 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen should I search more: Adaptive Complex Query Optimization with Reinforcement Learning
Jan 29, 2026Query optimization is a crucial component for the efficacy of Retrieval-Augmented Generation (RAG) systems. While reinforcement learning (RL)-based agentic and reasoning methods have recently emerged as a promising direction on query optimization, most existing approaches focus on the expansion and abstraction of a single query. However, complex user queries are prevalent in real-world scenarios, often requiring multiple parallel and sequential search strategies to handle disambiguation and decomposition. Directly applying RL to these complex cases introduces significant hurdles. Determining the optimal number of sub-queries and effectively re-ranking and merging retrieved documents vastly expands the search space and complicates reward design, frequently leading to training instability. To address these challenges, we propose a novel RL framework called Adaptive Complex Query Optimization (ACQO). Our framework is designed to adaptively determine when and how to expand the search process. It features two core components: an Adaptive Query Reformulation (AQR) module that dynamically decides when to decompose a query into multiple sub-queries, and a Rank-Score Fusion (RSF) module that ensures robust result aggregation and provides stable reward signals for the learning agent. To mitigate training instabilities, we adopt a Curriculum Reinforcement Learning (CRL) approach, which stabilizes the training process by progressively introducing more challenging queries through a two-stage strategy. Our comprehensive experiments demonstrate that ACQO achieves state-of-the-art performance on three complex query benchmarks, significantly outperforming established baselines. The framework also showcases improved computational efficiency and broad compatibility with different retrieval architectures, establishing it as a powerful and generalizable solution for next-generation RAG systems.
Think When Needed: Model-Aware Reasoning Routing for LLM-based Ranking
Jan 26, 2026Large language models (LLMs) are increasingly applied to ranking tasks in retrieval and recommendation. Although reasoning prompting can enhance ranking utility, our preliminary exploration reveals that its benefits are inconsistent and come at a substantial computational cost, suggesting that when to reason is as crucial as how to reason. To address this issue, we propose a reasoning routing framework that employs a lightweight, plug-and-play router head to decide whether to use direct inference (Non-Think) or reasoning (Think) for each instance before generation. The router head relies solely on pre-generation signals: i) compact ranking-aware features (e.g., candidate dispersion) and ii) model-aware difficulty signals derived from a diagnostic checklist reflecting the model's estimated need for reasoning. By leveraging these features before generation, the router outputs a controllable token that determines whether to apply the Think mode. Furthermore, the router can adaptively select its operating policy along the validation Pareto frontier during deployment, enabling dynamic allocation of computational resources toward instances most likely to benefit from Think under varying system constraints. Experiments on three public ranking datasets with different scales of open-source LLMs show consistent improvements in ranking utility with reduced token consumption (e.g., +6.3\% NDCG@10 with -49.5\% tokens on MovieLens with Qwen3-4B), demonstrating reasoning routing as a practical solution to the accuracy-efficiency trade-off.
MMGRid: Navigating Temporal-aware and Cross-domain Generative Recommendation via Model Merging
Jan 22, 2026Model merging (MM) offers an efficient mechanism for integrating multiple specialized models without access to original training data or costly retraining. While MM has demonstrated success in domains like computer vision, its role in recommender systems (RSs) remains largely unexplored. Recently, Generative Recommendation (GR) has emerged as a new paradigm in RSs, characterized by rapidly growing model scales and substantial computational costs, making MM particularly appealing for cost-sensitive deployment scenarios. In this work, we present the first systematic study of MM in GR through a contextual lens. We focus on a fundamental yet underexplored challenge in real-world: how to merge generative recommenders specialized to different real-world contexts, arising from temporal evolving user behaviors and heterogeneous application domains. To this end, we propose a unified framework MMGRid, a structured contextual grid of GR checkpoints that organizes models trained under diverse contexts induced by temporal evolution and domain diversity. All checkpoints are derived from a shared base LLM but fine-tuned on context-specific data, forming a realistic and controlled model space for systematically analyzing MM across GR paradigms and merging algorithms. Our investigation reveals several key insights. First, training GR models from LLMs can introduce parameter conflicts during merging due to token distribution shifts and objective disparities; such conflicts can be alleviated by disentangling task-aware and context-specific parameter changes via base model replacement. Second, incremental training across contexts induces recency bias, which can be effectively balanced through weighted contextual merging. Notably, we observe that optimal merging weights correlate with context-dependent interaction characteristics, offering practical guidance for weight selection in real-world deployments.
Diversity Recommendation via Causal Deconfounding of Co-purchase Relations and Counterfactual Exposure
Dec 19, 2025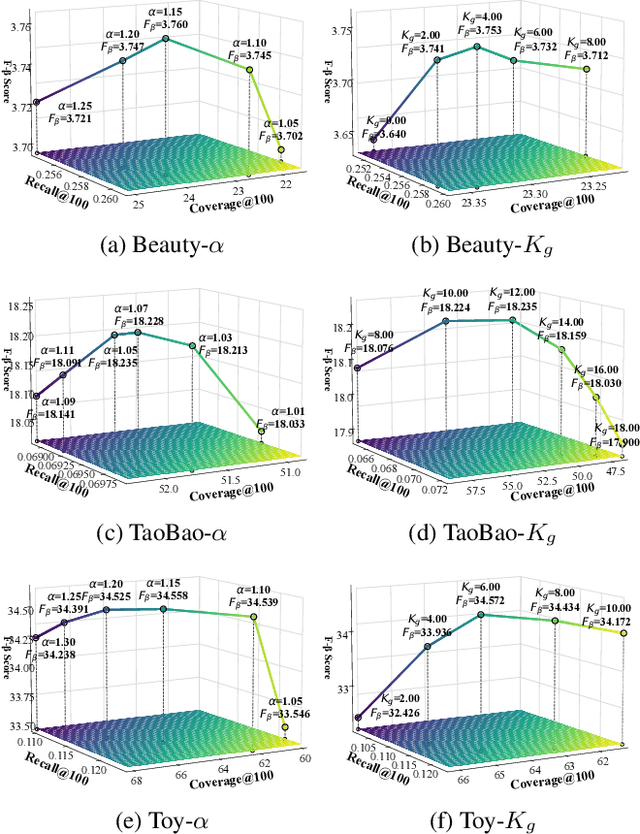

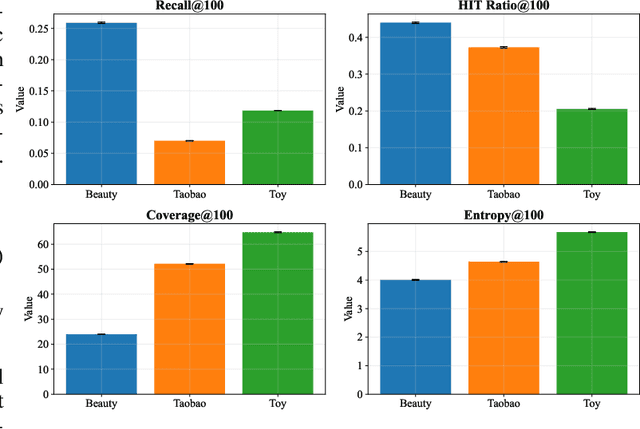
Beyond user-item modeling, item-to-item relationships are increasingly used to enhance recommendation. However, common methods largely rely on co-occurrence, making them prone to item popularity bias and user attributes, which degrades embedding quality and performance. Meanwhile, although diversity is acknowledged as a key aspect of recommendation quality, existing research offers limited attention to it, with a notable lack of causal perspectives and theoretical grounding. To address these challenges, we propose Cadence: Diversity Recommendation via Causal Deconfounding of Co-purchase Relations and Counterfactual Exposure - a plug-and-play framework built upon LightGCN as the backbone, primarily designed to enhance recommendation diversity while preserving accuracy. First, we compute the Unbiased Asymmetric Co-purchase Relationship (UACR) between items - excluding item popularity and user attributes - to construct a deconfounded directed item graph, with an aggregation mechanism to refine embeddings. Second, we leverage UACR to identify diverse categories of items that exhibit strong causal relevance to a user's interacted items but have not yet been engaged with. We then simulate their behavior under high-exposure scenarios, thereby significantly enhancing recommendation diversity while preserving relevance. Extensive experiments on real-world datasets demonstrate that our method consistently outperforms state-of-the-art diversity models in both diversity and accuracy, and further validates its effectiveness, transferability, and efficiency over baselines.
Mirroring Users: Towards Building Preference-aligned User Simulator with User Feedback in Recommendation
Aug 25, 2025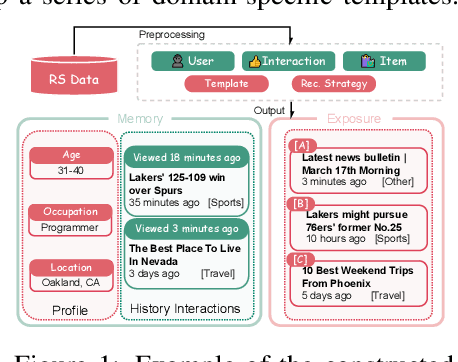
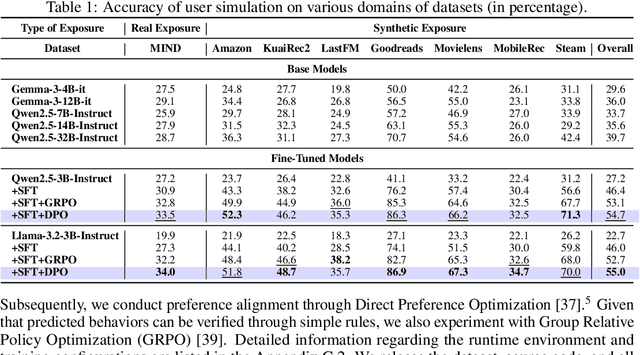
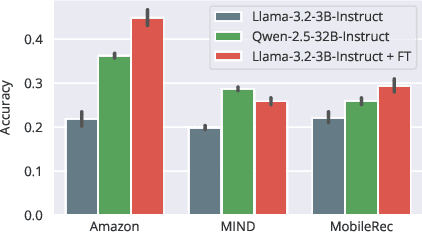
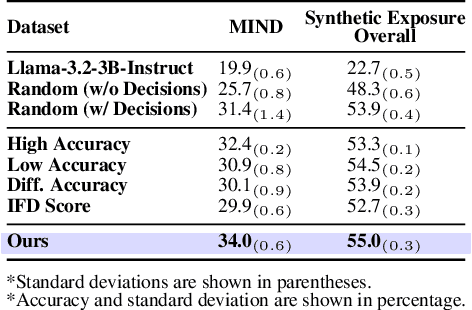
User simulation is increasingly vital to develop and evaluate recommender systems (RSs). While Large Language Models (LLMs) offer promising avenues to simulate user behavior, they often struggle with the absence of specific domain alignment required for RSs and the efficiency demands of large-scale simulation. A vast yet underutilized resource for enhancing this alignment is the extensive user feedback inherent in RSs. However, directly leveraging such feedback presents two significant challenges. First, user feedback in RSs is often ambiguous and noisy, which negatively impacts effective preference alignment. Second, the massive volume of feedback largely hinders the efficiency of preference alignment, necessitating an efficient filtering mechanism to identify more informative samples. To overcome these hurdles, we introduce a novel data construction framework that leverages user feedback in RSs with advanced LLM capabilities to generate high-quality simulation data. Our framework unfolds in two key phases: (1) employing LLMs to generate cognitive decision-making processes on constructed simulation samples, reducing ambiguity in raw user feedback; (2) data distillation based on uncertainty estimation and behavior sampling to filter challenging yet denoised simulation samples. Accordingly, we fine-tune lightweight LLMs, as user simulators, using such high-quality dataset with corresponding decision-making processes. Extensive experiments verify that our framework significantly boosts the alignment with human preferences and in-domain reasoning capabilities of fine-tuned LLMs, and provides more insightful and interpretable signals when interacting with RSs. We believe our work will advance the RS community and offer valuable insights for broader human-centric AI research.
Diagnostic-Guided Dynamic Profile Optimization for LLM-based User Simulators in Sequential Recommendation
Aug 18, 2025Recent advances in large language models (LLMs) have enabled realistic user simulators for developing and evaluating recommender systems (RSs). However, existing LLM-based simulators for RSs face two major limitations: (1) static and single-step prompt-based inference that leads to inaccurate and incomplete user profile construction; (2) unrealistic and single-round recommendation-feedback interaction pattern that fails to capture real-world scenarios. To address these limitations, we propose DGDPO (Diagnostic-Guided Dynamic Profile Optimization), a novel framework that constructs user profile through a dynamic and iterative optimization process to enhance the simulation fidelity. Specifically, DGDPO incorporates two core modules within each optimization loop: firstly, a specialized LLM-based diagnostic module, calibrated through our novel training strategy, accurately identifies specific defects in the user profile. Subsequently, a generalized LLM-based treatment module analyzes the diagnosed defect and generates targeted suggestions to refine the profile. Furthermore, unlike existing LLM-based user simulators that are limited to single-round interactions, we are the first to integrate DGDPO with sequential recommenders, enabling a bidirectional evolution where user profiles and recommendation strategies adapt to each other over multi-round interactions. Extensive experiments conducted on three real-world datasets demonstrate the effectiveness of our proposed framework.
Enhancing New-item Fairness in Dynamic Recommender Systems
Apr 30, 2025New-items play a crucial role in recommender systems (RSs) for delivering fresh and engaging user experiences. However, traditional methods struggle to effectively recommend new-items due to their short exposure time and limited interaction records, especially in dynamic recommender systems (DRSs) where new-items get continuously introduced and users' preferences evolve over time. This leads to significant unfairness towards new-items, which could accumulate over the successive model updates, ultimately compromising the stability of the entire system. Therefore, we propose FairAgent, a reinforcement learning (RL)-based new-item fairness enhancement framework specifically designed for DRSs. It leverages knowledge distillation to extract collaborative signals from traditional models, retaining strong recommendation capabilities for old-items. In addition, FairAgent introduces a novel reward mechanism for recommendation tailored to the characteristics of DRSs, which consists of three components: 1) a new-item exploration reward to promote the exposure of dynamically introduced new-items, 2) a fairness reward to adapt to users' personalized fairness requirements for new-items, and 3) an accuracy reward which leverages users' dynamic feedback to enhance recommendation accuracy. Extensive experiments on three public datasets and backbone models demonstrate the superior performance of FairAgent. The results present that FairAgent can effectively boost new-item exposure, achieve personalized new-item fairness, while maintaining high recommendation accuracy.
RocketEval: Efficient Automated LLM Evaluation via Grading Checklist
Mar 07, 2025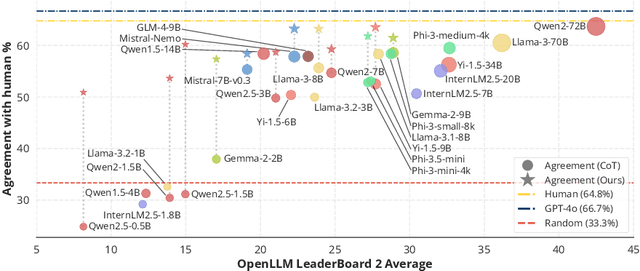
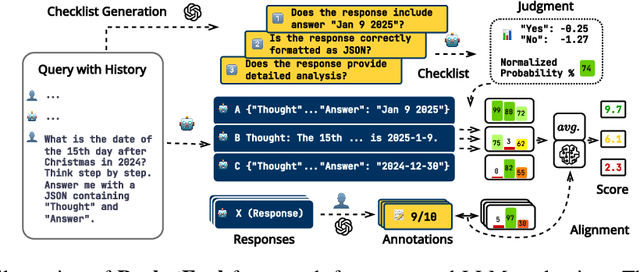
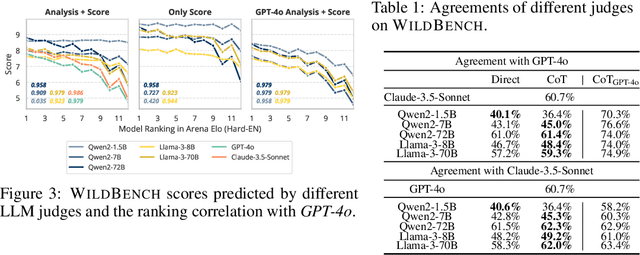
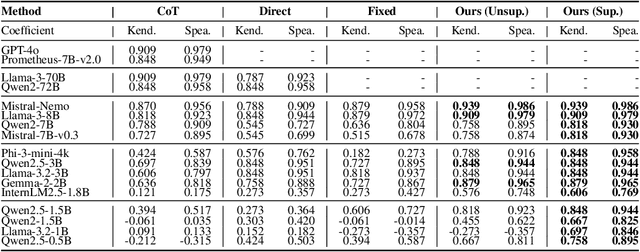
Evaluating large language models (LLMs) in diverse and challenging scenarios is essential to align them with human preferences. To mitigate the prohibitive costs associated with human evaluations, utilizing a powerful LLM as a judge has emerged as a favored approach. Nevertheless, this methodology encounters several challenges, including substantial expenses, concerns regarding privacy and security, and reproducibility. In this paper, we propose a straightforward, replicable, and accurate automated evaluation method by leveraging a lightweight LLM as the judge, named RocketEval. Initially, we identify that the performance disparity between lightweight and powerful LLMs in evaluation tasks primarily stems from their ability to conduct comprehensive analyses, which is not easily enhanced through techniques such as chain-of-thought reasoning. By reframing the evaluation task as a multi-faceted Q&A using an instance-specific checklist, we demonstrate that the limited judgment accuracy of lightweight LLMs is largely attributes to high uncertainty and positional bias. To address these challenges, we introduce an automated evaluation process grounded in checklist grading, which is designed to accommodate a variety of scenarios and questions. This process encompasses the creation of checklists, the grading of these checklists by lightweight LLMs, and the reweighting of checklist items to align with the supervised annotations. Our experiments carried out on the automated evaluation benchmarks, MT-Bench and WildBench datasets, reveal that RocketEval, when using Gemma-2-2B as the judge, achieves a high correlation (0.965) with human preferences, which is comparable to GPT-4o. Moreover, RocketEval provides a cost reduction exceeding 50-fold for large-scale evaluation and comparison scenarios. Our code is available at https://github.com/Joinn99/RocketEval-ICLR .
Collaborative Residual Metric Learning
Apr 17, 2023



In collaborative filtering, distance metric learning has been applied to matrix factorization techniques with promising results. However, matrix factorization lacks the ability of capturing collaborative information, which has been remarked by recent works and improved by interpreting user interactions as signals. This paper aims to find out how metric learning connect to these signal-based models. By adopting a generalized distance metric, we discovered that in signal-based models, it is easier to estimate the residual of distances, which refers to the difference between the distances from a user to a target item and another item, rather than estimating the distances themselves. Further analysis also uncovers a link between the normalization strength of interaction signals and the novelty of recommendation, which has been overlooked by existing studies. Based on the above findings, we propose a novel model to learn a generalized distance user-item distance metric to capture user preference in interaction signals by modeling the residuals of distance. The proposed CoRML model is then further improved in training efficiency by a newly introduced approximated ranking weight. Extensive experiments conducted on 4 public datasets demonstrate the superior performance of CoRML compared to the state-of-the-art baselines in collaborative filtering, along with high efficiency and the ability of providing novelty-promoted recommendations, shedding new light on the study of metric learning-based recommender systems.
Efficient and Scalable Recommendation via Item-Item Graph Partitioning
Jul 13, 2022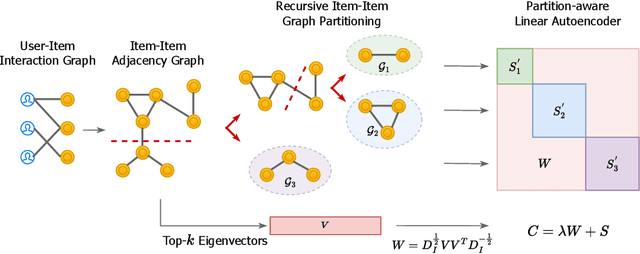
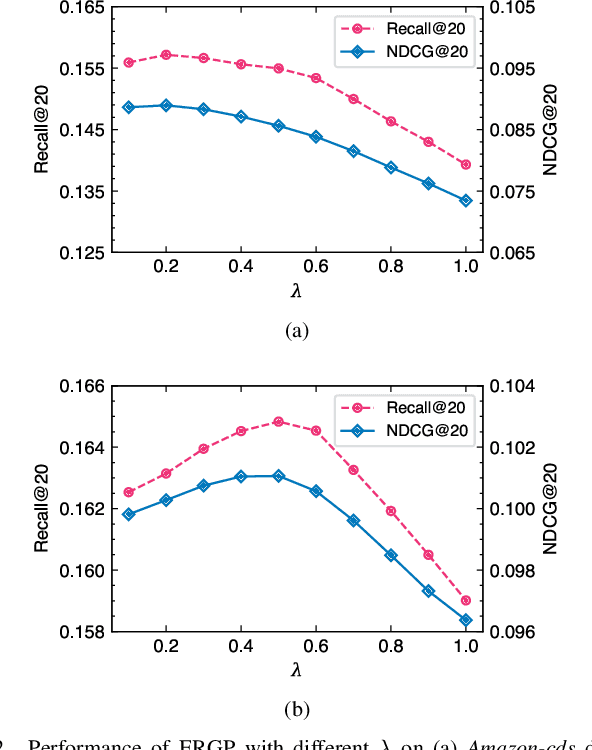
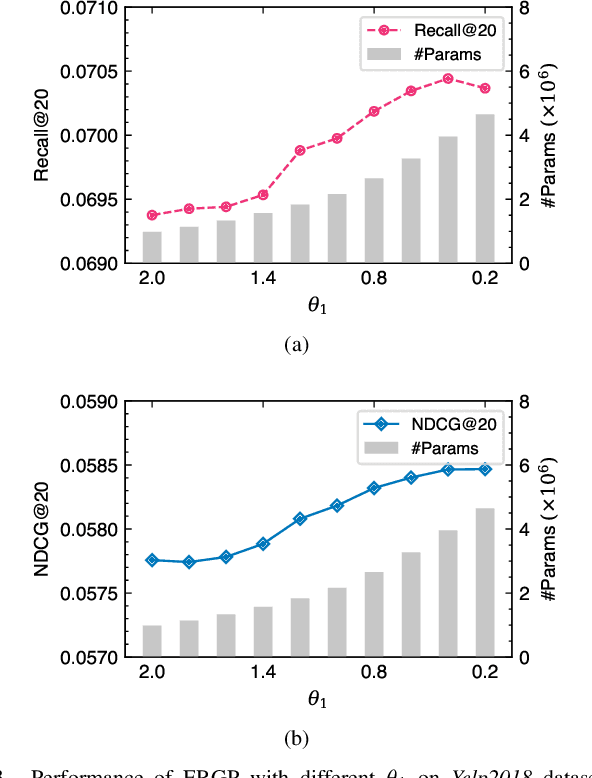
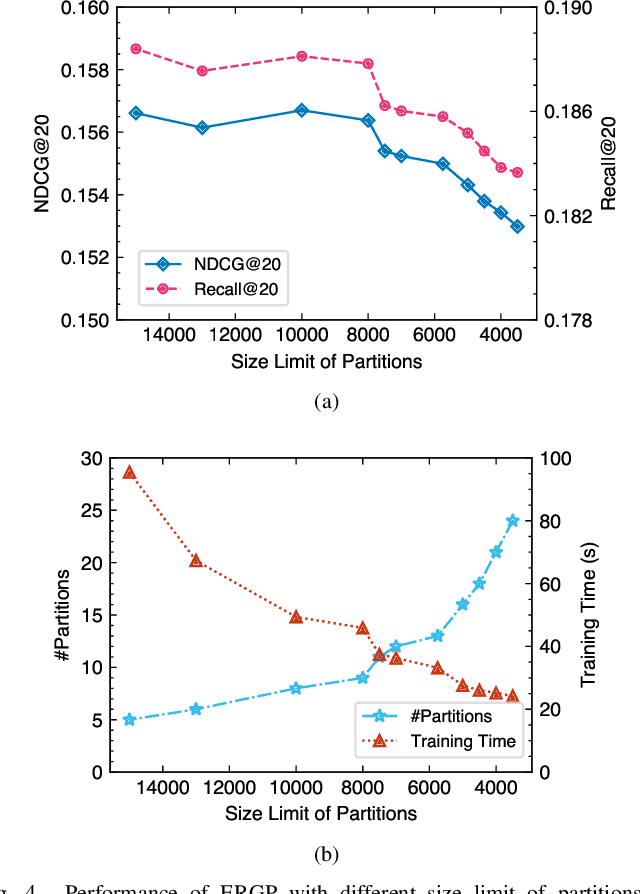
Collaborative filtering (CF) is a widely searched problem in recommender systems. Linear autoencoder is a kind of well-established method for CF, which estimates item-item relations through encoding user-item interactions. Despite the excellent performance of linear autoencoders, the rapidly increasing computational and storage costs caused by the growing number of items limit their scalabilities in large-scale real-world scenarios. Recently, graph-based approaches have achieved success on CF with high scalability, and have been shown to have commonalities with linear autoencoders in user-item interaction modeling. Motivated by this, we propose an efficient and scalable recommendation via item-item graph partitioning (ERGP), aiming to address the limitations of linear autoencoders. In particular, a recursive graph partitioning strategy is proposed to ensure that the item set is divided into several partitions of finite size. Linear autoencoders encode user-item interactions within partitions while preserving global information across the entire item set. This allows ERGP to have guaranteed efficiency and high scalability when the number of items increases. Experiments conducted on 3 public datasets and 3 open benchmarking datasets demonstrate the effectiveness of ERGP, which outperforms state-of-the-art models with lower training time and storage costs.