 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEAL: Disentangling Transformer Head Activations for LLM Steering
Jun 10, 2025Inference-time steering aims to alter the response characteristics of large language models (LLMs) without modifying their underlying parameters. A critical step in this process is the identification of internal modules within LLMs that are associated with the target behavior. However, current approaches to module selection often depend on superficial cues or ad-hoc heuristics, which can result in suboptimal or unintended outcomes. In this work, we propose a principled causal-attribution framework for identifying behavior-relevant attention heads in transformers. For each head, we train a vector-quantized autoencoder (VQ-AE) on its attention activations, partitioning the latent space into behavior-relevant and behavior-irrelevant subspaces, each quantized with a shared learnable codebook. We assess the behavioral relevance of each head by quantifying the separability of VQ-AE encodings for behavior-aligned versus behavior-violating responses using a binary classification metric. This yields a behavioral relevance score that reflects each head discriminative capacity with respect to the target behavior, guiding both selection and importance weighting. Experiments on seven LLMs from two model families and five behavioral steering datasets demonstrate that our method enables more accurate inference-time interventions, achieving superior performance on the truthfulness-steering task. Furthermore, the heads selected by our approach exhibit strong zero-shot generalization in cross-domain truthfulness-steering scenarios.
GeoEdit: Geometric Knowledge Editing for Large Language Models
Feb 27, 2025Regular updates are essential for maintaining up-to-date knowledge in large language models (LLMs). Consequently, various model editing methods have been developed to update specific knowledge within LLMs. However, training-based approaches often struggle to effectively incorporate new knowledge while preserving unrelated general knowledge. To address this challenge, we propose a novel framework called Geometric Knowledge Editing (GeoEdit). GeoEdit utilizes the geometric relationships of parameter updates from fine-tuning to differentiate between neurons associated with new knowledge updates and those related to general knowledge perturbations. By employing a direction-aware knowledge identification method, we avoid updating neurons with directions approximately orthogonal to existing knowledge, thus preserving the model's generalization ability. For the remaining neurons, we integrate both old and new knowledge for aligned directions and apply a "forget-then-learn" editing strategy for opposite directions. Additionally, we introduce an importance-guided task vector fusion technique that filters out redundant information and provides adaptive neuron-level weighting, further enhancing model editing performance. Extensive experiments on two publicly available datasets demonstrate the superiority of GeoEdit over existing state-of-the-art methods.
Recurrent Knowledge Identification and Fusion for Language Model Continual Learning
Feb 22, 2025Continual learning (CL) is crucial for deploying large language models (LLMs) in dynamic real-world environments without costly retraining. While recent model ensemble and model merging methods guided by parameter importance have gained popularity, they often struggle to balance knowledge transfer and forgetting, mainly due to the reliance on static importance estimates during sequential training. In this paper, we present Recurrent-KIF, a novel CL framework for Recurrent Knowledge Identification and Fusion, which enables dynamic estimation of parameter importance distributions to enhance knowledge transfer. Inspired by human continual learning, Recurrent-KIF employs an inner loop that rapidly adapts to new tasks while identifying important parameters, coupled with an outer loop that globally manages the fusion of new and historical knowledge through redundant knowledge pruning and key knowledge merging. These inner-outer loops iteratively perform multiple rounds of fusion, allowing Recurrent-KIF to leverage intermediate training information and adaptively adjust fusion strategies based on evolving importance distributions. Extensive experiments on two CL benchmarks with various model sizes (from 770M to 13B) demonstrate that Recurrent-KIF effectively mitigates catastrophic forgetting and enhances knowledge transfer.
FedRIR: Rethinking Information Representation in Federated Learning
Feb 02, 2025Mobile and Web-of-Things (WoT) devices at the network edge generate vast amounts of data for machine learning applications, yet privacy concerns hinder centralized model training. Federated Learning (FL) allows clients (devices) to collaboratively train a shared model coordinated by a central server without transfer private data, but inherent statistical heterogeneity among clients presents challenges, often leading to a dilemma between clients' needs for personalized local models and the server's goal of building a generalized global model. Existing FL methods typically prioritize either global generalization or local personalization, resulting in a trade-off between these two objectives and limiting the full potential of diverse client data. To address this challenge, we propose a novel framework that simultaneously enhances global generalization and local personalization by Rethinking Information Representation in the Federated learning process (FedRIR). Specifically, we introduce Masked Client-Specific Learning (MCSL), which isolates and extracts fine-grained client-specific features tailored to each client's unique data characteristics, thereby enhancing personalization. Concurrently, the Information Distillation Module (IDM) refines the global shared features by filtering out redundant client-specific information, resulting in a purer and more robust global representation that enhances generalization. By integrating the refined global features with the isolated client-specific features, we construct enriched representations that effectively capture both global patterns and local nuances, thereby improving the performance of downstream tasks on the client. The code is available at https://github.com/Deep-Imaging-Group/FedRIR.
GEMeX: A Large-Scale, Groundable, and Explainable Medical VQA Benchmark for Chest X-ray Diagnosis
Nov 25, 2024



Medical Visual Question Answering (VQA) is an essential technology that integrates computer vision and natural language processing to automatically respond to clinical inquiries about medical images. However, current medical VQA datasets exhibit two significant limitations: (1) they often lack visual and textual explanations for answers, which impedes their ability to satisfy the comprehension needs of patients and junior doctors; (2) they typically offer a narrow range of question formats, inadequately reflecting the diverse requirements encountered in clinical scenarios. These limitations pose significant challenges to the development of a reliable and user-friendly Med-VQA system. To address these challenges, we introduce a large-scale, Groundable, and Explainable Medical VQA benchmark for chest X-ray diagnosis (GEMeX), featuring several innovative components: (1) A multi-modal explainability mechanism that offers detailed visual and textual explanations for each question-answer pair, thereby enhancing answer comprehensibility; (2) Four distinct question types, open-ended, closed-ended, single-choice, and multiple-choice, that better reflect diverse clinical needs. We evaluated 10 representative large vision language models on GEMeX and found that they underperformed, highlighting the dataset's complexity. However, after fine-tuning a baseline model using the training set, we observed a significant performance improvement, demonstrating the dataset's effectiveness. The project is available at www.med-vqa.com/GEMeX.
Understanding Layer Significance in LLM Alignment
Oct 23, 2024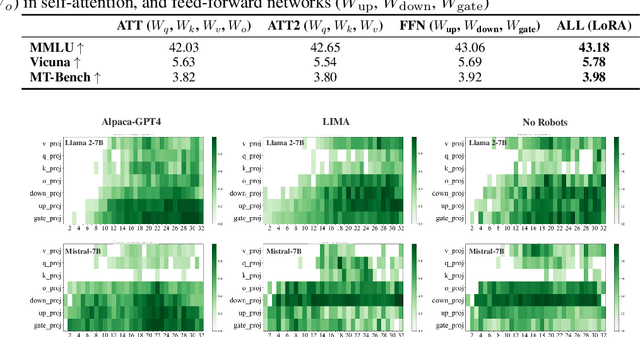
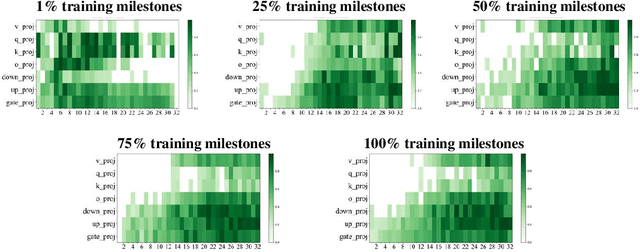


Aligning large language models (LLMs) through fine-tuning is essential for tailoring them to specific applications. Therefore, understanding what LLMs learn during the alignment process is crucial. Recent studies suggest that alignment primarily adjusts a model's presentation style rather than its foundational knowledge, indicating that only certain components of the model are significantly impacted. To delve deeper into LLM alignment, we propose to identify which layers within LLMs are most critical to the alignment process, thereby uncovering how alignment influences model behavior at a granular level. We propose a novel approach to identify the important layers for LLM alignment (ILA). It involves learning a binary mask for each incremental weight matrix in the LoRA algorithm, indicating the significance of each layer. ILA consistently identifies important layers across various alignment datasets, with nearly 90% overlap even with substantial dataset differences, highlighting fundamental patterns in LLM alignment. Experimental results indicate that freezing non-essential layers improves overall model performance, while selectively tuning the most critical layers significantly enhances fine-tuning efficiency with minimal performance loss.
Diversity-grounded Channel Prototypical Learning for Out-of-Distribution Intent Detection
Sep 17, 2024In the realm of task-oriented dialogue systems, a robust intent detection mechanism must effectively handle malformed utterances encountered in real-world scenarios. This study presents a novel fine-tuning framework for large language models (LLMs) aimed at enhancing in-distribution (ID) intent classification and out-of-distribution (OOD) intent detection, which utilizes semantic matching with prototypes derived from ID class names. By harnessing the highly distinguishable representations of LLMs, we construct semantic prototypes for each ID class using a diversity-grounded prompt tuning approach. We rigorously test our framework in a challenging OOD context, where ID and OOD classes are semantically close yet distinct, referred to as \emph{near} OOD detection. For a thorough assessment, we benchmark our method against the prevalent fine-tuning approaches. The experimental findings reveal that our method demonstrates superior performance in both few-shot ID intent classification and near-OOD intent detection tasks.
Continual Dialogue State Tracking via Reason-of-Select Distillation
Aug 19, 2024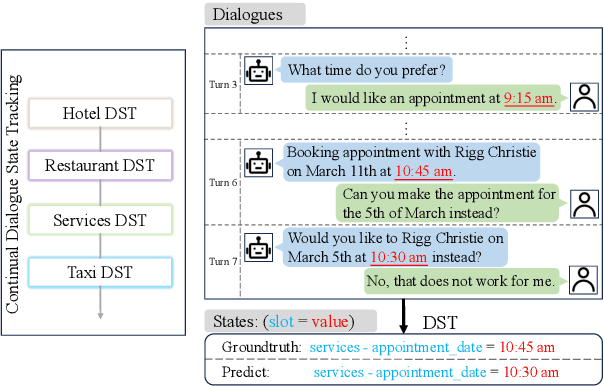

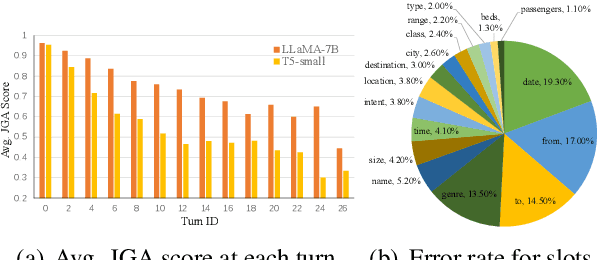
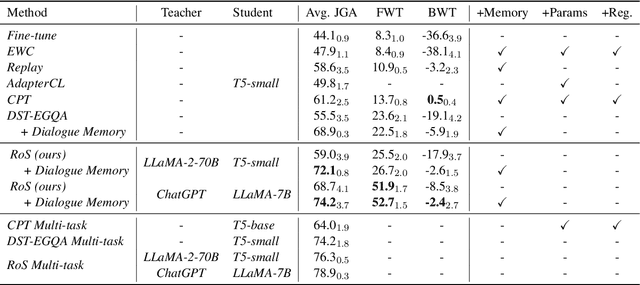
An ideal dialogue system requires continuous skill acquisition and adaptation to new tasks while retaining prior knowledge. Dialogue State Tracking (DST), vital in these systems, often involves learning new services and confronting catastrophic forgetting, along with a critical capability loss termed the "Value Selection Quandary." To address these challenges, we introduce the Reason-of-Select (RoS) distillation method by enhancing smaller models with a novel 'meta-reasoning' capability. Meta-reasoning employs an enhanced multi-domain perspective, combining fragments of meta-knowledge from domain-specific dialogues during continual learning. This transcends traditional single-perspective reasoning. The domain bootstrapping process enhances the model's ability to dissect intricate dialogues from multiple possible values. Its domain-agnostic property aligns data distribution across different domains, effectively mitigating forgetting. Additionally, two novel improvements, "multi-value resolution" strategy and Semantic Contrastive Reasoning Selection method, significantly enhance RoS by generating DST-specific selection chains and mitigating hallucinations in teachers' reasoning, ensuring effective and reliable knowledge transfer. Extensive experiments validate the exceptional performance and robust generalization capabilities of our method. The source code is provided for reproducibility.
MegaFake: A Theory-Driven Dataset of Fake News Generated by Large Language Models
Aug 19, 2024



The advent of large language models (LLMs) has revolutionized online content creation, making it much easier to generate high-quality fake news. This misuse threatens the integrity of our digital environment and ethical standards. Therefore, understanding the motivations and mechanisms behind LLM-generated fake news is crucial. In this study, we analyze the creation of fake news from a social psychology perspective and develop a comprehensive LLM-based theoretical framework, LLM-Fake Theory. We introduce a novel pipeline that automates the generation of fake news using LLMs, thereby eliminating the need for manual annotation. Utilizing this pipeline, we create a theoretically informed Machine-generated Fake news dataset, MegaFake, derived from the GossipCop dataset. We conduct comprehensive analyses to evaluate our MegaFake dataset. We believe that our dataset and insights will provide valuable contributions to future research focused on the detection and governance of fake news in the era of LLMs.
TaSL: Task Skill Localization and Consolidation for Language Model Continual Learning
Aug 09, 2024Language model continual learning (CL) has recently garnered significant interest due to its potential to adapt large language models (LLMs) to dynamic real-world environments without re-training. A key challenge in this field is catastrophic forgetting, where models lose previously acquired knowledge when learning new tasks. Existing methods commonly employ multiple parameter-efficient fine-tuning (PEFT) blocks to acquire task-specific knowledge for each task, but these approaches lack efficiency and overlook the potential for knowledge transfer through task interaction. In this paper, we present a novel CL framework for language models called Task Skill Localization and Consolidation (TaSL), which enhances knowledge transfer without relying on memory replay. TaSL first divides the model into `skill units' based on parameter dependencies, enabling more granular control. It then employs a novel group-wise skill localization technique to identify the importance distribution of skill units for a new task. By comparing this importance distribution with those from previous tasks, we implement a fine-grained skill consolidation strategy that retains task-specific knowledge, thereby preventing forgetting, and updates task-shared knowledge, which facilitates bi-directional knowledge transfer. As a result, TaSL achieves a superior balance between retaining previous knowledge and excelling in new tasks. TaSL also shows strong generalizability, suitable for general models and customizable for PEFT methods like LoRA. Additionally, it demonstrates notable extensibility, allowing integration with memory replay to further enhance performance. Extensive experiments on two CL benchmarks, with varying model sizes (from 220M to 7B), demonstrate the effectiveness of TaSL and its variants across different settings.