 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Attention Learning Framework for Event-Driven Object Recognition
Apr 01, 2025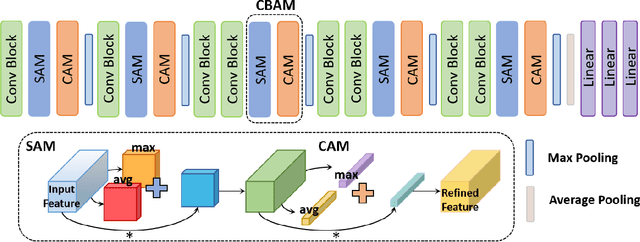
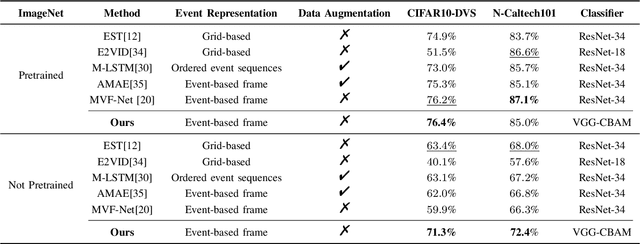
Event-based vision sensors, inspired by biological neural systems, asynchronously capture local pixel-level intensity changes as a sparse event stream containing position, polarity, and timestamp information. These neuromorphic sensors offer significant advantages in dynamic range, latency, and power efficiency. Their working principle inherently addresses traditional camera limitations such as motion blur and redundant background information, making them particularly suitable for dynamic vision tasks. While recent works have proposed increasingly complex event-based architectures, the computational overhead and parameter complexity of these approaches limit their practical deployment. This paper presents a novel spatiotemporal learning framework for event-based object recognition, utilizing a VGG network enhanced with Convolutional Block Attention Module (CBAM). Our approach achieves comparable performance to state-of-the-art ResNet-based methods while reducing parameter count by 2.3% compared to the original VGG model. Specifically, it outperforms ResNet-based methods like MVF-Net, achieving the highest Top-1 accuracy of 76.4% (pretrained) and 71.3% (not pretrained) on CIFAR10-DVS, and 72.4% (not pretrained) on N-Caltech101. These results highlight the robustness of our method when pretrained weights are not used, making it suitable for scenarios where transfer learning is unavailable. Moreover, our approach reduces reliance on data augmentation. Experimental results on standard event-based datasets demonstrate the framework's efficiency and effectiveness for real-world applications.
Tracking Fast by Learning Slow: An Event-based Speed Adaptive Hand Tracker Leveraging Knowledge in RGB Domain
Feb 28, 20233D hand tracking methods based on monocular RGB videos are easily affected by motion blur, while event camera, a sensor with high temporal resolution and dynamic range, is naturally suitable for this task with sparse output and low power consumption. However, obtaining 3D annotations of fast-moving hands is difficult for constructing event-based hand-tracking datasets. In this paper, we provided an event-based speed adaptive hand tracker (ESAHT) to solve the hand tracking problem based on event camera. We enabled a CNN model trained on a hand tracking dataset with slow motion, which enabled the model to leverage the knowledge of RGB-based hand tracking solutions, to work on fast hand tracking tasks. To realize our solution, we constructed the first 3D hand tracking dataset captured by an event camera in a real-world environment, figured out two data augment methods to narrow the domain gap between slow and fast motion data, developed a speed adaptive event stream segmentation method to handle hand movements in different moving speeds, and introduced a new event-to-frame representation method adaptive to event streams with different lengths. Experiments showed that our solution outperformed RGB-based as well as previous event-based solutions in fast hand tracking tasks, and our codes and dataset will be publicly available.
Multi-modal estimation of the properties of containers and their content: survey and evaluation
Jul 27, 2021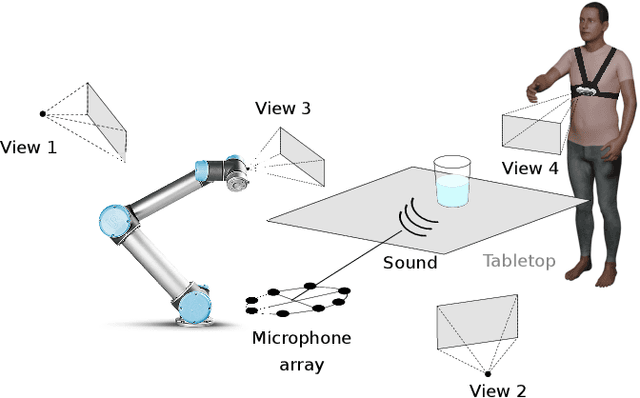


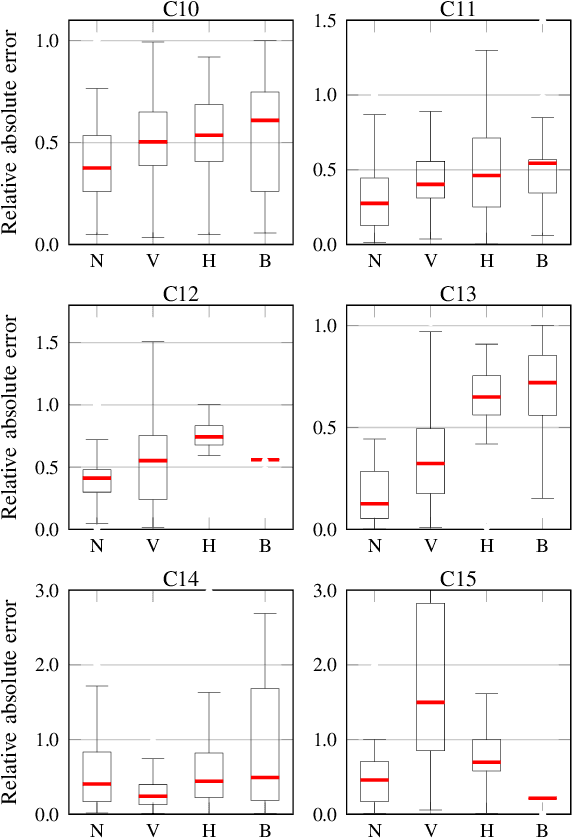
Acoustic and visual sensing can support the contactless estimation of the weight of a container and the amount of its content when the container is manipulated by a person. However, transparencies (both of the container and of the content) and the variability of materials, shapes and sizes make this problem challenging. In this paper, we present an open benchmarking framework and an in-depth comparative analysis of recent methods that estimate the capacity of a container, as well as the type, mass, and amount of its content. These methods use learned and handcrafted features, such as mel-frequency cepstrum coefficients, zero-crossing rate, spectrograms, with different types of classifiers to estimate the type and amount of the content with acoustic data, and geometric approaches with visual data to determine the capacity of the container. Results on a newly distributed dataset show that audio alone is a strong modality and methods achieves a weighted average F1-score up to 81% and 97% for content type and level classification, respectively. Estimating the container capacity with vision-only approaches and filling mass with multi-modal, multi-stage algorithms reaches up to 65% weighted average capacity and mass scores.
IROS 2019 Lifelong Robotic Vision Challenge -- Lifelong Object Recognition Report
Apr 26, 2020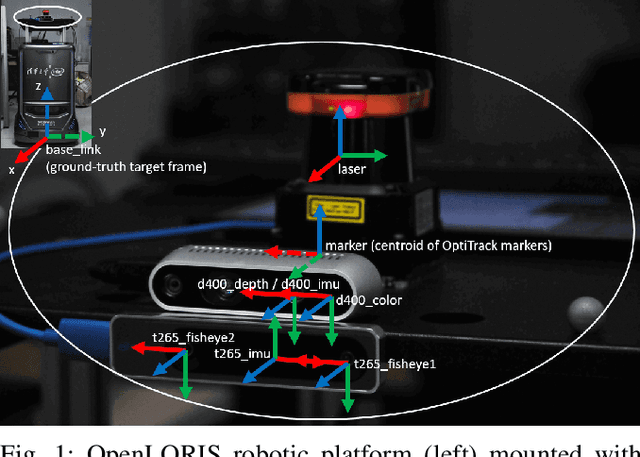
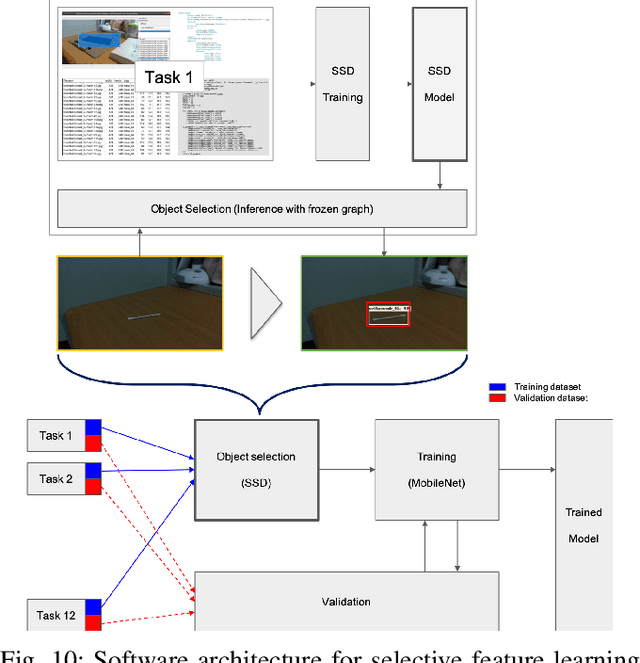
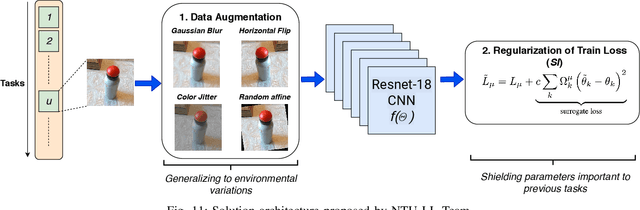

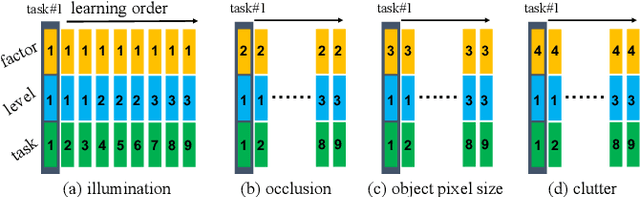
This report summarizes IROS 2019-Lifelong Robotic Vision Competition (Lifelong Object Recognition Challenge) with methods and results from the top $8$ finalists (out of over~$150$ teams). The competition dataset (L)ifel(O)ng (R)obotic V(IS)ion (OpenLORIS) - Object Recognition (OpenLORIS-object) is designed for driving lifelong/continual learning research and application in robotic vision domain, with everyday objects in home, office, campus, and mall scenarios. The dataset explicitly quantifies the variants of illumination, object occlusion, object size, camera-object distance/angles, and clutter information. Rules are designed to quantify the learning capability of the robotic vision system when faced with the objects appearing in the dynamic environments in the contest. Individual reports, dataset information, rules, and released source code can be found at the project homepage: "https://lifelong-robotic-vision.github.io/competition/".
OpenLORIS-Object: A Dataset and Benchmark towards Lifelong Object Recognition
Nov 15, 2019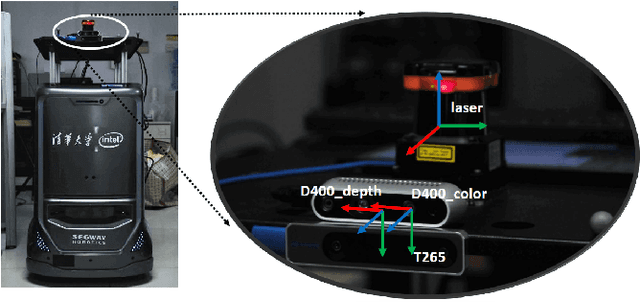


The recent breakthroughs in computer vision have benefited from the availability of large representative datasets (e.g. ImageNet and COCO) for training. Yet, robotic vision poses unique challenges for applying visual algorithms developed from these standard computer vision datasets due to their implicit assumption over non-varying distributions for a fixed set of tasks. Fully retraining models each time a new task becomes available is infeasible due to computational, storage and sometimes privacy issues, while na\"{i}ve incremental strategies have been shown to suffer from catastrophic forgetting. It is crucial for the robots to operate continuously under open-set and detrimental conditions with adaptive visual perceptual systems, where lifelong learning is a fundamental capability. However, very few datasets and benchmarks are available to evaluate and compare emerging techniques. To fill this gap, we provide a new lifelong robotic vision dataset ("OpenLORIS-Object") collected via RGB-D cameras mounted on mobile robots. The dataset embeds the challenges faced by a robot in the real-life application and provides new benchmarks for validating lifelong object recognition algorithms. Moreover, we have provided a testbed of $9$ state-of-the-art lifelong learning algorithms. Each of them involves $48$ tasks with $4$ evaluation metrics over the OpenLORIS-Object dataset. The results demonstrate that the object recognition task in the ever-changing difficulty environments is far from being solved and the bottlenecks are at the forward/backward transfer designs. Our dataset and benchmark are publicly available at \href{https://lifelong-robotic-vision.github.io/dataset/Data_Object-Recognition.html}{\underline{this url}}.
Are We Ready for Service Robots? The OpenLORIS-Scene Datasets for Lifelong SLAM
Nov 13, 2019
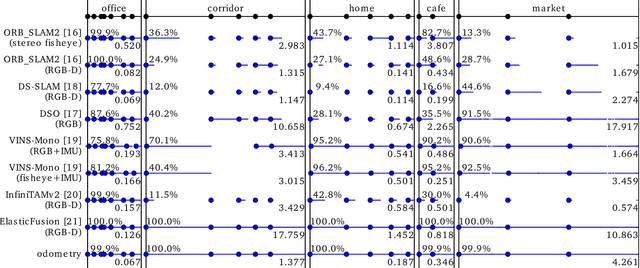
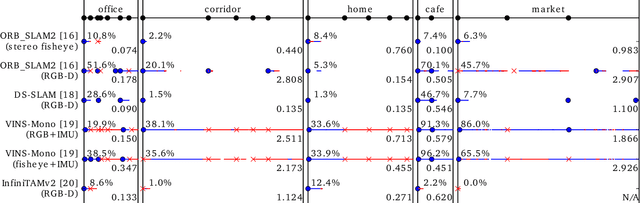
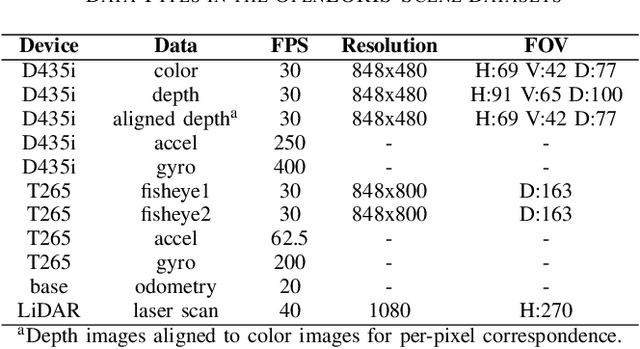
Service robots should be able to operate autonomously in dynamic and daily changing environments over an extended period of time. While Simultaneous Localization And Mapping (SLAM) is one of the most fundamental problems for robotic autonomy, most existing SLAM works are evaluated with data sequences that are recorded in a short period of time. In real-world deployment, there can be out-of-sight scene changes caused by both natural factors and human activities. For example, in home scenarios, most objects may be movable, replaceable or deformable, and the visual features of the same place may be significantly different in some successive days. Such out-of-sight dynamics pose great challenges to the robustness of pose estimation, and hence a robot's long-term deployment and operation. To differentiate the forementioned problem from the conventional works which are usually evaluated in a static setting in a single run, the term lifelong SLAM is used here to address SLAM problems in an ever-changing environment over a long period of time. To accelerate lifelong SLAM research, we release the OpenLORIS-Scene datasets. The data are collected in real-world indoor scenes, for multiple times in each place to include scene changes in real life. We also design benchmarking metrics for lifelong SLAM, with which the robustness and accuracy of pose estimation are evaluated separately. The datasets and benchmark are available online at https://lifelong-robotic-vision.github.io/dataset/scene.
Network Modeling of Short Over-Dispersed Spike-Counts: A Hierarchical Parametric Empirical Bayes Framework
May 28, 2018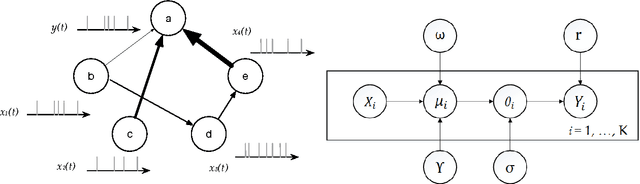

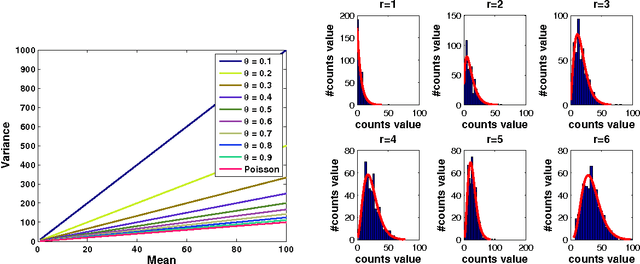
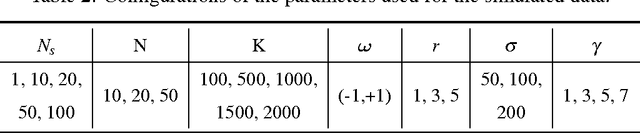
Accurate statistical models of neural spike responses can characterize the information carried by neural populations. Yet, challenges in recording at the level of individual neurons commonly results in relatively limited samples of spike counts, which can lead to model overfitting. Moreover, current models assume spike counts to be Poisson-distributed, which ignores the fact that many neurons demonstrate over-dispersed spiking behavior. The Negative Binomial Generalized Linear Model (NB-GLM) provides a powerful tool for modeling over-dispersed spike counts. However, maximum likelihood based standard NB-GLM leads to unstable and inaccurate parameter estimations. Thus, we propose a hierarchical parametric empirical Bayes method for estimating the parameters of the NB-GLM. Our method integrates Generalized Linear Models (GLMs) and empirical Bayes theory to: (1) effectively capture over-dispersion nature of spike counts from retinal ganglion neural responses; (2) significantly reduce mean square error of parameter estimations when compared to maximum likelihood based method for NB-GLMs; (3) provide an efficient alternative to fully Bayesian inference with low computational cost for hierarchical models; and (4) give insightful findings on both neural interactions and spiking behaviors of real retina cells. We apply our approach to study both simulated data and experimental neural data from the retina. The simulation results indicate the new framework can efficiently and accurately retrieve the weights of functional connections among neural populations and predict mean spike counts. The results from the retinal datasets demonstrate the proposed method outperforms both standard Poisson and Negative Binomial GLMs in terms of the predictive log-likelihood of held-out data.
Mutual Information-Based Unsupervised Feature Transformation for Heterogeneous Feature Subset Selection
Mar 29, 2015Conventional mutual information (MI) based feature selection (FS) methods are unable to handle heterogeneous feature subset selection properly because of data format differences or estimation methods of MI between feature subset and class label. A way to solve this problem is feature transformation (FT). In this study, a novel unsupervised feature transformation (UFT) which can transform non-numerical features into numerical features is developed and tested. The UFT process is MI-based and independent of class label. MI-based FS algorithms, such as Parzen window feature selector (PWFS), minimum redundancy maximum relevance feature selection (mRMR), and normalized MI feature selection (NMIFS), can all adopt UFT for pre-processing of non-numerical features. Unlike traditional FT methods, the proposed UFT is unbiased while PWFS is utilized to its full advantage. Simulations and analyses of large-scale datasets showed that feature subset selected by the integrated method, UFT-PWFS, outperformed other FT-FS integrated methods in classification accuracy.