 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProspective evaluation of multimodal respiratory failure prediction: Do chest X-rays improve performance beyond EHR signals?
May 27, 2026Early prediction of respiratory failure is critical for timely clinical intervention in intensive care units. Existing electronic health record (EHR)-based models can continuously monitor physiologic deterioration, but they may not fully capture pulmonary pathophysiology reflected in chest radiographs (CXRs). In this study, we ask whether CXR information improves prospective prediction of invasive mechanical ventilation beyond EHR signals alone. We develop a gated multimodal framework that integrates structured EHR time-series data with CXR foundation-model representations. The gating module adaptively controls the contribution of imaging features based on patient-specific clinical context, allowing the model to selectively rely on imaging information when it is informative. We prospectively evaluate the framework for predicting invasive mechanical ventilation within 24 hours in ICU patients and compare it with an established EHR-only model (Ventio), physician predictions obtained at matched clinical time points, and alternative multimodal variants. The gated multimodal models achieved higher discrimination than the EHR-only baseline, with AUROC values of 0.860 and 0.858 using REMEDIS and MedInsight CXR representations, respectively, compared with 0.752 for Ventio. Relative to physician predictions, the multimodal framework substantially improved sensitivity while maintaining favorable specificity. Compared with the EHR-only model, multimodal integration increased specificity and positive predictive value, suggesting that CXR information can refine risk estimation in selected patients. These findings support adaptive multimodal fusion as a practical strategy for incorporating imaging into prospective respiratory failure prediction.
Does Faithfulness Conflict with Plausibility? An Empirical Study in Explainable AI across NLP Tasks
Mar 29, 2024



Explainability algorithms aimed at interpreting decision-making AI systems usually consider balancing two critical dimensions: 1) \textit{faithfulness}, where explanations accurately reflect the model's inference process. 2) \textit{plausibility}, where explanations are consistent with domain experts. However, the question arises: do faithfulness and plausibility inherently conflict? In this study, through a comprehensive quantitative comparison between the explanations from the selected explainability methods and expert-level interpretations across three NLP tasks: sentiment analysis, intent detection, and topic labeling, we demonstrate that traditional perturbation-based methods Shapley value and LIME could attain greater faithfulness and plausibility. Our findings suggest that rather than optimizing for one dimension at the expense of the other, we could seek to optimize explainability algorithms with dual objectives to achieve high levels of accuracy and user accessibility in their explanations.
Asymmetric feature interaction for interpreting model predictions
May 12, 2023



In natural language processing (NLP), deep neural networks (DNNs) could model complex interactions between context and have achieved impressive results on a range of NLP tasks. Prior works on feature interaction attribution mainly focus on studying symmetric interaction that only explains the additional influence of a set of words in combination, which fails to capture asymmetric influence that contributes to model prediction. In this work, we propose an asymmetric feature interaction attribution explanation model that aims to explore asymmetric higher-order feature interactions in the inference of deep neural NLP models. By representing our explanation with an directed interaction graph, we experimentally demonstrate interpretability of the graph to discover asymmetric feature interactions. Experimental results on two sentiment classification datasets show the superiority of our model against the state-of-the-art feature interaction attribution methods in identifying influential features for model predictions. Our code is available at https://github.com/StillLu/ASIV.
Learning Ambiguity from Crowd Sequential Annotations
Jan 04, 2023



Most crowdsourcing learning methods treat disagreement between annotators as noisy labelings while inter-disagreement among experts is often a good indicator for the ambiguity and uncertainty that is inherent in natural language. In this paper, we propose a framework called Learning Ambiguity from Crowd Sequential Annotations (LA-SCA) to explore the inter-disagreement between reliable annotators and effectively preserve confusing label information. First, a hierarchical Bayesian model is developed to infer ground-truth from crowds and group the annotators with similar reliability together. By modeling the relationship between the size of group the annotator involved in, the annotator's reliability and element's unambiguity in each sequence, inter-disagreement between reliable annotators on ambiguous elements is computed to obtain label confusing information that is incorporated to cost-sensitive sequence labeling. Experimental results on POS tagging and NER tasks show that our proposed framework achieves competitive performance in inferring ground-truth from crowds and predicting unknown sequences, and interpreting hierarchical clustering results helps discover labeling patterns of annotators with similar reliability.
Modeling sequential annotations for sequence labeling with crowds
Sep 20, 2022
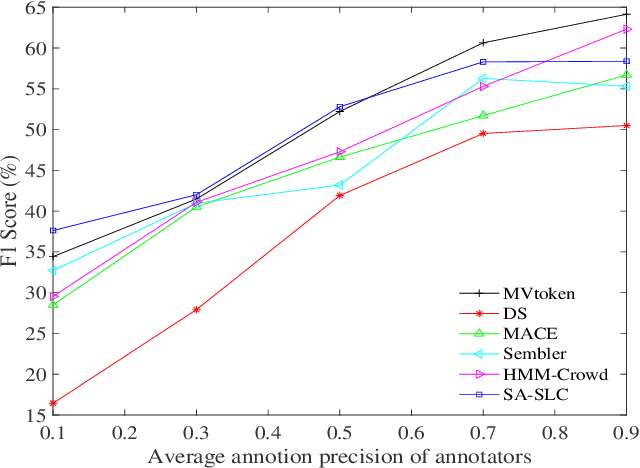
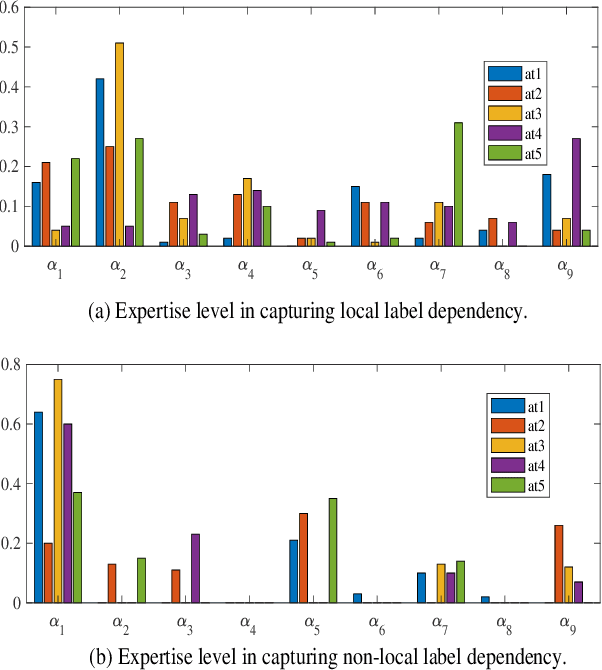
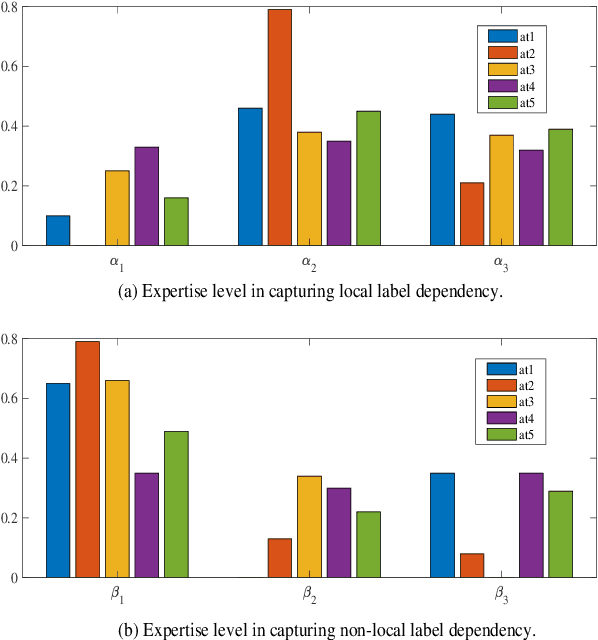
Crowd sequential annotations can be an efficient and cost-effective way to build large datasets for sequence labeling. Different from tagging independent instances, for crowd sequential annotations the quality of label sequence relies on the expertise level of annotators in capturing internal dependencies for each token in the sequence. In this paper, we propose Modeling sequential annotation for sequence labeling with crowds (SA-SLC). First, a conditional probabilistic model is developed to jointly model sequential data and annotators' expertise, in which categorical distribution is introduced to estimate the reliability of each annotator in capturing local and non-local label dependency for sequential annotation. To accelerate the marginalization of the proposed model, a valid label sequence inference (VLSE) method is proposed to derive the valid ground-truth label sequences from crowd sequential annotations. VLSE derives possible ground-truth labels from the token-wise level and further prunes sub-paths in the forward inference for label sequence decoding. VLSE reduces the number of candidate label sequences and improves the quality of possible ground-truth label sequences. The experimental results on several sequence labeling tasks of Natural Language Processing show the effectiveness of the proposed model.
Weak Disambiguation for Partial Structured Output Learning
Sep 20, 2022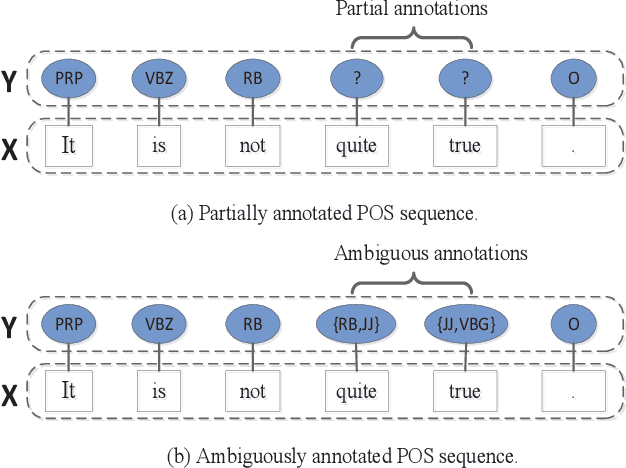
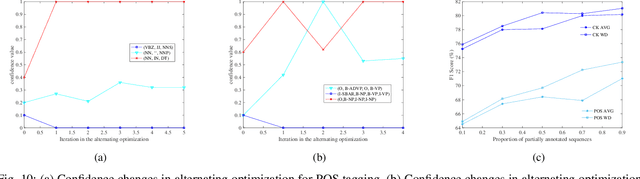

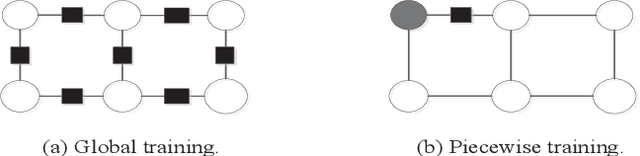
Existing disambiguation strategies for partial structured output learning just cannot generalize well to solve the problem that there are some candidates which can be false positive or similar to the ground-truth label. In this paper, we propose a novel weak disambiguation for partial structured output learning (WD-PSL). First, a piecewise large margin formulation is generalized to partial structured output learning, which effectively avoids handling large number of candidate structured outputs for complex structures. Second, in the proposed weak disambiguation strategy, each candidate label is assigned with a confidence value indicating how likely it is the true label, which aims to reduce the negative effects of wrong ground-truth label assignment in the learning process. Then two large margins are formulated to combine two types of constraints which are the disambiguation between candidates and non-candidates, and the weak disambiguation for candidates. In the framework of alternating optimization, a new 2n-slack variables cutting plane algorithm is developed to accelerate each iteration of optimization. The experimental results on several sequence labeling tasks of Natural Language Processing show the effectiveness of the proposed model.
Partial sequence labeling with structured Gaussian Processes
Sep 20, 2022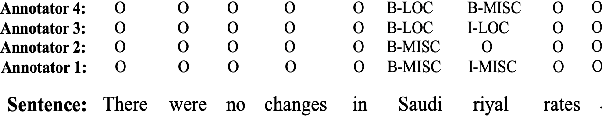

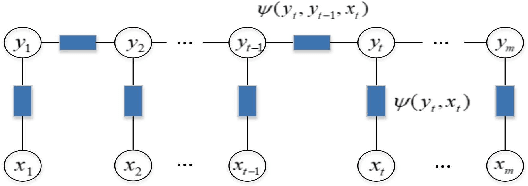
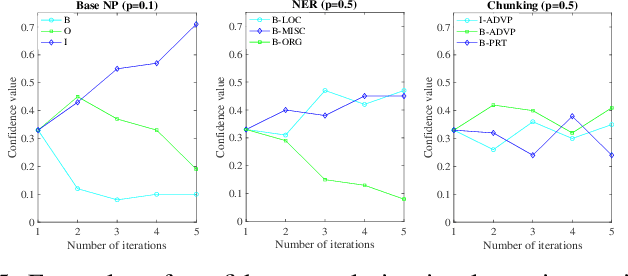
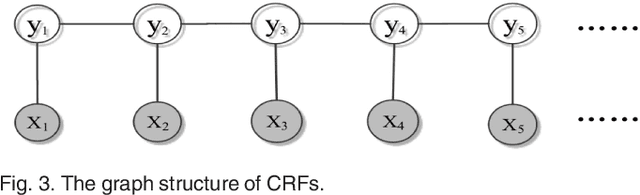
Existing partial sequence labeling models mainly focus on max-margin framework which fails to provide an uncertainty estimation of the prediction. Further, the unique ground truth disambiguation strategy employed by these models may include wrong label information for parameter learning. In this paper, we propose structured Gaussian Processes for partial sequence labeling (SGPPSL), which encodes uncertainty in the prediction and does not need extra effort for model selection and hyperparameter learning. The model employs factor-as-piece approximation that divides the linear-chain graph structure into the set of pieces, which preserves the basic Markov Random Field structure and effectively avoids handling large number of candidate output sequences generated by partially annotated data. Then confidence measure is introduced in the model to address different contributions of candidate labels, which enables the ground-truth label information to be utilized in parameter learning. Based on the derived lower bound of the variational lower bound of the proposed model, variational parameters and confidence measures are estimated in the framework of alternating optimization. Moreover, weighted Viterbi algorithm is proposed to incorporate confidence measure to sequence prediction, which considers label ambiguity arose from multiple annotations in the training data and thus helps improve the performance. SGPPSL is evaluated on several sequence labeling tasks and the experimental results show the effectiveness of the proposed model.
Duration modeling with semi-Markov Conditional Random Fields for keyphrase extraction
Sep 19, 2022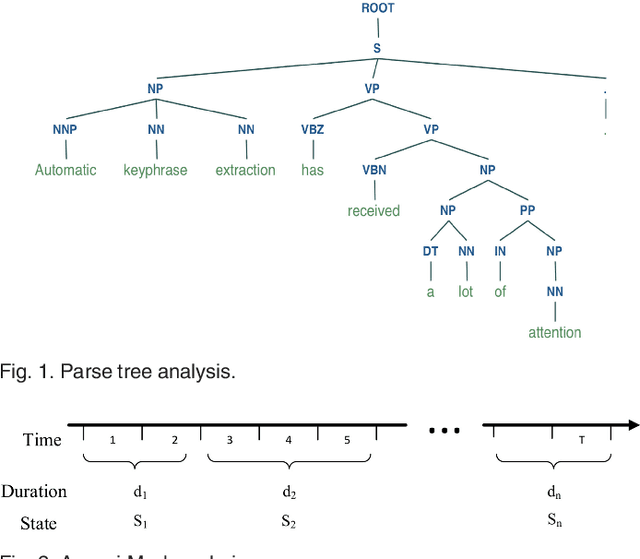


Existing methods for keyphrase extraction need preprocessing to generate candidate phrase or post-processing to transform keyword into keyphrase. In this paper, we propose a novel approach called duration modeling with semi-Markov Conditional Random Fields (DM-SMCRFs) for keyphrase extraction. First of all, based on the property of semi-Markov chain, DM-SMCRFs can encode segment-level features and sequentially classify the phrase in the sentence as keyphrase or non-keyphrase. Second, by assuming the independence between state transition and state duration, DM-SMCRFs model the distribution of duration (length) of keyphrases to further explore state duration information, which can help identify the size of keyphrase. Based on the convexity of parametric duration feature derived from duration distribution, a constrained Viterbi algorithm is derived to improve the performance of decoding in DM-SMCRFs. We thoroughly evaluate the performance of DM-SMCRFs on the datasets from various domains. The experimental results demonstrate the effectiveness of proposed model.
Fine-tuning Pre-trained Language Models for Few-shot Intent Detection: Supervised Pre-training and Isotropization
May 15, 2022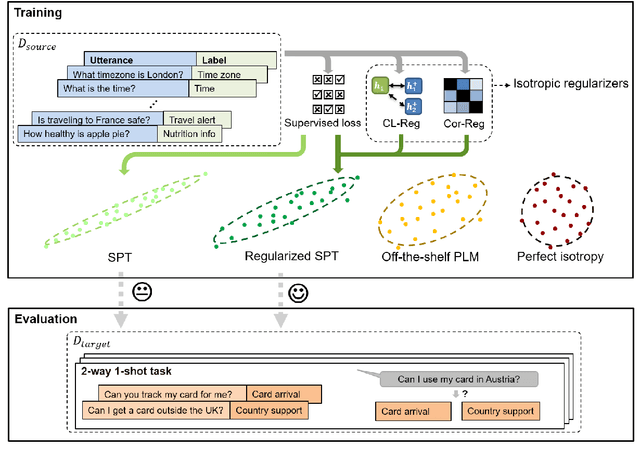
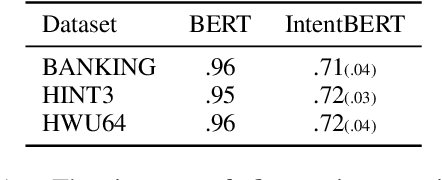
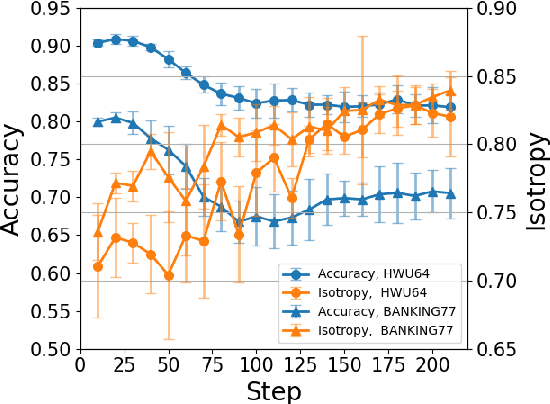

It is challenging to train a good intent classifier for a task-oriented dialogue system with only a few annotations. Recent studies have shown that fine-tuning pre-trained language models with a small amount of labeled utterances from public benchmarks in a supervised manner is extremely helpful. However, we find that supervised pre-training yields an anisotropic feature space, which may suppress the expressive power of the semantic representations. Inspired by recent research in isotropization, we propose to improve supervised pre-training by regularizing the feature space towards isotropy. We propose two regularizers based on contrastive learning and correlation matrix respectively, and demonstrate their effectiveness through extensive experiments. Our main finding is that it is promising to regularize supervised pre-training with isotropization to further improve the performance of few-shot intent detection. The source code can be found at https://github.com/fanolabs/isoIntentBert-main.
BERT-CNN: a Hierarchical Patent Classifier Based on a Pre-Trained Language Model
Nov 03, 2019The automatic classification is a process of automatically assigning text documents to predefined categories. An accurate automatic patent classifier is crucial to patent inventors and patent examiners in terms of intellectual property protection, patent management, and patent information retrieval. We present BERT-CNN, a hierarchical patent classifier based on pre-trained language model by training the national patent application documents collected from the State Information Center, China. The experimental results show that BERT-CNN achieves 84.3% accuracy, which is far better than the two compared baseline methods, Convolutional Neural Networks and Recurrent Neural Networks. We didn't apply our model to the third and fourth hierarchical level of the International Patent Classification - "subclass" and "group".The visualization of the Attention Mechanism shows that BERT-CNN obtains new state-of-the-art results in representing vocabularies and semantics. This article demonstrates the practicality and effectiveness of BERT-CNN in the field of automatic patent classification.