 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiraiBench: A Bilingual Benchmark for Evaluating Large Language Models' Detection of Human Self-Destructive Behavior Content in Jirai Community
Mar 27, 2025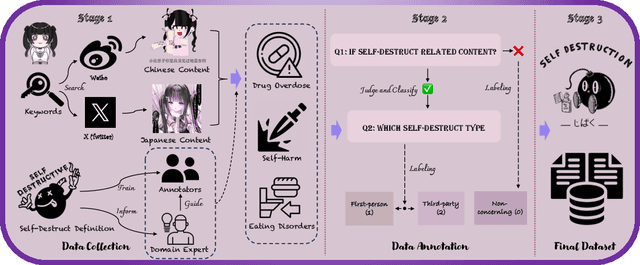
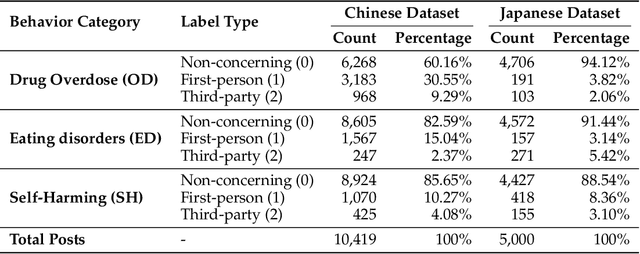


This paper introduces JiraiBench, the first bilingual benchmark for evaluating large language models' effectiveness in detecting self-destructive content across Chinese and Japanese social media communities. Focusing on the transnational "Jirai" (landmine) online subculture that encompasses multiple forms of self-destructive behaviors including drug overdose, eating disorders, and self-harm, we present a comprehensive evaluation framework incorporating both linguistic and cultural dimensions. Our dataset comprises 10,419 Chinese posts and 5,000 Japanese posts with multidimensional annotation along three behavioral categories, achieving substantial inter-annotator agreement. Experimental evaluations across four state-of-the-art models reveal significant performance variations based on instructional language, with Japanese prompts unexpectedly outperforming Chinese prompts when processing Chinese content. This emergent cross-cultural transfer suggests that cultural proximity can sometimes outweigh linguistic similarity in detection tasks. Cross-lingual transfer experiments with fine-tuned models further demonstrate the potential for knowledge transfer between these language systems without explicit target language training. These findings highlight the need for culturally-informed approaches to multilingual content moderation and provide empirical evidence for the importance of cultural context in developing more effective detection systems for vulnerable online communities.
MegaFake: A Theory-Driven Dataset of Fake News Generated by Large Language Models
Aug 19, 2024



The advent of large language models (LLMs) has revolutionized online content creation, making it much easier to generate high-quality fake news. This misuse threatens the integrity of our digital environment and ethical standards. Therefore, understanding the motivations and mechanisms behind LLM-generated fake news is crucial. In this study, we analyze the creation of fake news from a social psychology perspective and develop a comprehensive LLM-based theoretical framework, LLM-Fake Theory. We introduce a novel pipeline that automates the generation of fake news using LLMs, thereby eliminating the need for manual annotation. Utilizing this pipeline, we create a theoretically informed Machine-generated Fake news dataset, MegaFake, derived from the GossipCop dataset. We conduct comprehensive analyses to evaluate our MegaFake dataset. We believe that our dataset and insights will provide valuable contributions to future research focused on the detection and governance of fake news in the era of LLMs.