specifically, we propose to use the mixture of experts to remedy the heavily long-tailed distributions of predicate classes, which is suitable for most unbiased scene graph generators. With a mixture of relation experts, the long-tailed distribution of predicates is addressed in a divide and ensemble manner. As a result, the biased SGG is mitigated and the model tends to make more balanced predicates predictions. However, experts with the same weight are not sufficiently diverse to discriminate the different levels of predicates distributions. Hence, we simply use the build-in context-aware encoder, to help the network dynamically leverage the rich scene characteristics to further increase the diversity of the model. By utilizing the context information of the image, the importance of each expert w.r.t the scene context is dynamically assigned. We have conducted extensive experiments on three tasks on the Visual Genome dataset to show that came achieved superior performance over previous methods.
Feature Pyramid Attention based Residual Neural Network for Environmental Sound Classification
May 28, 2022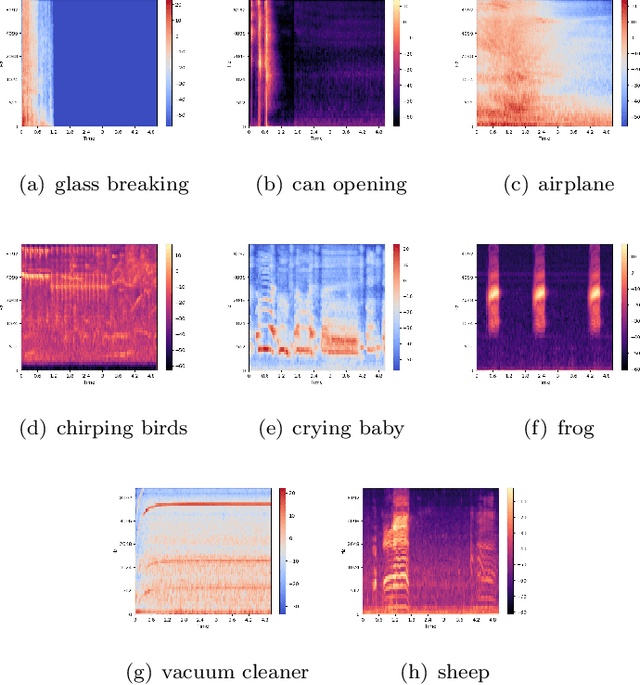
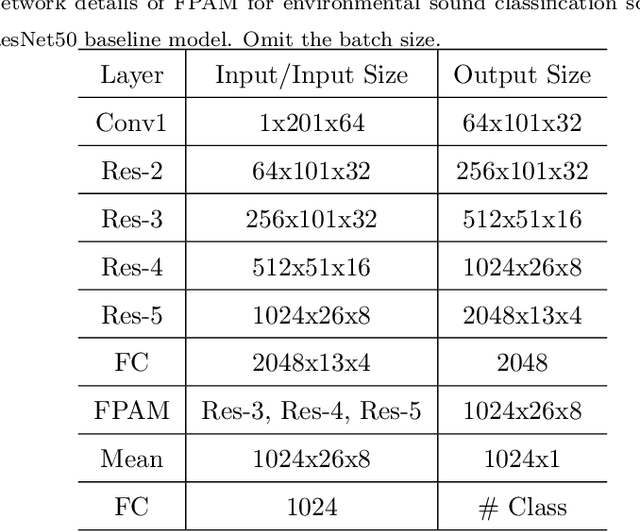
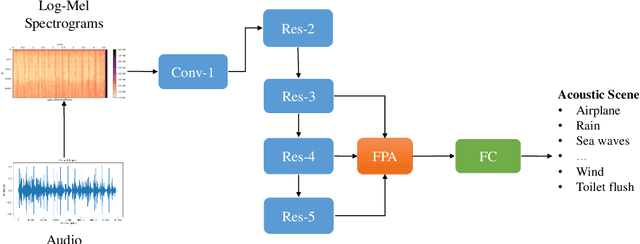

Environmental sound classification (ESC) is a challenging problem due to the unstructured spatial-temporal relations that exist in the sound signals. Recently, many studies have focused on abstracting features from convolutional neural networks while the learning of semantically relevant frames of sound signals has been overlooked. To this end, we present an end-to-end framework, namely feature pyramid attention network (FPAM), focusing on abstracting the semantically relevant features for ESC. We first extract the feature maps of the preprocessed spectrogram of the sound waveform by a backbone network. Then, to build multi-scale hierarchical features of sound spectrograms, we construct a feature pyramid representation of the sound spectrograms by aggregating the feature maps from multi-scale layers, where the temporal frames and spatial locations of semantically relevant frames are localized by FPAM. Specifically, the multiple features are first processed by a dimension alignment module. Afterward, the pyramid spatial attention module (PSA) is attached to localize the important frequency regions spatially with a spatial attention module (SAM). Last, the processed feature maps are refined by a pyramid channel attention (PCA) to localize the important temporal frames. To justify the effectiveness of the proposed FPAM, visualization of attention maps on the spectrograms has been presented. The visualization results show that FPAM can focus more on the semantic relevant regions while neglecting the noises. The effectiveness of the proposed methods is validated on two widely used ESC datasets: the ESC-50 and ESC-10 datasets. The experimental results show that the FPAM yields comparable performance to state-of-the-art methods. A substantial performance increase has been achieved by FPAM compared with the baseline methods.
View Blind-spot as Inpainting: Self-Supervised Denoising with Mask Guided Residual Convolution
Sep 10, 2021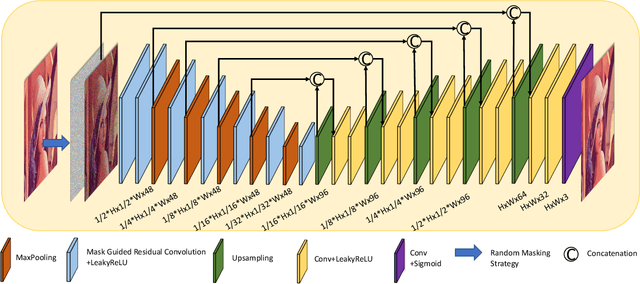


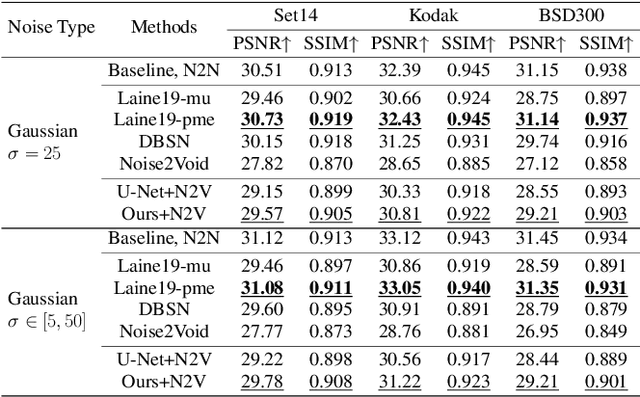
In recent years, self-supervised denoising methods have shown impressive performance, which circumvent painstaking collection procedure of noisy-clean image pairs in supervised denoising methods and boost denoising applicability in real world. One of well-known self-supervised denoising strategies is the blind-spot training scheme. However, a few works attempt to improve blind-spot based self-denoiser in the aspect of network architecture. In this paper, we take an intuitive view of blind-spot strategy and consider its process of using neighbor pixels to predict manipulated pixels as an inpainting process. Therefore, we propose a novel Mask Guided Residual Convolution (MGRConv) into common convolutional neural networks, e.g. U-Net, to promote blind-spot based denoising. Our MGRConv can be regarded as soft partial convolution and find a trade-off among partial convolution, learnable attention maps, and gated convolution. It enables dynamic mask learning with appropriate mask constrain. Different from partial convolution and gated convolution, it provides moderate freedom for network learning. It also avoids leveraging external learnable parameters for mask activation, unlike learnable attention maps. The experiments show that our proposed plug-and-play MGRConv can assist blind-spot based denoising network to reach promising results on both existing single-image based and dataset-based methods.
Object-to-Scene: Learning to Transfer Object Knowledge to Indoor Scene Recognition
Aug 01, 2021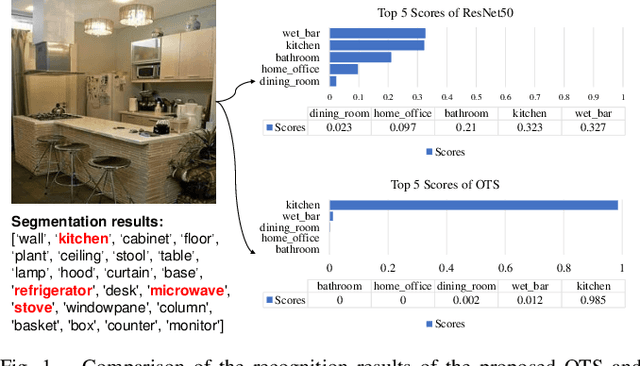
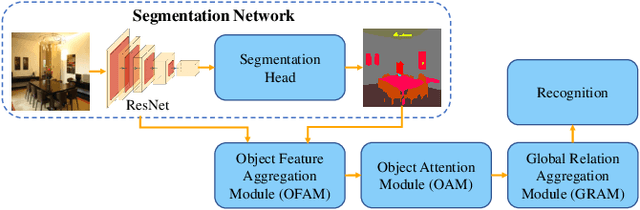
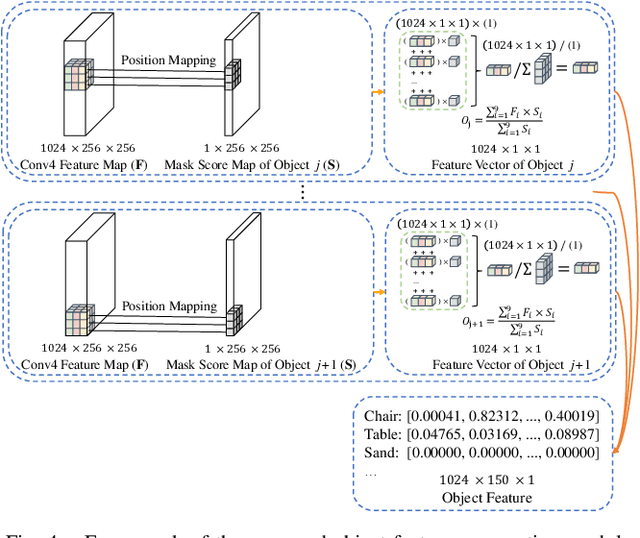
Accurate perception of the surrounding scene is helpful for robots to make reasonable judgments and behaviours. Therefore, developing effective scene representation and recognition methods are of significant importance in robotics. Currently, a large body of research focuses on developing novel auxiliary features and networks to improve indoor scene recognition ability. However, few of them focus on directly constructing object features and relations for indoor scene recognition. In this paper, we analyze the weaknesses of current methods and propose an Object-to-Scene (OTS) method, which extracts object features and learns object relations to recognize indoor scenes. The proposed OTS first extracts object features based on the segmentation network and the proposed object feature aggregation module (OFAM). Afterwards, the object relations are calculated and the scene representation is constructed based on the proposed object attention module (OAM) and global relation aggregation module (GRAM). The final results in this work show that OTS successfully extracts object features and learns object relations from the segmentation network. Moreover, OTS outperforms the state-of-the-art methods by more than 2\% on indoor scene recognition without using any additional streams. Code is publicly available at: https://github.com/FreeformRobotics/OTS.
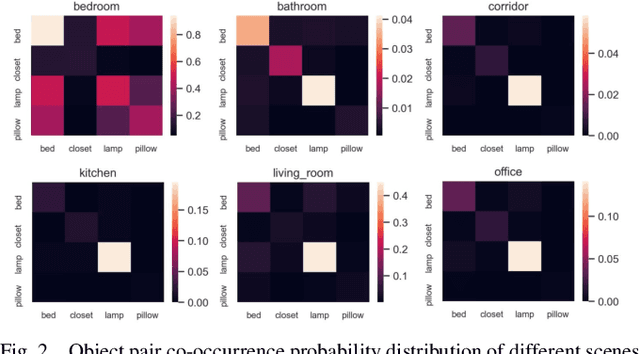
BORM: Bayesian Object Relation Model for Indoor Scene Recognition
Aug 01, 2021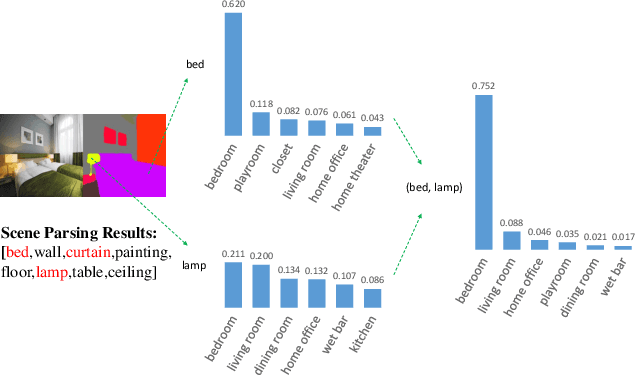
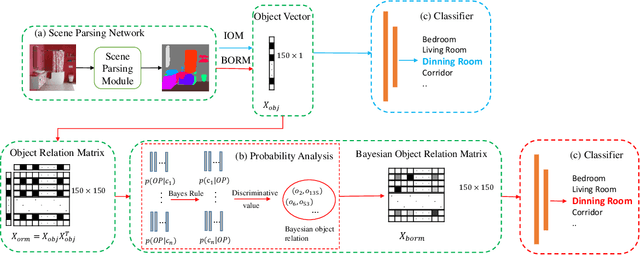
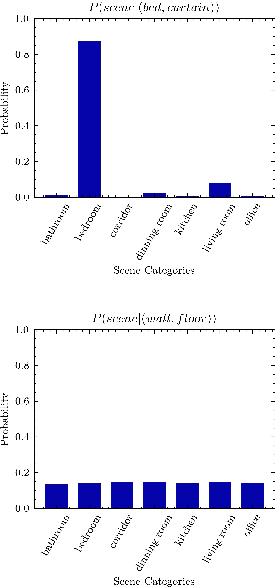
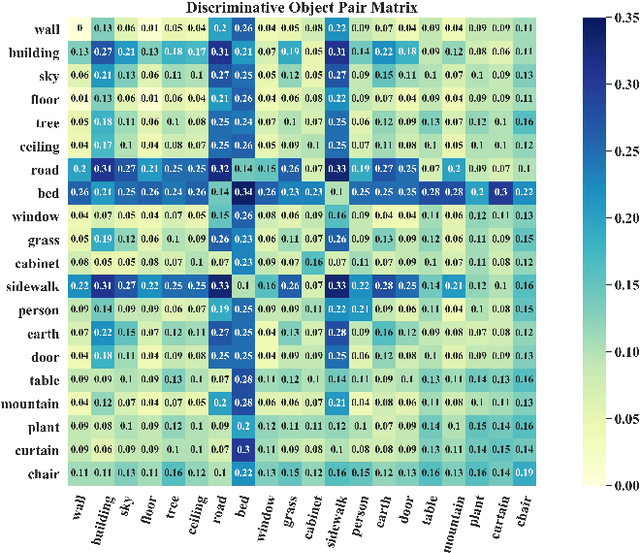
Scene recognition is a fundamental task in robotic perception. For human beings, scene recognition is reasonable because they have abundant object knowledge of the real world. The idea of transferring prior object knowledge from humans to scene recognition is significant but still less exploited. In this paper, we propose to utilize meaningful object representations for indoor scene representation. First, we utilize an improved object model (IOM) as a baseline that enriches the object knowledge by introducing a scene parsing algorithm pretrained on the ADE20K dataset with rich object categories related to the indoor scene. To analyze the object co-occurrences and pairwise object relations, we formulate the IOM from a Bayesian perspective as the Bayesian object relation model (BORM). Meanwhile, we incorporate the proposed BORM with the PlacesCNN model as the combined Bayesian object relation model (CBORM) for scene recognition and significantly outperforms the state-of-the-art methods on the reduced Places365 dataset, and SUN RGB-D dataset without retraining, showing the excellent generalization ability of the proposed method. Code can be found at https://github.com/hszhoushen/borm.
* 8 pages, 5 figures, conference, Accepted by IROS2021
Human Perception Modeling for Automatic Natural Image Matting
Mar 31, 2021
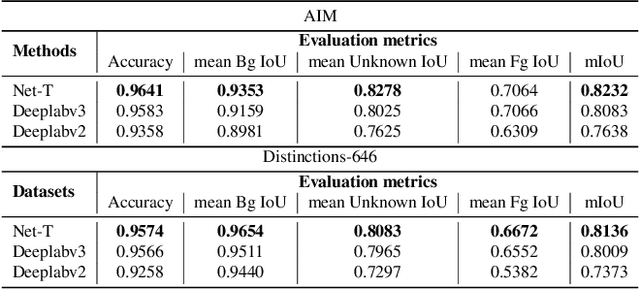
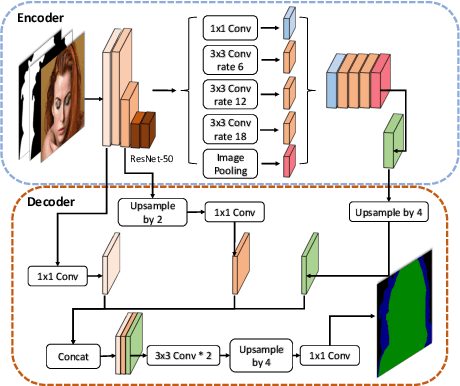

Natural image matting aims to precisely separate foreground objects from background using alpha matte. Fully automatic natural image matting without external annotation is quite challenging. Well-performed matting methods usually require accurate handcrafted trimap as extra input, which is labor-intensive and time-consuming, while the performance of automatic trimap generation method of dilating foreground segmentation fluctuates with segmentation quality. In this paper, we argue that how to handle trade-off of additional information input is a major issue in automatic matting, which we decompose into two subtasks: trimap and alpha estimation. By leveraging easily-accessible coarse annotations and modeling alpha matte handmade process of capturing rough foreground/background/transition boundary and carving delicate details in transition region, we propose an intuitively-designed trimap-free two-stage matting approach without additional annotations, e.g. trimap and background image. Specifically, given an image and its coarse foreground segmentation, Trimap Generation Network estimates probabilities of foreground, unknown, and background regions to guide alpha feature flow of our proposed Non-Local Matting network, which is equipped with trimap-guided global aggregation attention block. Experimental results show that our matting algorithm has competitive performance with current state-of-the-art methods in both trimap-free and trimap-needed aspects.
SplitNet: Divide and Co-training
Dec 29, 2020

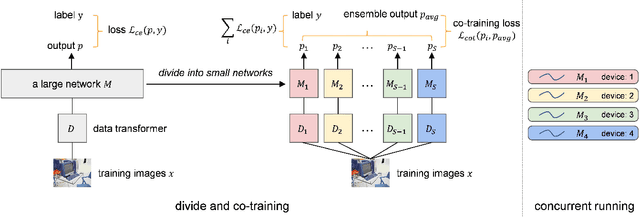

The width of a neural network matters since increasing the width will necessarily increase the model capacity. However, the performance of a network does not improve linearly with the width and soon gets saturated. To tackle this problem, we propose to increase the number of networks rather than purely scaling up the width. To prove it, one large network is divided into several small ones, and each of these small networks has a fraction of the original one's parameters. We then train these small networks together and make them see various views of the same data to learn different and complementary knowledge. During this co-training process, networks can also learn from each other. As a result, small networks can achieve better ensemble performance than the large one with few or no extra parameters or FLOPs. \emph{This reveals that the number of networks is a new dimension of effective model scaling, besides depth/width/resolution}. Small networks can also achieve faster inference speed than the large one by concurrent running on different devices. We validate the idea -- increasing the number of networks is a new dimension of effective model scaling -- with different network architectures on common benchmarks through extensive experiments. The code is available at \url{https://github.com/mzhaoshuai/SplitNet-Divide-and-Co-training}.
IROS 2019 Lifelong Robotic Vision Challenge -- Lifelong Object Recognition Report
Apr 26, 2020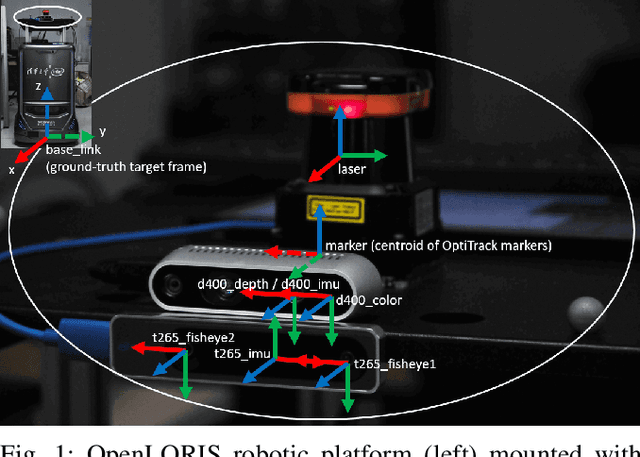
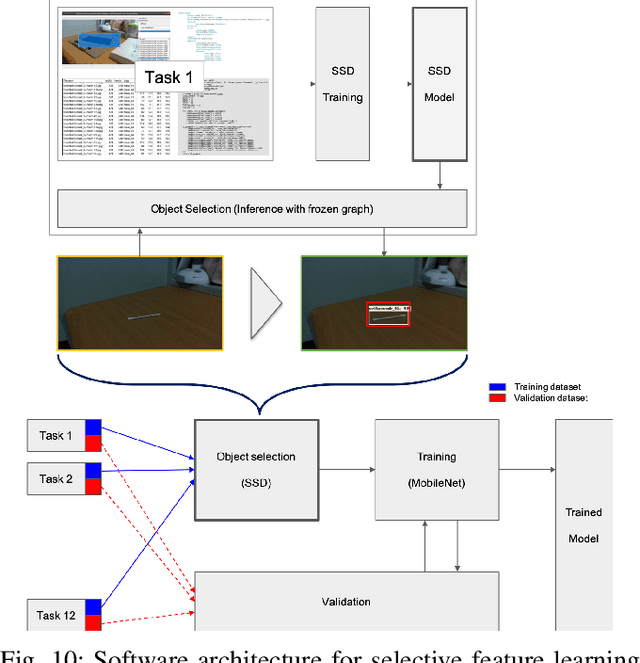
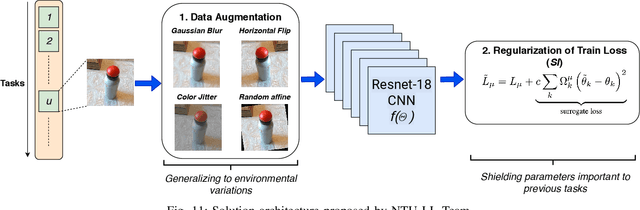

This report summarizes IROS 2019-Lifelong Robotic Vision Competition (Lifelong Object Recognition Challenge) with methods and results from the top $8$ finalists (out of over~$150$ teams). The competition dataset (L)ifel(O)ng (R)obotic V(IS)ion (OpenLORIS) - Object Recognition (OpenLORIS-object) is designed for driving lifelong/continual learning research and application in robotic vision domain, with everyday objects in home, office, campus, and mall scenarios. The dataset explicitly quantifies the variants of illumination, object occlusion, object size, camera-object distance/angles, and clutter information. Rules are designed to quantify the learning capability of the robotic vision system when faced with the objects appearing in the dynamic environments in the contest. Individual reports, dataset information, rules, and released source code can be found at the project homepage: "https://lifelong-robotic-vision.github.io/competition/".