 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelowlightSplat: Feed-Forward Gaussian Splatting for Lowlight 3D Scene Reconstruction
May 26, 2026Novel-view synthesis and 3D reconstruction from sparse posed images are central to robotics and AR/VR. Yet, feed-forward 3D Gaussian reconstruction fails under lowlight due to noise, color shifts, and unreliable correspondence. We propose DelowlightSplat, a lowlight-aware feed-forward Gaussian splatting framework for clean novel-view rendering. We build a controllable multi-view lowlight benchmark by degrading only context views while keeping target views clean. We introduce a lightweight Lowlight Adapter for residual enhancement to improve matchability, and couple it with cost-volume-based multi-view inference to directly predict clean 3D Gaussians. Experiments show that DelowlightSplat significantly outperforms previous feed-forward method and two-stage pipeline under lowlight conditions.
SOMA: Strategic Orchestration and Memory-Augmented System for Vision-Language-Action Model Robustness via In-Context Adaptation
Mar 25, 2026Despite the promise of Vision-Language-Action (VLA) models as generalist robotic controllers, their robustness against perceptual noise and environmental variations in out-of-distribution (OOD) tasks remains fundamentally limited by the absence of long-term memory, causal failure attribution, and dynamic intervention capability. To address this, we propose SOMA, a Strategic Orchestration and Memory-Augmented System that upgrades frozen VLA policies for robust in-context adaptation without parameter fine-tuning. Specifically, SOMA operates through an online pipeline of contrastive Dual-Memory Retrieval-Augmented Generation (RAG), an Attribution-Driven Large-Language-Model (LLM) Orchestrator, and extensible Model Context Protocol (MCP) interventions, while an offline Memory Consolidation module continuously distills the execution traces into reliable priors. Experimental evaluations across three backbone models (pi0, pi0.5, and SmolVLA) on LIBERO-PRO and our proposed LIBERO-SOMA benchmarks demonstrate that SOMA achieves an average absolute success rate gain of 56.6%. This includes a significant absolute improvement of 89.1% in long-horizon task chaining. Project page and source code are available at: https://github.com/LZY-1021/SOMA.
PowerFlow: Unlocking the Dual Nature of LLMs via Principled Distribution Matching
Mar 19, 2026Unsupervised Reinforcement Learning from Internal Feedback (RLIF) has emerged as a promising paradigm for eliciting the latent capabilities of Large Language Models (LLMs) without external supervision. However, current methods rely on heuristic intrinsic rewards, which often lack a well-defined theoretical optimization target and are prone to degenerative biases. In this work, we introduce PowerFlow, a principled framework that reformulates unsupervised fine-tuning as a distribution matching problem. By casting GFlowNet as an amortized variational sampler for unnormalized densities, we propose a length-aware Trajectory-Balance objective that explicitly neutralizes the structural length biases inherent in autoregressive generation. By targeting $α$-power distributions, PowerFlow enables the directional elicitation of the dual nature of LLMs: sharpening the distribution ($α> 1$) to intensify logical reasoning, or flattening it ($α< 1$) to unlock expressive creativity. Extensive experiments demonstrate that PowerFlow consistently outperforms existing RLIF methods, matching or even exceeding supervised GRPO. Furthermore, by mitigating over-sharpening in aligned models, our approach achieves simultaneous gains in diversity and quality, shifting the Pareto frontier in creative tasks.
DenoiseSplat: Feed-Forward Gaussian Splatting for Noisy 3D Scene Reconstruction
Mar 10, 20263D scene reconstruction and novel-view synthesis are fundamental for VR, robotics, and content creation. However, most NeRF and 3D Gaussian Splatting pipelines assume clean inputs and degrade under real noise and artifacts. We therefore propose DenoiseSplat, a feed-forward 3D Gaussian splatting method for noisy multi-view images. We build a large-scale, scene-consistent noisy--clean benchmark on RE10K by injecting Gaussian, Poisson, speckle, and salt-and-pepper noise with controlled intensities. With a lightweight MVSplat-style feed-forward backbone, we train end-to-end using only clean 2D renderings as supervision and no 3D ground truth. On noisy RE10K, DenoiseSplat outperforms vanilla MVSplat and a strong two-stage baseline (IDF + MVSplat) in PSNR/SSIM and LPIPS across noise types and levels.
NanoNet: Parameter-Efficient Learning with Label-Scarce Supervision for Lightweight Text Mining Model
Feb 05, 2026The lightweight semi-supervised learning (LSL) strategy provides an effective approach of conserving labeled samples and minimizing model inference costs. Prior research has effectively applied knowledge transfer learning and co-training regularization from large to small models in LSL. However, such training strategies are computationally intensive and prone to local optima, thereby increasing the difficulty of finding the optimal solution. This has prompted us to investigate the feasibility of integrating three low-cost scenarios for text mining tasks: limited labeled supervision, lightweight fine-tuning, and rapid-inference small models. We propose NanoNet, a novel framework for lightweight text mining that implements parameter-efficient learning with limited supervision. It employs online knowledge distillation to generate multiple small models and enhances their performance through mutual learning regularization. The entire process leverages parameter-efficient learning, reducing training costs and minimizing supervision requirements, ultimately yielding a lightweight model for downstream inference.
Reparameterization Flow Policy Optimization
Feb 03, 2026Reparameterization Policy Gradient (RPG) has emerged as a powerful paradigm for model-based reinforcement learning, enabling high sample efficiency by backpropagating gradients through differentiable dynamics. However, prior RPG approaches have been predominantly restricted to Gaussian policies, limiting their performance and failing to leverage recent advances in generative models. In this work, we identify that flow policies, which generate actions via differentiable ODE integration, naturally align with the RPG framework, a connection not established in prior work. However, naively exploiting this synergy proves ineffective, often suffering from training instability and a lack of exploration. We propose Reparameterization Flow Policy Optimization (RFO). RFO computes policy gradients by backpropagating jointly through the flow generation process and system dynamics, unlocking high sample efficiency without requiring intractable log-likelihood calculations. RFO includes two tailored regularization terms for stability and exploration. We also propose a variant of RFO with action chunking. Extensive experiments on diverse locomotion and manipulation tasks, involving both rigid and soft bodies with state or visual inputs, demonstrate the effectiveness of RFO. Notably, on a challenging locomotion task controlling a soft-body quadruped, RFO achieves almost $2\times$ the reward of the state-of-the-art baseline.
Outcome-Grounded Advantage Reshaping for Fine-Grained Credit Assignment in Mathematical Reasoning
Jan 12, 2026Group Relative Policy Optimization (GRPO) has emerged as a promising critic-free reinforcement learning paradigm for reasoning tasks. However, standard GRPO employs a coarse-grained credit assignment mechanism that propagates group-level rewards uniformly to to every token in a sequence, neglecting the varying contribution of individual reasoning steps. We address this limitation by introducing Outcome-grounded Advantage Reshaping (OAR), a fine-grained credit assignment mechanism that redistributes advantages based on how much each token influences the model's final answer. We instantiate OAR via two complementary strategies: (1) OAR-P, which estimates outcome sensitivity through counterfactual token perturbations, serving as a high-fidelity attribution signal; (2) OAR-G, which uses an input-gradient sensitivity proxy to approximate the influence signal with a single backward pass. These importance signals are integrated with a conservative Bi-Level advantage reshaping scheme that suppresses low-impact tokens and boosts pivotal ones while preserving the overall advantage mass. Empirical results on extensive mathematical reasoning benchmarks demonstrate that while OAR-P sets the performance upper bound, OAR-G achieves comparable gains with negligible computational overhead, both significantly outperforming a strong GRPO baseline, pushing the boundaries of critic-free LLM reasoning.
Scoring, Reasoning, and Selecting the Best! Ensembling Large Language Models via a Peer-Review Process
Dec 29, 2025We propose LLM-PeerReview, an unsupervised LLM Ensemble method that selects the most ideal response from multiple LLM-generated candidates for each query, harnessing the collective wisdom of multiple models with diverse strengths. LLM-PeerReview is built on a novel, peer-review-inspired framework that offers a clear and interpretable mechanism, while remaining fully unsupervised for flexible adaptability and generalization. Specifically, it operates in three stages: For scoring, we use the emerging LLM-as-a-Judge technique to evaluate each response by reusing multiple LLMs at hand; For reasoning, we can apply a principled graphical model-based truth inference algorithm or a straightforward averaging strategy to aggregate multiple scores to produce a final score for each response; Finally, the highest-scoring response is selected as the best ensemble output. LLM-PeerReview is conceptually simple and empirically powerful. The two variants of the proposed approach obtain strong results across four datasets, including outperforming the recent advanced model Smoothie-Global by 6.9% and 7.3% points, respectively.
Large Model Enabled Embodied Intelligence for 6G Integrated Perception, Communication, and Computation Network
Dec 22, 2025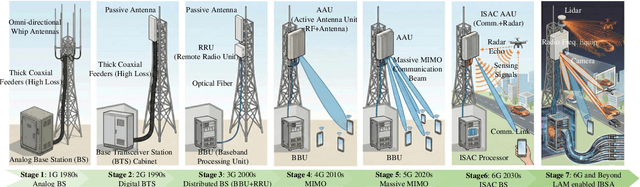

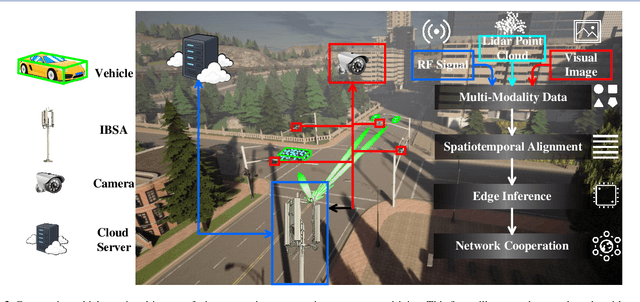
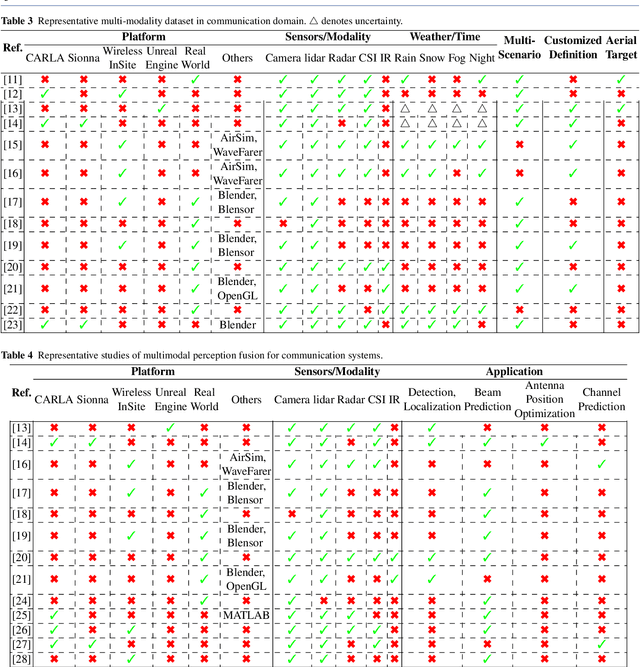
The advent of sixth-generation (6G) places intelligence at the core of wireless architecture, fusing perception, communication, and computation into a single closed-loop. This paper argues that large artificial intelligence models (LAMs) can endow base stations with perception, reasoning, and acting capabilities, thus transforming them into intelligent base station agents (IBSAs). We first review the historical evolution of BSs from single-functional analog infrastructure to distributed, software-defined, and finally LAM-empowered IBSA, highlighting the accompanying changes in architecture, hardware platforms, and deployment. We then present an IBSA architecture that couples a perception-cognition-execution pipeline with cloud-edge-end collaboration and parameter-efficient adaptation. Subsequently,we study two representative scenarios: (i) cooperative vehicle-road perception for autonomous driving, and (ii) ubiquitous base station support for low-altitude uncrewed aerial vehicle safety monitoring and response against unauthorized drones. On this basis, we analyze key enabling technologies spanning LAM design and training, efficient edge-cloud inference, multi-modal perception and actuation, as well as trustworthy security and governance. We further propose a holistic evaluation framework and benchmark considerations that jointly cover communication performance, perception accuracy, decision-making reliability, safety, and energy efficiency. Finally, we distill open challenges on benchmarks, continual adaptation, trustworthy decision-making, and standardization. Together, this work positions LAM-enabled IBSAs as a practical path toward integrated perception, communication, and computation native, safety-critical 6G systems.
Chirp Delay-Doppler Domain Modulation Based Joint Communication and Radar for Autonomous Vehicles
Dec 20, 2025This paper introduces a sensing-centric joint communication and millimeter-wave radar paradigm to facilitate collaboration among intelligent vehicles. We first propose a chirp waveform-based delay-Doppler quadrature amplitude modulation (DD-QAM) that modulates data across delay, Doppler, and amplitude dimensions. Building upon this modulation scheme, we derive its achievable rate to quantify the communication performance. We then introduce an extended Kalman filter-based scheme for four-dimensional (4D) parameter estimation in dynamic environments, enabling the active vehicles to accurately estimate orientation and tangential-velocity beyond traditional 4D radar systems. Furthermore, in terms of communication, we propose a dual-compensation-based demodulation and tracking scheme that allows the passive vehicles to effectively demodulate data without compromising their sensing functions. Simulation results underscore the feasibility and superior performance of our proposed methods, marking a significant advancement in the field of autonomous vehicles. Simulation codes are provided to reproduce the results in this paper: \href{https://github.com/LiZhuoRan0/2026-IEEE-TWC-ChirpDelayDopplerModulationISAC}{https://github.com/LiZhuoRan0}.