 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-temporal Hierarchical Reinforcement Learning for Interpretable Pathology Image Super-Resolution
Jun 26, 2024



Pathology image are essential for accurately interpreting lesion cells in cytopathology screening, but acquiring high-resolution digital slides requires specialized equipment and long scanning times. Though super-resolution (SR) techniques can alleviate this problem, existing deep learning models recover pathology image in a black-box manner, which can lead to untruthful biological details and misdiagnosis. Additionally, current methods allocate the same computational resources to recover each pixel of pathology image, leading to the sub-optimal recovery issue due to the large variation of pathology image. In this paper, we propose the first hierarchical reinforcement learning framework named Spatial-Temporal hierARchical Reinforcement Learning (STAR-RL), mainly for addressing the aforementioned issues in pathology image super-resolution problem. We reformulate the SR problem as a Markov decision process of interpretable operations and adopt the hierarchical recovery mechanism in patch level, to avoid sub-optimal recovery. Specifically, the higher-level spatial manager is proposed to pick out the most corrupted patch for the lower-level patch worker. Moreover, the higher-level temporal manager is advanced to evaluate the selected patch and determine whether the optimization should be stopped earlier, thereby avoiding the over-processed problem. Under the guidance of spatial-temporal managers, the lower-level patch worker processes the selected patch with pixel-wise interpretable actions at each time step. Experimental results on medical images degraded by different kernels show the effectiveness of STAR-RL. Furthermore, STAR-RL validates the promotion in tumor diagnosis with a large margin and shows generalizability under various degradations. The source code is available at https://github.com/CUHK-AIM-Group/STAR-RL.
Collaborative Residual Metric Learning
Apr 17, 2023



In collaborative filtering, distance metric learning has been applied to matrix factorization techniques with promising results. However, matrix factorization lacks the ability of capturing collaborative information, which has been remarked by recent works and improved by interpreting user interactions as signals. This paper aims to find out how metric learning connect to these signal-based models. By adopting a generalized distance metric, we discovered that in signal-based models, it is easier to estimate the residual of distances, which refers to the difference between the distances from a user to a target item and another item, rather than estimating the distances themselves. Further analysis also uncovers a link between the normalization strength of interaction signals and the novelty of recommendation, which has been overlooked by existing studies. Based on the above findings, we propose a novel model to learn a generalized distance user-item distance metric to capture user preference in interaction signals by modeling the residuals of distance. The proposed CoRML model is then further improved in training efficiency by a newly introduced approximated ranking weight. Extensive experiments conducted on 4 public datasets demonstrate the superior performance of CoRML compared to the state-of-the-art baselines in collaborative filtering, along with high efficiency and the ability of providing novelty-promoted recommendations, shedding new light on the study of metric learning-based recommender systems.
Modeling sequential annotations for sequence labeling with crowds
Sep 20, 2022
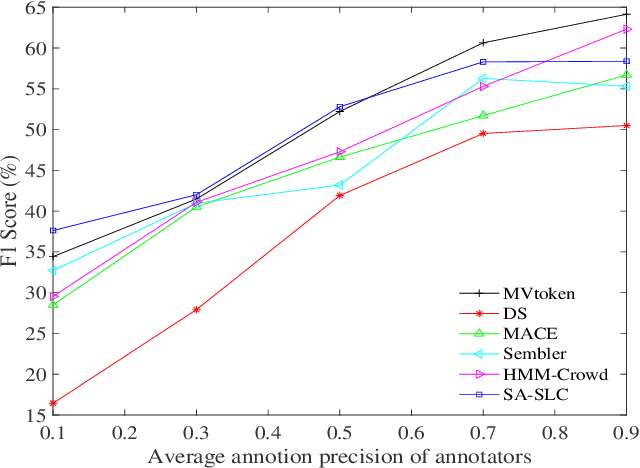
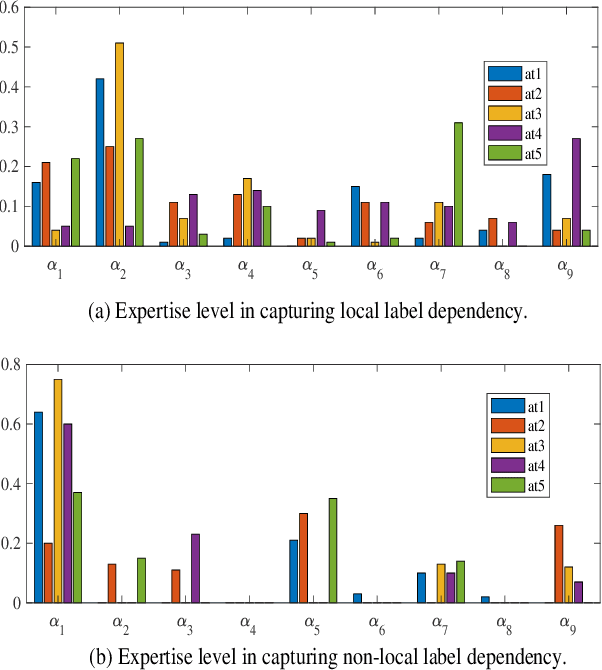
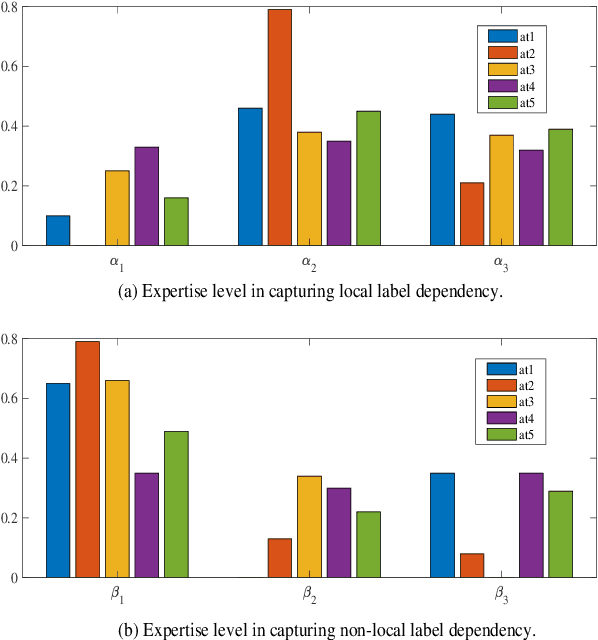
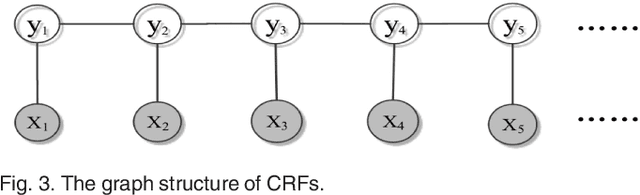
Crowd sequential annotations can be an efficient and cost-effective way to build large datasets for sequence labeling. Different from tagging independent instances, for crowd sequential annotations the quality of label sequence relies on the expertise level of annotators in capturing internal dependencies for each token in the sequence. In this paper, we propose Modeling sequential annotation for sequence labeling with crowds (SA-SLC). First, a conditional probabilistic model is developed to jointly model sequential data and annotators' expertise, in which categorical distribution is introduced to estimate the reliability of each annotator in capturing local and non-local label dependency for sequential annotation. To accelerate the marginalization of the proposed model, a valid label sequence inference (VLSE) method is proposed to derive the valid ground-truth label sequences from crowd sequential annotations. VLSE derives possible ground-truth labels from the token-wise level and further prunes sub-paths in the forward inference for label sequence decoding. VLSE reduces the number of candidate label sequences and improves the quality of possible ground-truth label sequences. The experimental results on several sequence labeling tasks of Natural Language Processing show the effectiveness of the proposed model.
Weak Disambiguation for Partial Structured Output Learning
Sep 20, 2022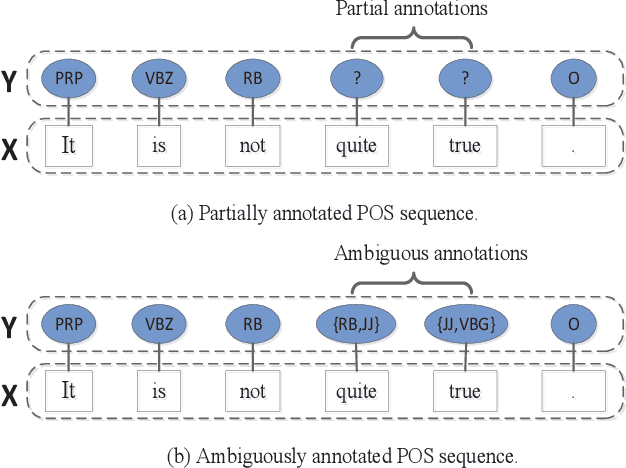
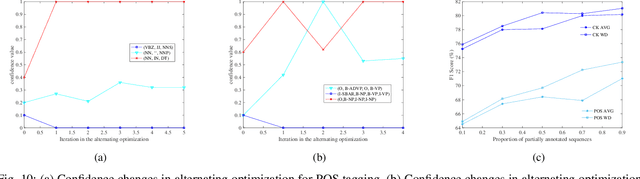

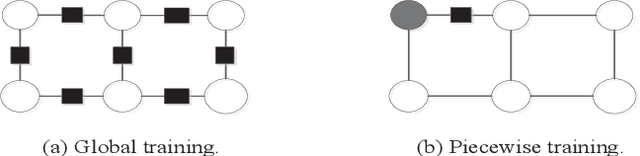
Existing disambiguation strategies for partial structured output learning just cannot generalize well to solve the problem that there are some candidates which can be false positive or similar to the ground-truth label. In this paper, we propose a novel weak disambiguation for partial structured output learning (WD-PSL). First, a piecewise large margin formulation is generalized to partial structured output learning, which effectively avoids handling large number of candidate structured outputs for complex structures. Second, in the proposed weak disambiguation strategy, each candidate label is assigned with a confidence value indicating how likely it is the true label, which aims to reduce the negative effects of wrong ground-truth label assignment in the learning process. Then two large margins are formulated to combine two types of constraints which are the disambiguation between candidates and non-candidates, and the weak disambiguation for candidates. In the framework of alternating optimization, a new 2n-slack variables cutting plane algorithm is developed to accelerate each iteration of optimization. The experimental results on several sequence labeling tasks of Natural Language Processing show the effectiveness of the proposed model.
Partial sequence labeling with structured Gaussian Processes
Sep 20, 2022

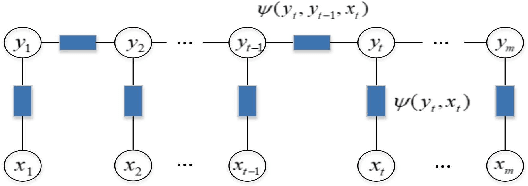
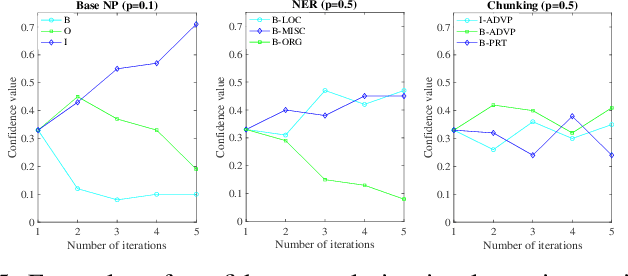
Existing partial sequence labeling models mainly focus on max-margin framework which fails to provide an uncertainty estimation of the prediction. Further, the unique ground truth disambiguation strategy employed by these models may include wrong label information for parameter learning. In this paper, we propose structured Gaussian Processes for partial sequence labeling (SGPPSL), which encodes uncertainty in the prediction and does not need extra effort for model selection and hyperparameter learning. The model employs factor-as-piece approximation that divides the linear-chain graph structure into the set of pieces, which preserves the basic Markov Random Field structure and effectively avoids handling large number of candidate output sequences generated by partially annotated data. Then confidence measure is introduced in the model to address different contributions of candidate labels, which enables the ground-truth label information to be utilized in parameter learning. Based on the derived lower bound of the variational lower bound of the proposed model, variational parameters and confidence measures are estimated in the framework of alternating optimization. Moreover, weighted Viterbi algorithm is proposed to incorporate confidence measure to sequence prediction, which considers label ambiguity arose from multiple annotations in the training data and thus helps improve the performance. SGPPSL is evaluated on several sequence labeling tasks and the experimental results show the effectiveness of the proposed model.
Duration modeling with semi-Markov Conditional Random Fields for keyphrase extraction
Sep 19, 2022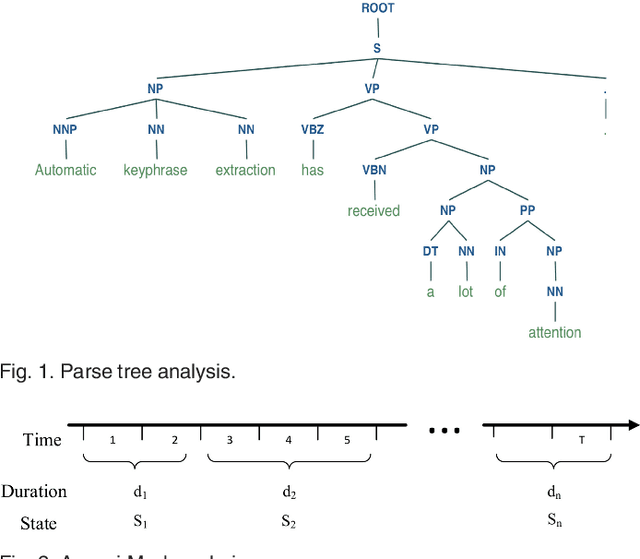


Existing methods for keyphrase extraction need preprocessing to generate candidate phrase or post-processing to transform keyword into keyphrase. In this paper, we propose a novel approach called duration modeling with semi-Markov Conditional Random Fields (DM-SMCRFs) for keyphrase extraction. First of all, based on the property of semi-Markov chain, DM-SMCRFs can encode segment-level features and sequentially classify the phrase in the sentence as keyphrase or non-keyphrase. Second, by assuming the independence between state transition and state duration, DM-SMCRFs model the distribution of duration (length) of keyphrases to further explore state duration information, which can help identify the size of keyphrase. Based on the convexity of parametric duration feature derived from duration distribution, a constrained Viterbi algorithm is derived to improve the performance of decoding in DM-SMCRFs. We thoroughly evaluate the performance of DM-SMCRFs on the datasets from various domains. The experimental results demonstrate the effectiveness of proposed model.
Efficient and Scalable Recommendation via Item-Item Graph Partitioning
Jul 13, 2022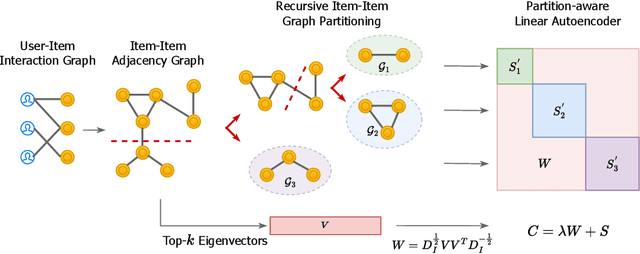
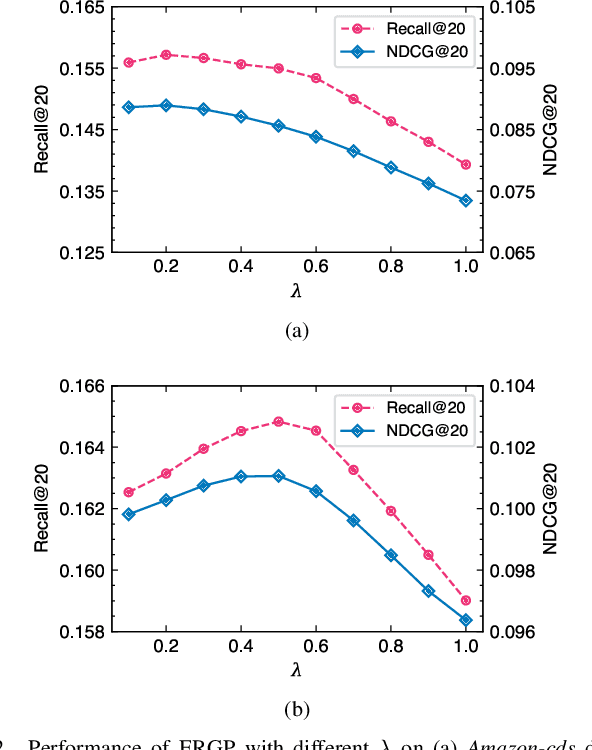
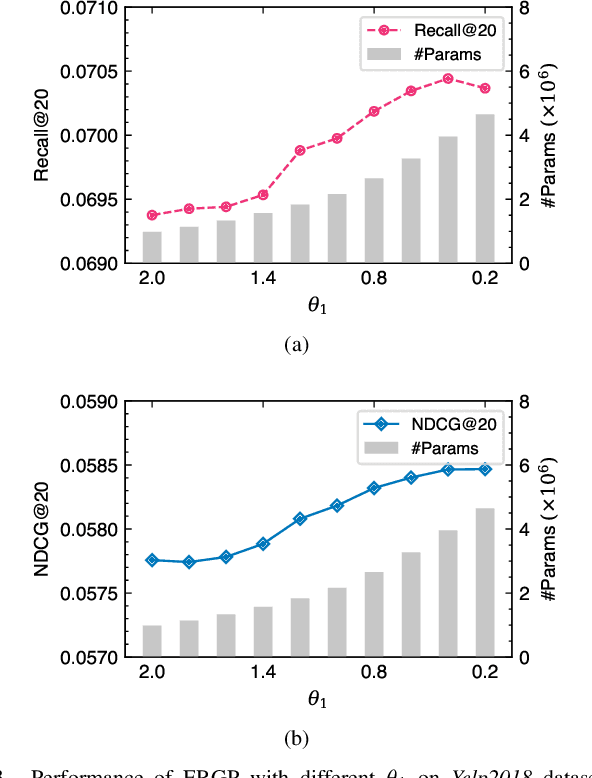
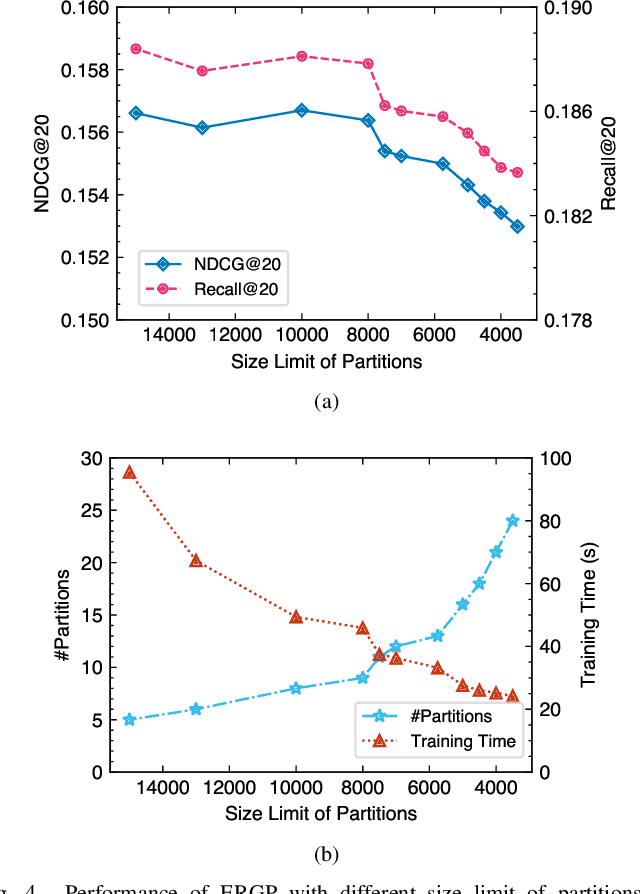
Collaborative filtering (CF) is a widely searched problem in recommender systems. Linear autoencoder is a kind of well-established method for CF, which estimates item-item relations through encoding user-item interactions. Despite the excellent performance of linear autoencoders, the rapidly increasing computational and storage costs caused by the growing number of items limit their scalabilities in large-scale real-world scenarios. Recently, graph-based approaches have achieved success on CF with high scalability, and have been shown to have commonalities with linear autoencoders in user-item interaction modeling. Motivated by this, we propose an efficient and scalable recommendation via item-item graph partitioning (ERGP), aiming to address the limitations of linear autoencoders. In particular, a recursive graph partitioning strategy is proposed to ensure that the item set is divided into several partitions of finite size. Linear autoencoders encode user-item interactions within partitions while preserving global information across the entire item set. This allows ERGP to have guaranteed efficiency and high scalability when the number of items increases. Experiments conducted on 3 public datasets and 3 open benchmarking datasets demonstrate the effectiveness of ERGP, which outperforms state-of-the-art models with lower training time and storage costs.
Learning with fuzzy hypergraphs: a topical approach to query-oriented text summarization
Jun 22, 2019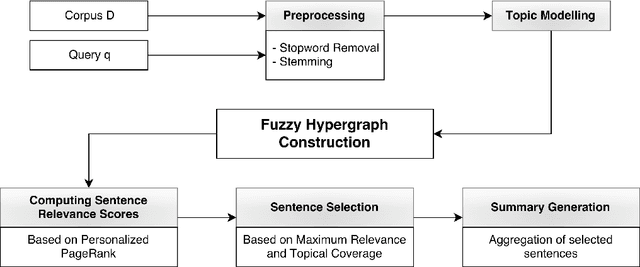
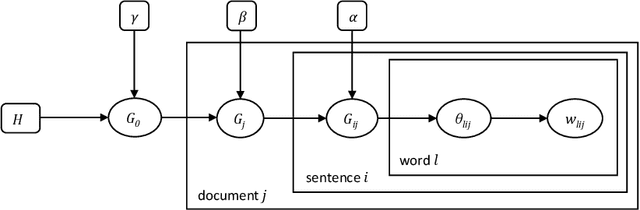

Existing graph-based methods for extractive document summarization represent sentences of a corpus as the nodes of a graph or a hypergraph in which edges depict relationships of lexical similarity between sentences. Such approaches fail to capture semantic similarities between sentences when they express a similar information but have few words in common and are thus lexically dissimilar. To overcome this issue, we propose to extract semantic similarities based on topical representations of sentences. Inspired by the Hierarchical Dirichlet Process, we propose a probabilistic topic model in order to infer topic distributions of sentences. As each topic defines a semantic connection among a group of sentences with a certain degree of membership for each sentence, we propose a fuzzy hypergraph model in which nodes are sentences and fuzzy hyperedges are topics. To produce an informative summary, we extract a set of sentences from the corpus by simultaneously maximizing their relevance to a user-defined query, their centrality in the fuzzy hypergraph and their coverage of topics present in the corpus. We formulate a polynomial time algorithm building on the theory of submodular functions to solve the associated optimization problem. A thorough comparative analysis with other graph-based summarization systems is included in the paper. Our obtained results show the superiority of our method in terms of content coverage of the summaries.
* 8 figures
Query-oriented text summarization based on hypergraph transversals
Feb 02, 2019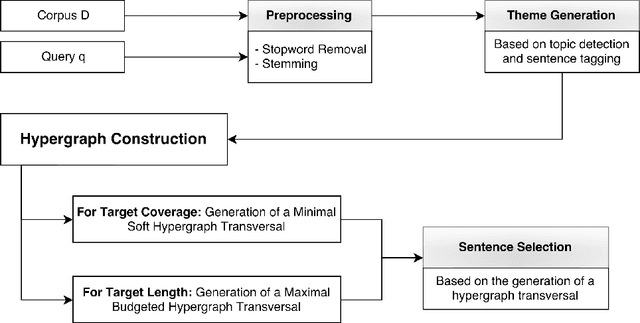

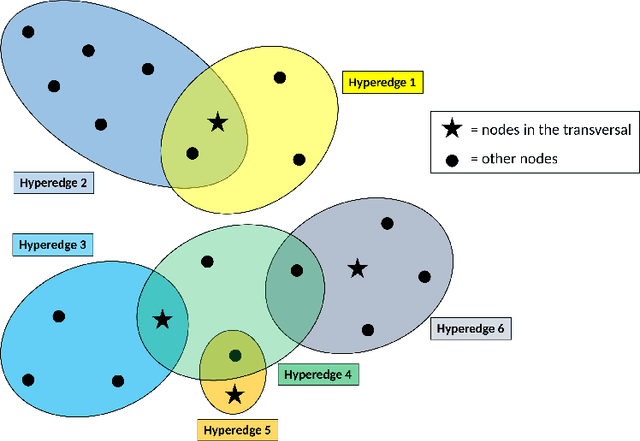

Existing graph- and hypergraph-based algorithms for document summarization represent the sentences of a corpus as the nodes of a graph or a hypergraph in which the edges represent relationships of lexical similarities between sentences. Each sentence of the corpus is then scored individually, using popular node ranking algorithms, and a summary is produced by extracting highly scored sentences. This approach fails to select a subset of jointly relevant sentences and it may produce redundant summaries that are missing important topics of the corpus. To alleviate this issue, a new hypergraph-based summarizer is proposed in this paper, in which each node is a sentence and each hyperedge is a theme, namely a group of sentences sharing a topic. Themes are weighted in terms of their prominence in the corpus and their relevance to a user-defined query. It is further shown that the problem of identifying a subset of sentences covering the relevant themes of the corpus is equivalent to that of finding a hypergraph transversal in our theme-based hypergraph. Two extensions of the notion of hypergraph transversal are proposed for the purpose of summarization, and polynomial time algorithms building on the theory of submodular functions are proposed for solving the associated discrete optimization problems. The worst-case time complexity of the proposed algorithms is squared in the number of terms, which makes it cheaper than the existing hypergraph-based methods. A thorough comparative analysis with related models on DUC benchmark datasets demonstrates the effectiveness of our approach, which outperforms existing graph- or hypergraph-based methods by at least 6% of ROUGE-SU4 score.
Exactly Robust Kernel Principal Component Analysis
Feb 28, 2018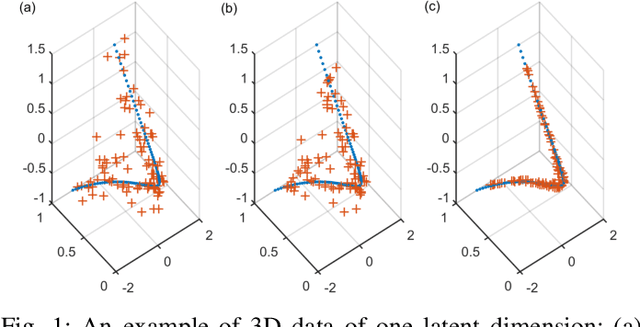
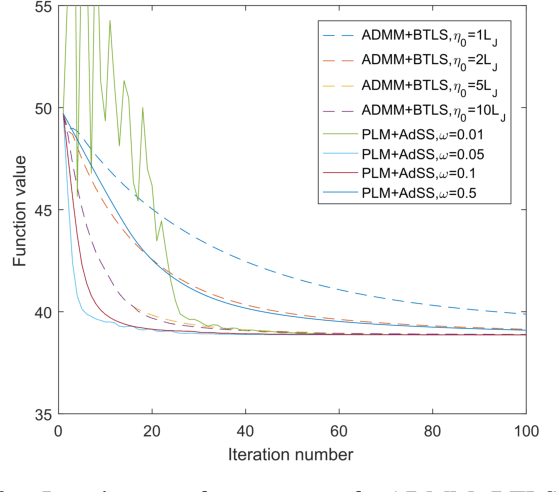


We propose a novel method called robust kernel principal component analysis (RKPCA) to decompose a partially corrupted matrix as a sparse matrix plus a high or full-rank matrix whose columns are drawn from a nonlinear low-dimensional latent variable model. RKPCA can be applied to many problems such as noise removal and subspace clustering and is so far the only unsupervised nonlinear method robust to sparse noises. We also provide theoretical guarantees for RKPCA. The optimization of RKPCA is challenging because it involves nonconvex and indifferentiable problems simultaneously. We propose two nonconvex optimization algorithms for RKPCA: alternating direction method of multipliers with backtracking line search and proximal linearized minimization with adaptive step size. Comparative studies on synthetic data and nature images corroborate the effectiveness and superiority of RKPCA in noise removal and robust subspace clustering.