 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEAL: Disentangling Transformer Head Activations for LLM Steering
Jun 10, 2025Inference-time steering aims to alter the response characteristics of large language models (LLMs) without modifying their underlying parameters. A critical step in this process is the identification of internal modules within LLMs that are associated with the target behavior. However, current approaches to module selection often depend on superficial cues or ad-hoc heuristics, which can result in suboptimal or unintended outcomes. In this work, we propose a principled causal-attribution framework for identifying behavior-relevant attention heads in transformers. For each head, we train a vector-quantized autoencoder (VQ-AE) on its attention activations, partitioning the latent space into behavior-relevant and behavior-irrelevant subspaces, each quantized with a shared learnable codebook. We assess the behavioral relevance of each head by quantifying the separability of VQ-AE encodings for behavior-aligned versus behavior-violating responses using a binary classification metric. This yields a behavioral relevance score that reflects each head discriminative capacity with respect to the target behavior, guiding both selection and importance weighting. Experiments on seven LLMs from two model families and five behavioral steering datasets demonstrate that our method enables more accurate inference-time interventions, achieving superior performance on the truthfulness-steering task. Furthermore, the heads selected by our approach exhibit strong zero-shot generalization in cross-domain truthfulness-steering scenarios.
Continual Dialogue State Tracking via Reason-of-Select Distillation
Aug 19, 2024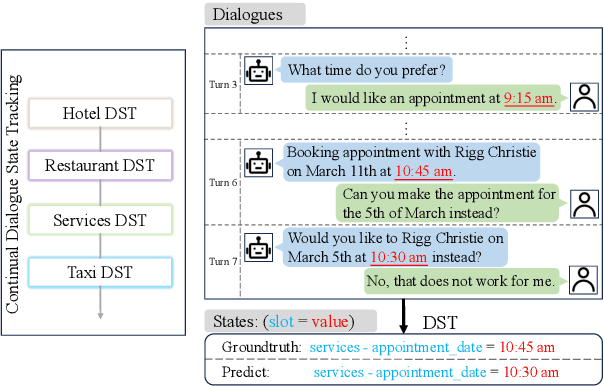

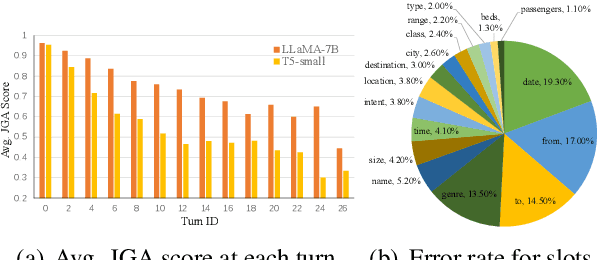
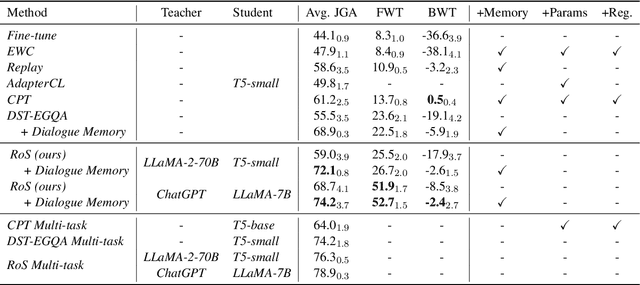
An ideal dialogue system requires continuous skill acquisition and adaptation to new tasks while retaining prior knowledge. Dialogue State Tracking (DST), vital in these systems, often involves learning new services and confronting catastrophic forgetting, along with a critical capability loss termed the "Value Selection Quandary." To address these challenges, we introduce the Reason-of-Select (RoS) distillation method by enhancing smaller models with a novel 'meta-reasoning' capability. Meta-reasoning employs an enhanced multi-domain perspective, combining fragments of meta-knowledge from domain-specific dialogues during continual learning. This transcends traditional single-perspective reasoning. The domain bootstrapping process enhances the model's ability to dissect intricate dialogues from multiple possible values. Its domain-agnostic property aligns data distribution across different domains, effectively mitigating forgetting. Additionally, two novel improvements, "multi-value resolution" strategy and Semantic Contrastive Reasoning Selection method, significantly enhance RoS by generating DST-specific selection chains and mitigating hallucinations in teachers' reasoning, ensuring effective and reliable knowledge transfer. Extensive experiments validate the exceptional performance and robust generalization capabilities of our method. The source code is provided for reproducibility.
VI-OOD: A Unified Representation Learning Framework for Textual Out-of-distribution Detection
Apr 09, 2024



Out-of-distribution (OOD) detection plays a crucial role in ensuring the safety and reliability of deep neural networks in various applications. While there has been a growing focus on OOD detection in visual data, the field of textual OOD detection has received less attention. Only a few attempts have been made to directly apply general OOD detection methods to natural language processing (NLP) tasks, without adequately considering the characteristics of textual data. In this paper, we delve into textual OOD detection with Transformers. We first identify a key problem prevalent in existing OOD detection methods: the biased representation learned through the maximization of the conditional likelihood $p(y\mid x)$ can potentially result in subpar performance. We then propose a novel variational inference framework for OOD detection (VI-OOD), which maximizes the likelihood of the joint distribution $p(x, y)$ instead of $p(y\mid x)$. VI-OOD is tailored for textual OOD detection by efficiently exploiting the representations of pre-trained Transformers. Through comprehensive experiments on various text classification tasks, VI-OOD demonstrates its effectiveness and wide applicability. Our code has been released at \url{https://github.com/liam0949/LLM-OOD}.
New Intent Discovery with Pre-training and Contrastive Learning
May 25, 2022
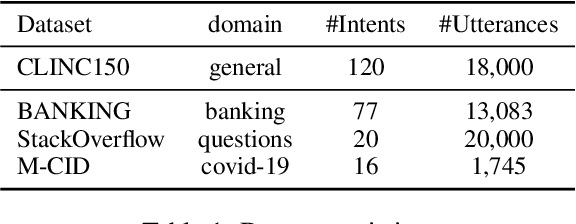
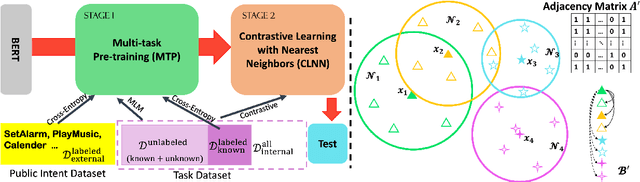
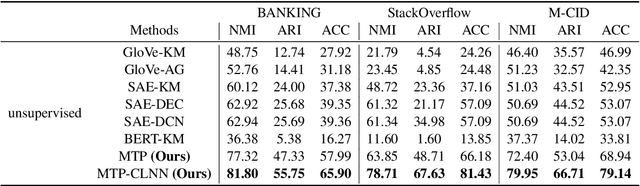
New intent discovery aims to uncover novel intent categories from user utterances to expand the set of supported intent classes. It is a critical task for the development and service expansion of a practical dialogue system. Despite its importance, this problem remains under-explored in the literature. Existing approaches typically rely on a large amount of labeled utterances and employ pseudo-labeling methods for representation learning and clustering, which are label-intensive, inefficient, and inaccurate. In this paper, we provide new solutions to two important research questions for new intent discovery: (1) how to learn semantic utterance representations and (2) how to better cluster utterances. Particularly, we first propose a multi-task pre-training strategy to leverage rich unlabeled data along with external labeled data for representation learning. Then, we design a new contrastive loss to exploit self-supervisory signals in unlabeled data for clustering. Extensive experiments on three intent recognition benchmarks demonstrate the high effectiveness of our proposed method, which outperforms state-of-the-art methods by a large margin in both unsupervised and semi-supervised scenarios. The source code will be available at \url{https://github.com/zhang-yu-wei/MTP-CLNN}.
Overcoming Catastrophic Forgetting in Incremental Few-Shot Learning by Finding Flat Minima
Nov 04, 2021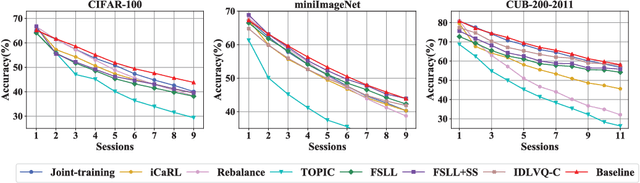
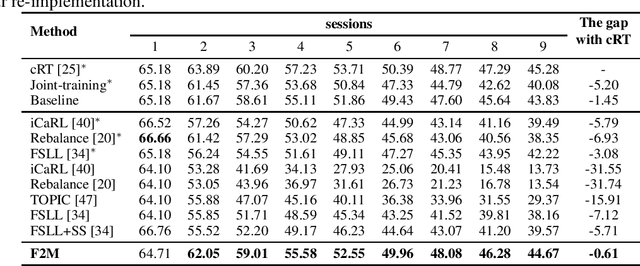
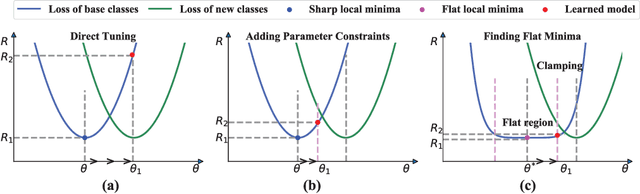
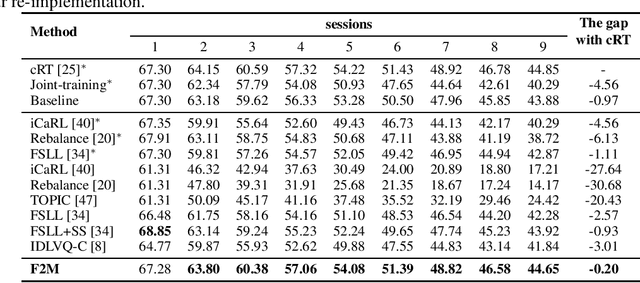
This paper considers incremental few-shot learning, which requires a model to continually recognize new categories with only a few examples provided. Our study shows that existing methods severely suffer from catastrophic forgetting, a well-known problem in incremental learning, which is aggravated due to data scarcity and imbalance in the few-shot setting. Our analysis further suggests that to prevent catastrophic forgetting, actions need to be taken in the primitive stage -- the training of base classes instead of later few-shot learning sessions. Therefore, we propose to search for flat local minima of the base training objective function and then fine-tune the model parameters within the flat region on new tasks. In this way, the model can efficiently learn new classes while preserving the old ones. Comprehensive experimental results demonstrate that our approach outperforms all prior state-of-the-art methods and is very close to the approximate upper bound. The source code is available at https://github.com/moukamisama/F2M.
Effectiveness of Pre-training for Few-shot Intent Classification
Sep 13, 2021
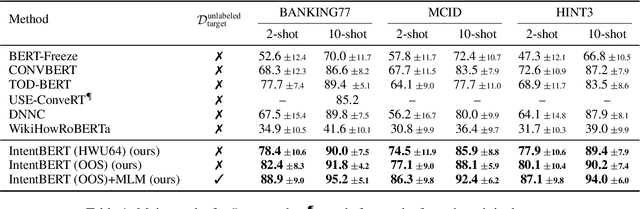
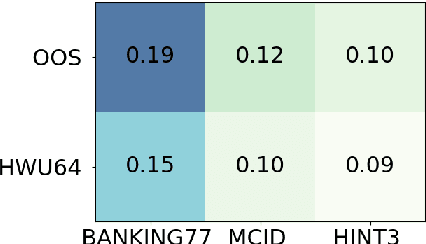
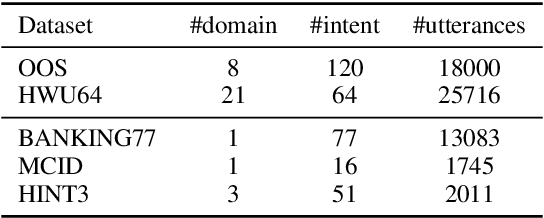
This paper investigates the effectiveness of pre-training for few-shot intent classification. While existing paradigms commonly further pre-train language models such as BERT on a vast amount of unlabeled corpus, we find it highly effective and efficient to simply fine-tune BERT with a small set of labeled utterances from public datasets. Specifically, fine-tuning BERT with roughly 1,000 labeled data yields a pre-trained model -- IntentBERT, which can easily surpass the performance of existing pre-trained models for few-shot intent classification on novel domains with very different semantics. The high effectiveness of IntentBERT confirms the feasibility and practicality of few-shot intent detection, and its high generalization ability across different domains suggests that intent classification tasks may share a similar underlying structure, which can be efficiently learned from a small set of labeled data. The source code can be found at https://github.com/hdzhang-code/IntentBERT.
Adaptation-Agnostic Meta-Training
Aug 24, 2021


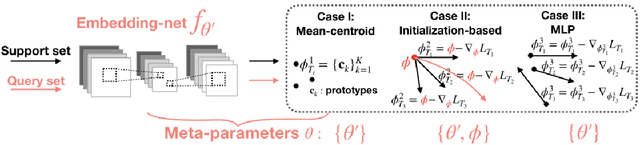
Many meta-learning algorithms can be formulated into an interleaved process, in the sense that task-specific predictors are learned during inner-task adaptation and meta-parameters are updated during meta-update. The normal meta-training strategy needs to differentiate through the inner-task adaptation procedure to optimize the meta-parameters. This leads to a constraint that the inner-task algorithms should be solved analytically. Under this constraint, only simple algorithms with analytical solutions can be applied as the inner-task algorithms, limiting the model expressiveness. To lift the limitation, we propose an adaptation-agnostic meta-training strategy. Following our proposed strategy, we can apply stronger algorithms (e.g., an ensemble of different types of algorithms) as the inner-task algorithm to achieve superior performance comparing with popular baselines. The source code is available at https://github.com/jiaxinchen666/AdaptationAgnosticMetaLearning.
Out-of-Scope Intent Detection with Self-Supervision and Discriminative Training
Jun 17, 2021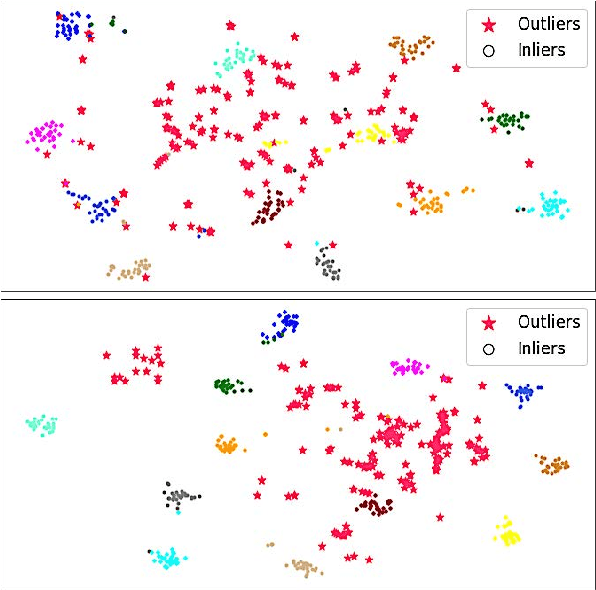

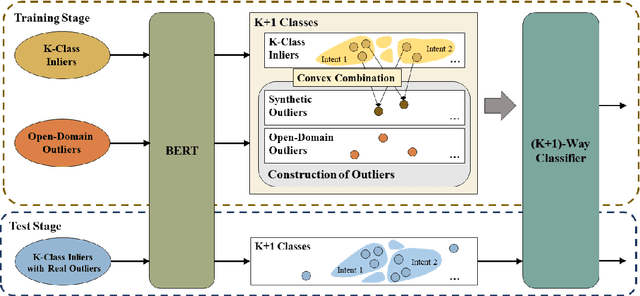

Out-of-scope intent detection is of practical importance in task-oriented dialogue systems. Since the distribution of outlier utterances is arbitrary and unknown in the training stage, existing methods commonly rely on strong assumptions on data distribution such as mixture of Gaussians to make inference, resulting in either complex multi-step training procedures or hand-crafted rules such as confidence threshold selection for outlier detection. In this paper, we propose a simple yet effective method to train an out-of-scope intent classifier in a fully end-to-end manner by simulating the test scenario in training, which requires no assumption on data distribution and no additional post-processing or threshold setting. Specifically, we construct a set of pseudo outliers in the training stage, by generating synthetic outliers using inliner features via self-supervision and sampling out-of-scope sentences from easily available open-domain datasets. The pseudo outliers are used to train a discriminative classifier that can be directly applied to and generalize well on the test task. We evaluate our method extensively on four benchmark dialogue datasets and observe significant improvements over state-of-the-art approaches. Our code has been released at https://github.com/liam0949/DCLOOS.
SLAKE: A Semantically-Labeled Knowledge-Enhanced Dataset for Medical Visual Question Answering
Feb 18, 2021


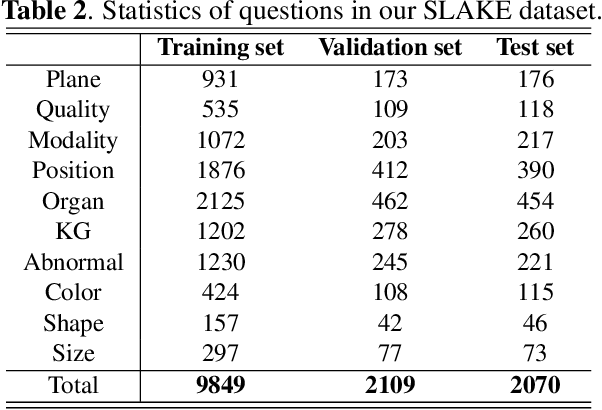
Medical visual question answering (Med-VQA) has tremendous potential in healthcare. However, the development of this technology is hindered by the lacking of publicly-available and high-quality labeled datasets for training and evaluation. In this paper, we present a large bilingual dataset, SLAKE, with comprehensive semantic labels annotated by experienced physicians and a new structural medical knowledge base for Med-VQA. Besides, SLAKE includes richer modalities and covers more human body parts than the currently available dataset. We show that SLAKE can be used to facilitate the development and evaluation of Med-VQA systems. The dataset can be downloaded from http://www.med-vqa.com/slake.
Variational Metric Scaling for Metric-Based Meta-Learning
Dec 26, 2019



Metric-based meta-learning has attracted a lot of attention due to its effectiveness and efficiency in few-shot learning. Recent studies show that metric scaling plays a crucial role in the performance of metric-based meta-learning algorithms. However, there still lacks a principled method for learning the metric scaling parameter automatically. In this paper, we recast metric-based meta-learning from a Bayesian perspective and develop a variational metric scaling framework for learning a proper metric scaling parameter. Firstly, we propose a stochastic variational method to learn a single global scaling parameter. To better fit the embedding space to a given data distribution, we extend our method to learn a dimensional scaling vector to transform the embedding space. Furthermore, to learn task-specific embeddings, we generate task-dependent dimensional scaling vectors with amortized variational inference. Our method is end-to-end without any pre-training and can be used as a simple plug-and-play module for existing metric-based meta-algorithms. Experiments on mini-ImageNet show that our methods can be used to consistently improve the performance of existing metric-based meta-algorithms including prototypical networks and TADAM.