 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReparameterization Flow Policy Optimization
Feb 03, 2026Reparameterization Policy Gradient (RPG) has emerged as a powerful paradigm for model-based reinforcement learning, enabling high sample efficiency by backpropagating gradients through differentiable dynamics. However, prior RPG approaches have been predominantly restricted to Gaussian policies, limiting their performance and failing to leverage recent advances in generative models. In this work, we identify that flow policies, which generate actions via differentiable ODE integration, naturally align with the RPG framework, a connection not established in prior work. However, naively exploiting this synergy proves ineffective, often suffering from training instability and a lack of exploration. We propose Reparameterization Flow Policy Optimization (RFO). RFO computes policy gradients by backpropagating jointly through the flow generation process and system dynamics, unlocking high sample efficiency without requiring intractable log-likelihood calculations. RFO includes two tailored regularization terms for stability and exploration. We also propose a variant of RFO with action chunking. Extensive experiments on diverse locomotion and manipulation tasks, involving both rigid and soft bodies with state or visual inputs, demonstrate the effectiveness of RFO. Notably, on a challenging locomotion task controlling a soft-body quadruped, RFO achieves almost $2\times$ the reward of the state-of-the-art baseline.
OM2P: Offline Multi-Agent Mean-Flow Policy
Aug 08, 2025Generative models, especially diffusion and flow-based models, have been promising in offline multi-agent reinforcement learning. However, integrating powerful generative models into this framework poses unique challenges. In particular, diffusion and flow-based policies suffer from low sampling efficiency due to their iterative generation processes, making them impractical in time-sensitive or resource-constrained settings. To tackle these difficulties, we propose OM2P (Offline Multi-Agent Mean-Flow Policy), a novel offline MARL algorithm to achieve efficient one-step action sampling. To address the misalignment between generative objectives and reward maximization, we introduce a reward-aware optimization scheme that integrates a carefully-designed mean-flow matching loss with Q-function supervision. Additionally, we design a generalized timestep distribution and a derivative-free estimation strategy to reduce memory overhead and improve training stability. Empirical evaluations on Multi-Agent Particle and MuJoCo benchmarks demonstrate that OM2P achieves superior performance, with up to a 3.8x reduction in GPU memory usage and up to a 10.8x speed-up in training time. Our approach represents the first to successfully integrate mean-flow model into offline MARL, paving the way for practical and scalable generative policies in cooperative multi-agent settings.
Reparameterization Proximal Policy Optimization
Aug 08, 2025



Reparameterization policy gradient (RPG) is promising for improving sample efficiency by leveraging differentiable dynamics. However, a critical barrier is its training instability, where high-variance gradients can destabilize the learning process. To address this, we draw inspiration from Proximal Policy Optimization (PPO), which uses a surrogate objective to enable stable sample reuse in the model-free setting. We first establish a connection between this surrogate objective and RPG, which has been largely unexplored and is non-trivial. Then, we bridge this gap by demonstrating that the reparameterization gradient of a PPO-like surrogate objective can be computed efficiently using backpropagation through time. Based on this key insight, we propose Reparameterization Proximal Policy Optimization (RPO), a stable and sample-efficient RPG-based method. RPO enables multiple epochs of stable sample reuse by optimizing a clipped surrogate objective tailored for RPG, while being further stabilized by Kullback-Leibler (KL) divergence regularization and remaining fully compatible with existing variance reduction methods. We evaluate RPO on a suite of challenging locomotion and manipulation tasks, where experiments demonstrate that our method achieves superior sample efficiency and strong performance.
SCFANet: Style Distribution Constraint Feature Alignment Network For Pathological Staining Translation
Apr 01, 2025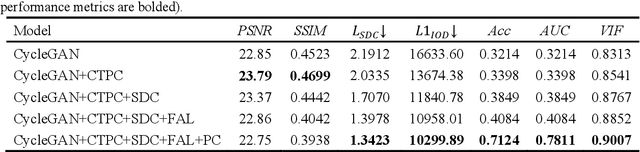



Immunohistochemical (IHC) staining serves as a valuable technique for detecting specific antigens or proteins through antibody-mediated visualization. However, the IHC staining process is both time-consuming and costly. To address these limitations, the application of deep learning models for direct translation of cost-effective Hematoxylin and Eosin (H&E) stained images into IHC stained images has emerged as an efficient solution. Nevertheless, the conversion from H&E to IHC images presents significant challenges, primarily due to alignment discrepancies between image pairs and the inherent diversity in IHC staining style patterns. To overcome these challenges, we propose the Style Distribution Constraint Feature Alignment Network (SCFANet), which incorporates two innovative modules: the Style Distribution Constrainer (SDC) and Feature Alignment Learning (FAL). The SDC ensures consistency between the generated and target images' style distributions while integrating cycle consistency loss to maintain structural consistency. To mitigate the complexity of direct image-to-image translation, the FAL module decomposes the end-to-end translation task into two subtasks: image reconstruction and feature alignment. Furthermore, we ensure pathological consistency between generated and target images by maintaining pathological pattern consistency and Optical Density (OD) uniformity. Extensive experiments conducted on the Breast Cancer Immunohistochemical (BCI) dataset demonstrate that our SCFANet model outperforms existing methods, achieving precise transformation of H&E-stained images into their IHC-stained counterparts. The proposed approach not only addresses the technical challenges in H&E to IHC image translation but also provides a robust framework for accurate and efficient stain conversion in pathological analysis.
Few is More: Task-Efficient Skill-Discovery for Multi-Task Offline Multi-Agent Reinforcement Learning
Feb 13, 2025As a data-driven approach, offline MARL learns superior policies solely from offline datasets, ideal for domains rich in historical data but with high interaction costs and risks. However, most existing methods are task-specific, requiring retraining for new tasks, leading to redundancy and inefficiency. To address this issue, in this paper, we propose a task-efficient multi-task offline MARL algorithm, Skill-Discovery Conservative Q-Learning (SD-CQL). Unlike existing offline skill-discovery methods, SD-CQL discovers skills by reconstructing the next observation. It then evaluates fixed and variable actions separately and employs behavior-regularized conservative Q-learning to execute the optimal action for each skill. This approach eliminates the need for local-global alignment and enables strong multi-task generalization from limited small-scale source tasks. Substantial experiments on StarCraftII demonstrates the superior generalization performance and task-efficiency of SD-CQL. It achieves the best performance on $\textbf{10}$ out of $14$ task sets, with up to $\textbf{65%}$ improvement on individual task sets, and is within $4\%$ of the best baseline on the remaining four.
Offline-to-Online Multi-Agent Reinforcement Learning with Offline Value Function Memory and Sequential Exploration
Oct 25, 2024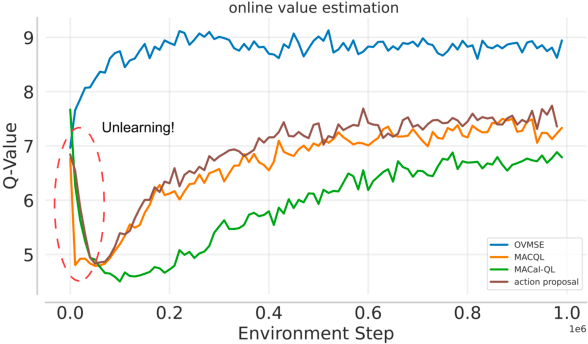
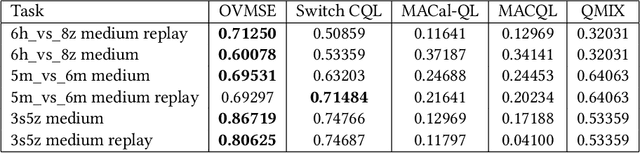
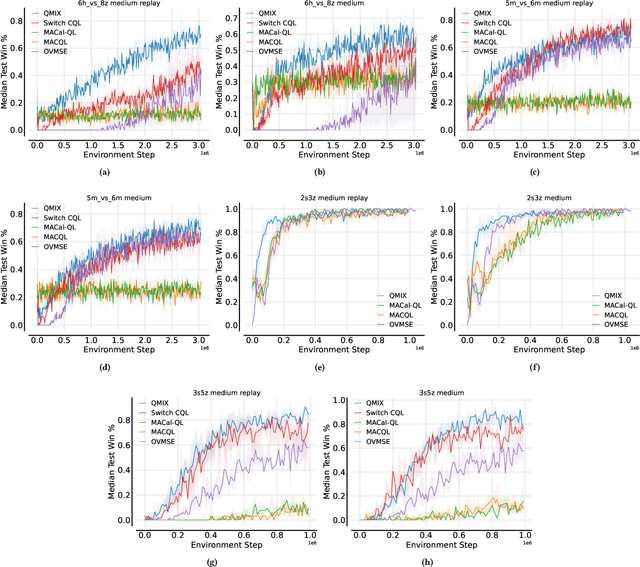
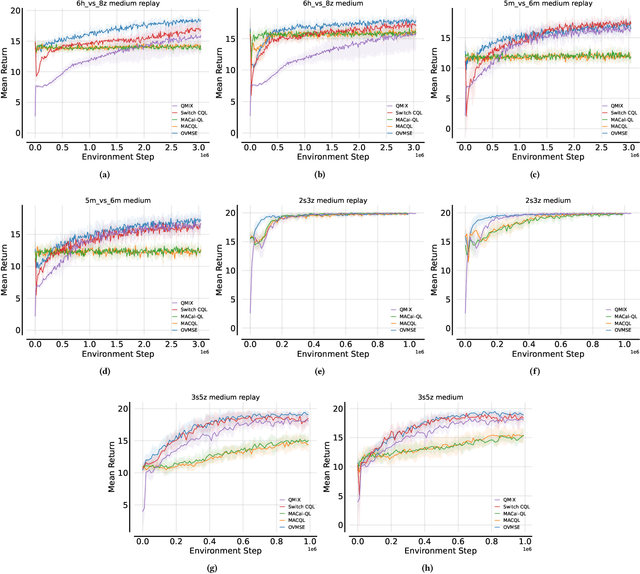
Offline-to-Online Reinforcement Learning has emerged as a powerful paradigm, leveraging offline data for initialization and online fine-tuning to enhance both sample efficiency and performance. However, most existing research has focused on single-agent settings, with limited exploration of the multi-agent extension, i.e., Offline-to-Online Multi-Agent Reinforcement Learning (O2O MARL). In O2O MARL, two critical challenges become more prominent as the number of agents increases: (i) the risk of unlearning pre-trained Q-values due to distributional shifts during the transition from offline-to-online phases, and (ii) the difficulty of efficient exploration in the large joint state-action space. To tackle these challenges, we propose a novel O2O MARL framework called Offline Value Function Memory with Sequential Exploration (OVMSE). First, we introduce the Offline Value Function Memory (OVM) mechanism to compute target Q-values, preserving knowledge gained during offline training, ensuring smoother transitions, and enabling efficient fine-tuning. Second, we propose a decentralized Sequential Exploration (SE) strategy tailored for O2O MARL, which effectively utilizes the pre-trained offline policy for exploration, thereby significantly reducing the joint state-action space to be explored. Extensive experiments on the StarCraft Multi-Agent Challenge (SMAC) demonstrate that OVMSE significantly outperforms existing baselines, achieving superior sample efficiency and overall performance.
Chance-Constrained Iterative Linear-Quadratic Stochastic Games
Mar 02, 2022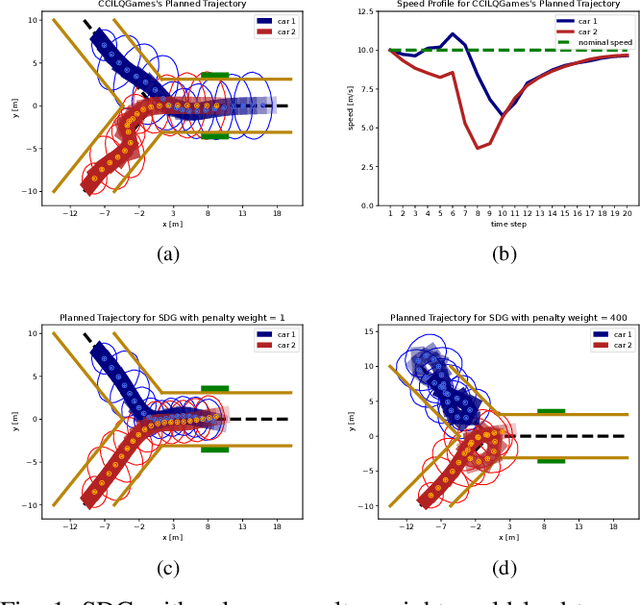
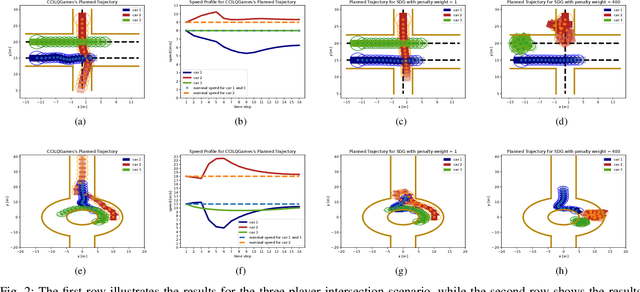
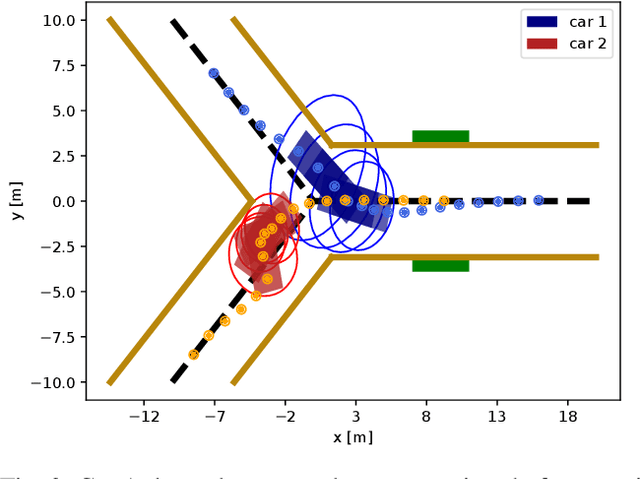

Dynamic game arises as a powerful paradigm for multi-robot planning, for which the safety constraints satisfaction is crucial. Constrained stochastic games are of particular interest, as real-world robots need to operate and satisfy constraints under uncertainty. Existing methods for solving stochastic games handle constraints using soft penalties with hand-tuned weights. However, finding a suitable penalty weight is non-trivial and requires trial and error. In this paper, we propose the chance-constrained iterative linear-quadratic stochastic games (CCILQGames) algorithm. CCILQGames solves chance-constrained stochastic games using the augmented Lagrangian method, with the merit of automatically finding a suitable penalty weight. We evaluate our algorithm in three autonomous driving scenarios, including merge, intersection, and roundabout. Experimental results and Monte Carlo tests show that CCILQGames could generate safe and interactive strategies in stochastic environments.