 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaP-Net: A Region-wise and Point-wise Weighting Network to Extract Robust Keypoints for Indoor Localization
Dec 01, 2020

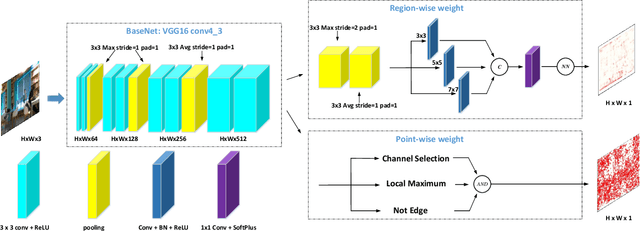
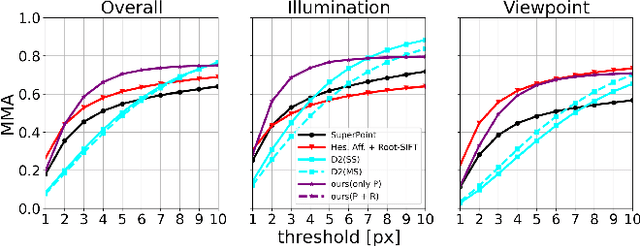
Image keypoint extraction is an important step for visual localization. The localization in indoor environment is challenging for that there may be many unreliable features on dynamic or repetitive objects. Such kind of reliability cannot be well learned by existing Convolutional Neural Network (CNN) based feature extractors. We propose a novel network, RaP-Net, which explicitly addresses feature invariability with a region-wise predictor, and combines it with a point-wise predictor to select reliable keypoints in an image. We also build a new dataset, OpenLORIS-Location, to train this network. The dataset contains 1553 indoor images with location labels. There are various scene changes between images on the same location, which can help a network to learn the invariability in typical indoor scenes. Experimental results show that the proposed RaP-Net trained with the OpenLORIS-Location dataset significantly outperforms existing CNN-based keypoint extraction algorithms for indoor localization. The code and data are available at https://github.com/ivipsourcecode/RaP-Net.
DXSLAM: A Robust and Efficient Visual SLAM System with Deep Features
Aug 12, 2020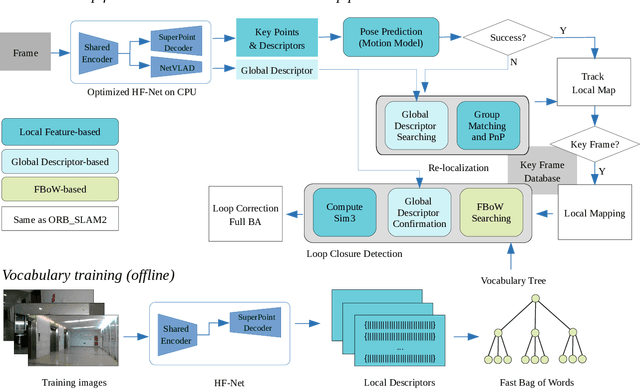
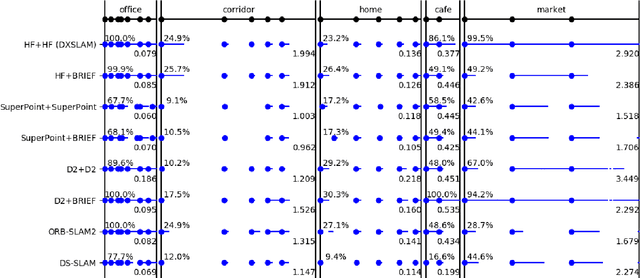

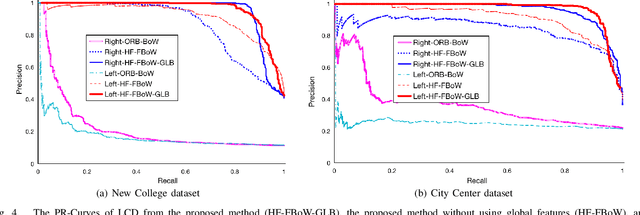
A robust and efficient Simultaneous Localization and Mapping (SLAM) system is essential for robot autonomy. For visual SLAM algorithms, though the theoretical framework has been well established for most aspects, feature extraction and association is still empirically designed in most cases, and can be vulnerable in complex environments. This paper shows that feature extraction with deep convolutional neural networks (CNNs) can be seamlessly incorporated into a modern SLAM framework. The proposed SLAM system utilizes a state-of-the-art CNN to detect keypoints in each image frame, and to give not only keypoint descriptors, but also a global descriptor of the whole image. These local and global features are then used by different SLAM modules, resulting in much more robustness against environmental changes and viewpoint changes compared with using hand-crafted features. We also train a visual vocabulary of local features with a Bag of Words (BoW) method. Based on the local features, global features, and the vocabulary, a highly reliable loop closure detection method is built. Experimental results show that all the proposed modules significantly outperforms the baseline, and the full system achieves much lower trajectory errors and much higher correct rates on all evaluated data. Furthermore, by optimizing the CNN with Intel OpenVINO toolkit and utilizing the Fast BoW library, the system benefits greatly from the SIMD (single-instruction-multiple-data) techniques in modern CPUs. The full system can run in real-time without any GPU or other accelerators. The code is public at https://github.com/ivipsourcecode/dxslam.
Are We Ready for Service Robots? The OpenLORIS-Scene Datasets for Lifelong SLAM
Nov 13, 2019
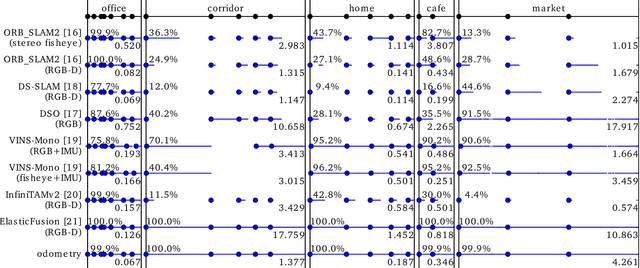
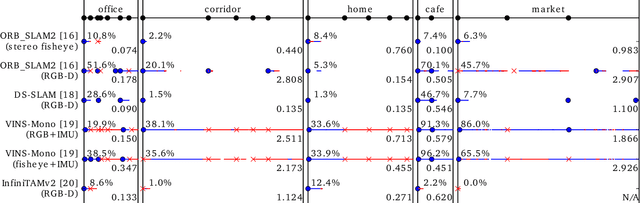
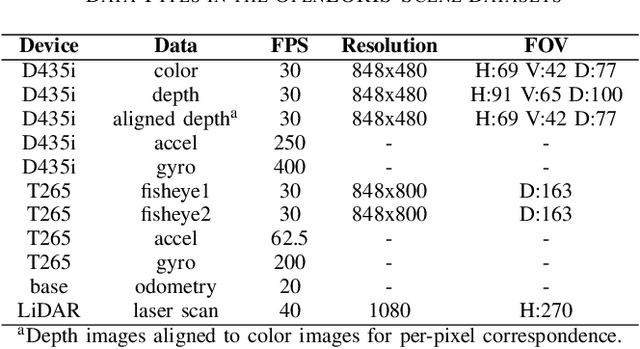
Service robots should be able to operate autonomously in dynamic and daily changing environments over an extended period of time. While Simultaneous Localization And Mapping (SLAM) is one of the most fundamental problems for robotic autonomy, most existing SLAM works are evaluated with data sequences that are recorded in a short period of time. In real-world deployment, there can be out-of-sight scene changes caused by both natural factors and human activities. For example, in home scenarios, most objects may be movable, replaceable or deformable, and the visual features of the same place may be significantly different in some successive days. Such out-of-sight dynamics pose great challenges to the robustness of pose estimation, and hence a robot's long-term deployment and operation. To differentiate the forementioned problem from the conventional works which are usually evaluated in a static setting in a single run, the term lifelong SLAM is used here to address SLAM problems in an ever-changing environment over a long period of time. To accelerate lifelong SLAM research, we release the OpenLORIS-Scene datasets. The data are collected in real-world indoor scenes, for multiple times in each place to include scene changes in real life. We also design benchmarking metrics for lifelong SLAM, with which the robustness and accuracy of pose estimation are evaluated separately. The datasets and benchmark are available online at https://lifelong-robotic-vision.github.io/dataset/scene.