 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Fake News Detection on Unseen Domains via LLM-Based Domain-Aware User Modeling
Feb 02, 2026Cross-domain fake news detection (CD-FND) transfers knowledge from a source domain to a target domain and is crucial for real-world fake news mitigation. This task becomes particularly important yet more challenging when the target domain is previously unseen (e.g., the COVID-19 outbreak or the Russia-Ukraine war). However, existing CD-FND methods overlook such scenarios and consequently suffer from the following two key limitations: (1) insufficient modeling of high-level semantics in news and user engagements; and (2) scarcity of labeled data in unseen domains. Targeting these limitations, we find that large language models (LLMs) offer strong potential for CD-FND on unseen domains, yet their effective use remains non-trivial. Nevertheless, two key challenges arise: (1) how to capture high-level semantics from both news content and user engagements using LLMs; and (2) how to make LLM-generated features more reliable and transferable for CD-FND on unseen domains. To tackle these challenges, we propose DAUD, a novel LLM-Based Domain-Aware framework for fake news detection on Unseen Domains. DAUD employs LLMs to extract high-level semantics from news content. It models users' single- and cross-domain engagements to generate domain-aware behavioral representations. In addition, DAUD captures the relations between original data-driven features and LLM-derived features of news, users, and user engagements. This allows it to extract more reliable domain-shared representations that improve knowledge transfer to unseen domains. Extensive experiments on real-world datasets demonstrate that DAUD outperforms state-of-the-art baselines in both general and unseen-domain CD-FND settings.
Diagnostic-Guided Dynamic Profile Optimization for LLM-based User Simulators in Sequential Recommendation
Aug 18, 2025Recent advances in large language models (LLMs) have enabled realistic user simulators for developing and evaluating recommender systems (RSs). However, existing LLM-based simulators for RSs face two major limitations: (1) static and single-step prompt-based inference that leads to inaccurate and incomplete user profile construction; (2) unrealistic and single-round recommendation-feedback interaction pattern that fails to capture real-world scenarios. To address these limitations, we propose DGDPO (Diagnostic-Guided Dynamic Profile Optimization), a novel framework that constructs user profile through a dynamic and iterative optimization process to enhance the simulation fidelity. Specifically, DGDPO incorporates two core modules within each optimization loop: firstly, a specialized LLM-based diagnostic module, calibrated through our novel training strategy, accurately identifies specific defects in the user profile. Subsequently, a generalized LLM-based treatment module analyzes the diagnosed defect and generates targeted suggestions to refine the profile. Furthermore, unlike existing LLM-based user simulators that are limited to single-round interactions, we are the first to integrate DGDPO with sequential recommenders, enabling a bidirectional evolution where user profiles and recommendation strategies adapt to each other over multi-round interactions. Extensive experiments conducted on three real-world datasets demonstrate the effectiveness of our proposed framework.
Causal-Invariant Cross-Domain Out-of-Distribution Recommendation
May 22, 2025Cross-Domain Recommendation (CDR) aims to leverage knowledge from a relatively data-richer source domain to address the data sparsity problem in a relatively data-sparser target domain. While CDR methods need to address the distribution shifts between different domains, i.e., cross-domain distribution shifts (CDDS), they typically assume independent and identical distribution (IID) between training and testing data within the target domain. However, this IID assumption rarely holds in real-world scenarios due to single-domain distribution shift (SDDS). The above two co-existing distribution shifts lead to out-of-distribution (OOD) environments that hinder effective knowledge transfer and generalization, ultimately degrading recommendation performance in CDR. To address these co-existing distribution shifts, we propose a novel Causal-Invariant Cross-Domain Out-of-distribution Recommendation framework, called CICDOR. In CICDOR, we first learn dual-level causal structures to infer domain-specific and domain-shared causal-invariant user preferences for tackling both CDDS and SDDS under OOD environments in CDR. Then, we propose an LLM-guided confounder discovery module that seamlessly integrates LLMs with a conventional causal discovery method to extract observed confounders for effective deconfounding, thereby enabling accurate causal-invariant preference inference. Extensive experiments on two real-world datasets demonstrate the superior recommendation accuracy of CICDOR over state-of-the-art methods across various OOD scenarios.
Approximating the total variation distance between spin systems
Feb 08, 2025Spin systems form an important class of undirected graphical models. For two Gibbs distributions $\mu$ and $\nu$ induced by two spin systems on the same graph $G = (V, E)$, we study the problem of approximating the total variation distance $d_{TV}(\mu,\nu)$ with an $\epsilon$-relative error. We propose a new reduction that connects the problem of approximating the TV-distance to sampling and approximate counting. Our applications include the hardcore model and the antiferromagnetic Ising model in the uniqueness regime, the ferromagnetic Ising model, and the general Ising model satisfying the spectral condition. Additionally, we explore the computational complexity of approximating the total variation distance $d_{TV}(\mu_S,\nu_S)$ between two marginal distributions on an arbitrary subset $S \subseteq V$. We prove that this problem remains hard even when both $\mu$ and $\nu$ admit polynomial-time sampling and approximate counting algorithms.
Large Language Models for Intent-Driven Session Recommendations
Dec 07, 2023Intent-aware session recommendation (ISR) is pivotal in discerning user intents within sessions for precise predictions. Traditional approaches, however, face limitations due to their presumption of a uniform number of intents across all sessions. This assumption overlooks the dynamic nature of user sessions, where the number and type of intentions can significantly vary. In addition, these methods typically operate in latent spaces, thus hinder the model's transparency.Addressing these challenges, we introduce a novel ISR approach, utilizing the advanced reasoning capabilities of large language models (LLMs). First, this approach begins by generating an initial prompt that guides LLMs to predict the next item in a session, based on the varied intents manifested in user sessions. Then, to refine this process, we introduce an innovative prompt optimization mechanism that iteratively self-reflects and adjusts prompts. Furthermore, our prompt selection module, built upon the LLMs' broad adaptability, swiftly selects the most optimized prompts across diverse domains. This new paradigm empowers LLMs to discern diverse user intents at a semantic level, leading to more accurate and interpretable session recommendations. Our extensive experiments on three real-world datasets demonstrate the effectiveness of our method, marking a significant advancement in ISR systems.
Towards Building Voice-based Conversational Recommender Systems: Datasets, Potential Solutions, and Prospects
Jun 14, 2023Conversational recommender systems (CRSs) have become crucial emerging research topics in the field of RSs, thanks to their natural advantages of explicitly acquiring user preferences via interactive conversations and revealing the reasons behind recommendations. However, the majority of current CRSs are text-based, which is less user-friendly and may pose challenges for certain users, such as those with visual impairments or limited writing and reading abilities. Therefore, for the first time, this paper investigates the potential of voice-based CRS (VCRSs) to revolutionize the way users interact with RSs in a natural, intuitive, convenient, and accessible fashion. To support such studies, we create two VCRSs benchmark datasets in the e-commerce and movie domains, after realizing the lack of such datasets through an exhaustive literature review. Specifically, we first empirically verify the benefits and necessity of creating such datasets. Thereafter, we convert the user-item interactions to text-based conversations through the ChatGPT-driven prompts for generating diverse and natural templates, and then synthesize the corresponding audios via the text-to-speech model. Meanwhile, a number of strategies are delicately designed to ensure the naturalness and high quality of voice conversations. On this basis, we further explore the potential solutions and point out possible directions to build end-to-end VCRSs by seamlessly extracting and integrating voice-based inputs, thus delivering performance-enhanced, self-explainable, and user-friendly VCRSs. Our study aims to establish the foundation and motivate further pioneering research in the emerging field of VCRSs. This aligns with the principles of explainable AI and AI for social good, viz., utilizing technology's potential to create a fair, sustainable, and just world.
DaisyRec 2.0: Benchmarking Recommendation for Rigorous Evaluation
Jun 22, 2022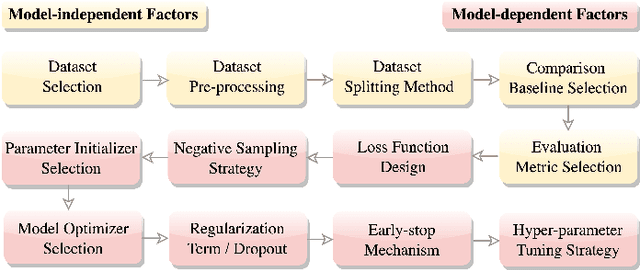
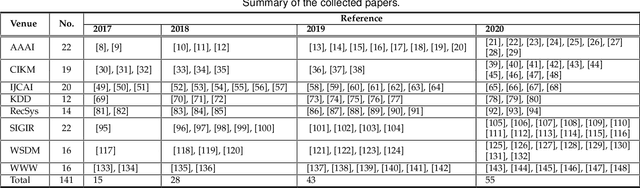
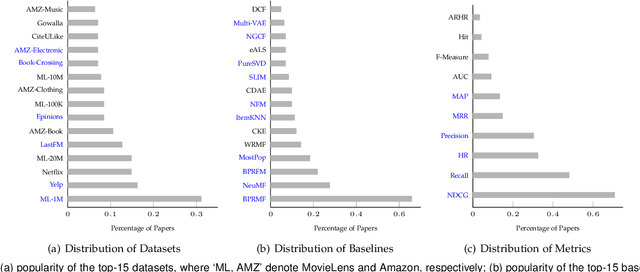
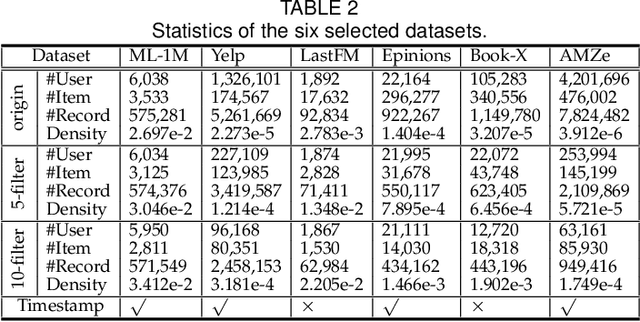
Recently, one critical issue looms large in the field of recommender systems -- there are no effective benchmarks for rigorous evaluation -- which consequently leads to unreproducible evaluation and unfair comparison. We, therefore, conduct studies from the perspectives of practical theory and experiments, aiming at benchmarking recommendation for rigorous evaluation. Regarding the theoretical study, a series of hyper-factors affecting recommendation performance throughout the whole evaluation chain are systematically summarized and analyzed via an exhaustive review on 141 papers published at eight top-tier conferences within 2017-2020. We then classify them into model-independent and model-dependent hyper-factors, and different modes of rigorous evaluation are defined and discussed in-depth accordingly. For the experimental study, we release DaisyRec 2.0 library by integrating these hyper-factors to perform rigorous evaluation, whereby a holistic empirical study is conducted to unveil the impacts of different hyper-factors on recommendation performance. Supported by the theoretical and experimental studies, we finally create benchmarks for rigorous evaluation by proposing standardized procedures and providing performance of ten state-of-the-arts across six evaluation metrics on six datasets as a reference for later study. Overall, our work sheds light on the issues in recommendation evaluation, provides potential solutions for rigorous evaluation, and lays foundation for further investigation.