 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Reward Alignment via Hypothesis Space Batch Cutting
Feb 06, 2025



Reward design for reinforcement learning and optimal control agents is challenging. Preference-based alignment addresses this by enabling agents to learn rewards from ranked trajectory pairs provided by humans. However, existing methods often struggle from poor robustness to unknown false human preferences. In this work, we propose a robust and efficient reward alignment method based on a novel and geometrically interpretable perspective: hypothesis space batched cutting. Our method iteratively refines the reward hypothesis space through "cuts" based on batches of human preferences. Within each batch, human preferences, queried based on disagreement, are grouped using a voting function to determine the appropriate cut, ensuring a bounded human query complexity. To handle unknown erroneous preferences, we introduce a conservative cutting method within each batch, preventing erroneous human preferences from making overly aggressive cuts to the hypothesis space. This guarantees provable robustness against false preferences. We evaluate our method in a model predictive control setting across diverse tasks, including DM-Control, dexterous in-hand manipulation, and locomotion. The results demonstrate that our framework achieves comparable or superior performance to state-of-the-art methods in error-free settings while significantly outperforming existing method when handling high percentage of erroneous human preferences.
Minimizing PLM-Based Few-Shot Intent Detectors
Jul 13, 2024



Recent research has demonstrated the feasibility of training efficient intent detectors based on pre-trained language model~(PLM) with limited labeled data. However, deploying these detectors in resource-constrained environments such as mobile devices poses challenges due to their large sizes. In this work, we aim to address this issue by exploring techniques to minimize the size of PLM-based intent detectors trained with few-shot data. Specifically, we utilize large language models (LLMs) for data augmentation, employ a cutting-edge model compression method for knowledge distillation, and devise a vocabulary pruning mechanism called V-Prune. Through these approaches, we successfully achieve a compression ratio of 21 in model memory usage, including both Transformer and the vocabulary, while maintaining almost identical performance levels on four real-world benchmarks.
Revisit Few-shot Intent Classification with PLMs: Direct Fine-tuning vs. Continual Pre-training
Jun 08, 2023We consider the task of few-shot intent detection, which involves training a deep learning model to classify utterances based on their underlying intents using only a small amount of labeled data. The current approach to address this problem is through continual pre-training, i.e., fine-tuning pre-trained language models (PLMs) on external resources (e.g., conversational corpora, public intent detection datasets, or natural language understanding datasets) before using them as utterance encoders for training an intent classifier. In this paper, we show that continual pre-training may not be essential, since the overfitting problem of PLMs on this task may not be as serious as expected. Specifically, we find that directly fine-tuning PLMs on only a handful of labeled examples already yields decent results compared to methods that employ continual pre-training, and the performance gap diminishes rapidly as the number of labeled data increases. To maximize the utilization of the limited available data, we propose a context augmentation method and leverage sequential self-distillation to boost performance. Comprehensive experiments on real-world benchmarks show that given only two or more labeled samples per class, direct fine-tuning outperforms many strong baselines that utilize external data sources for continual pre-training. The code can be found at https://github.com/hdzhang-code/DFTPlus.
Asymmetric feature interaction for interpreting model predictions
May 12, 2023



In natural language processing (NLP), deep neural networks (DNNs) could model complex interactions between context and have achieved impressive results on a range of NLP tasks. Prior works on feature interaction attribution mainly focus on studying symmetric interaction that only explains the additional influence of a set of words in combination, which fails to capture asymmetric influence that contributes to model prediction. In this work, we propose an asymmetric feature interaction attribution explanation model that aims to explore asymmetric higher-order feature interactions in the inference of deep neural NLP models. By representing our explanation with an directed interaction graph, we experimentally demonstrate interpretability of the graph to discover asymmetric feature interactions. Experimental results on two sentiment classification datasets show the superiority of our model against the state-of-the-art feature interaction attribution methods in identifying influential features for model predictions. Our code is available at https://github.com/StillLu/ASIV.
New Intent Discovery with Pre-training and Contrastive Learning
May 25, 2022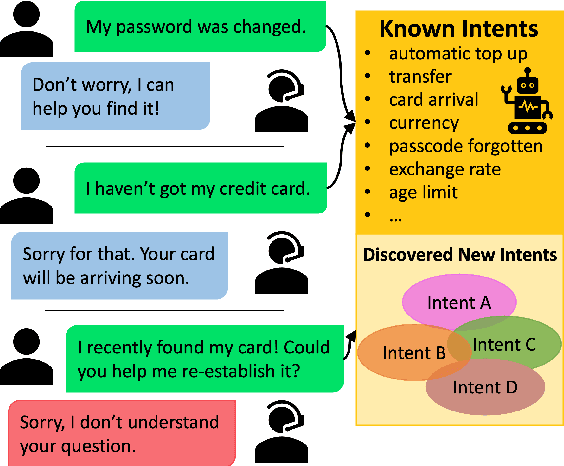
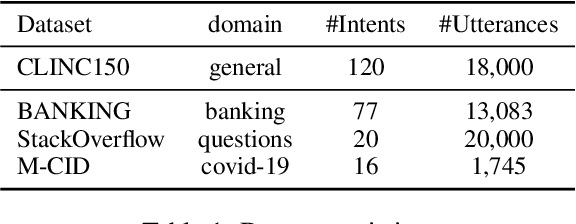
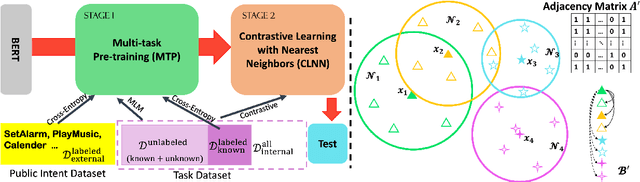
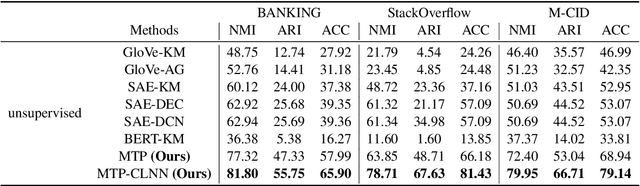
New intent discovery aims to uncover novel intent categories from user utterances to expand the set of supported intent classes. It is a critical task for the development and service expansion of a practical dialogue system. Despite its importance, this problem remains under-explored in the literature. Existing approaches typically rely on a large amount of labeled utterances and employ pseudo-labeling methods for representation learning and clustering, which are label-intensive, inefficient, and inaccurate. In this paper, we provide new solutions to two important research questions for new intent discovery: (1) how to learn semantic utterance representations and (2) how to better cluster utterances. Particularly, we first propose a multi-task pre-training strategy to leverage rich unlabeled data along with external labeled data for representation learning. Then, we design a new contrastive loss to exploit self-supervisory signals in unlabeled data for clustering. Extensive experiments on three intent recognition benchmarks demonstrate the high effectiveness of our proposed method, which outperforms state-of-the-art methods by a large margin in both unsupervised and semi-supervised scenarios. The source code will be available at \url{https://github.com/zhang-yu-wei/MTP-CLNN}.
Fine-tuning Pre-trained Language Models for Few-shot Intent Detection: Supervised Pre-training and Isotropization
May 15, 2022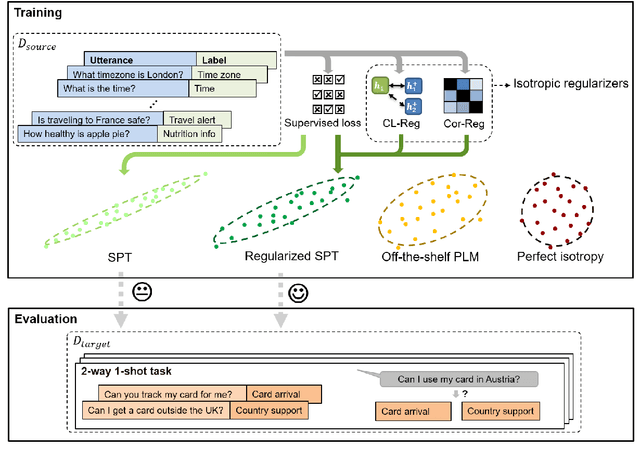
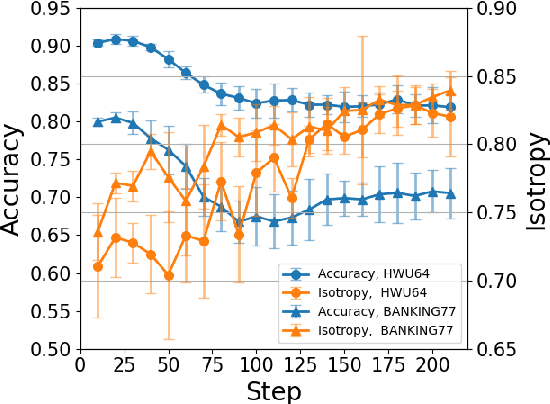

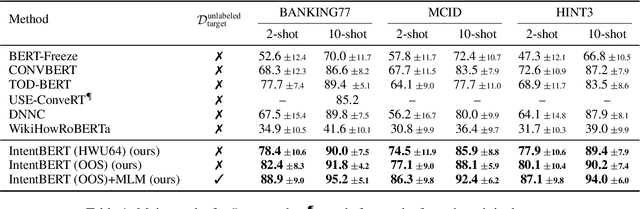
It is challenging to train a good intent classifier for a task-oriented dialogue system with only a few annotations. Recent studies have shown that fine-tuning pre-trained language models with a small amount of labeled utterances from public benchmarks in a supervised manner is extremely helpful. However, we find that supervised pre-training yields an anisotropic feature space, which may suppress the expressive power of the semantic representations. Inspired by recent research in isotropization, we propose to improve supervised pre-training by regularizing the feature space towards isotropy. We propose two regularizers based on contrastive learning and correlation matrix respectively, and demonstrate their effectiveness through extensive experiments. Our main finding is that it is promising to regularize supervised pre-training with isotropization to further improve the performance of few-shot intent detection. The source code can be found at https://github.com/fanolabs/isoIntentBert-main.
Effectiveness of Pre-training for Few-shot Intent Classification
Sep 13, 2021
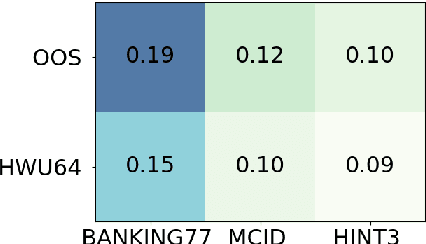
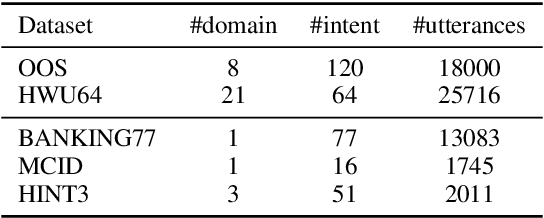
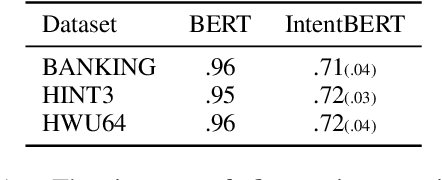
This paper investigates the effectiveness of pre-training for few-shot intent classification. While existing paradigms commonly further pre-train language models such as BERT on a vast amount of unlabeled corpus, we find it highly effective and efficient to simply fine-tune BERT with a small set of labeled utterances from public datasets. Specifically, fine-tuning BERT with roughly 1,000 labeled data yields a pre-trained model -- IntentBERT, which can easily surpass the performance of existing pre-trained models for few-shot intent classification on novel domains with very different semantics. The high effectiveness of IntentBERT confirms the feasibility and practicality of few-shot intent detection, and its high generalization ability across different domains suggests that intent classification tasks may share a similar underlying structure, which can be efficiently learned from a small set of labeled data. The source code can be found at https://github.com/hdzhang-code/IntentBERT.